UniRL-Zero: Reinforcement Learning on Unified Models with Joint Language Model and Diffusion Model Experts
作者: Fu-Yun Wang, Han Zhang, Michael Gharbi, Hongsheng Li, Taesung Park
分类: cs.LG, cs.AI
发布日期: 2025-10-20
🔗 代码/项目: GITHUB
💡 一句话要点
UniRL-Zero:提出融合语言模型和扩散模型专家的统一强化学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 统一模型 多模态学习 语言模型 扩散模型 多模态交互 基线模型
📋 核心要点
- 现有统一模型在多模态理解和生成方面存在交互能力不足的挑战,难以充分利用不同模态的优势。
- UniRL-Zero 提出融合语言模型和扩散模型专家,通过强化学习提升统一模型在多模态任务中的表现。
- 该工作定义了六个统一模型强化学习场景,并提供了相应的基线,为后续研究奠定了基础。
📝 摘要(中文)
UniRL-Zero 提出了一个统一的强化学习(RL)框架,旨在增强统一模型中的多模态语言模型理解和推理能力、扩散模型多媒体生成能力以及它们之间的有益交互能力。该工作定义了统一模型强化学习的六个场景,并为统一理解和生成模型的强化学习提供了系统的基线。
🔬 方法详解
问题定义:论文旨在解决统一模型在多模态理解、推理和生成任务中,不同模态之间交互能力不足的问题。现有方法难以有效融合语言模型和扩散模型的优势,导致模型在复杂场景下的表现受限。
核心思路:论文的核心思路是利用强化学习(RL)来优化统一模型,使其能够更好地利用语言模型和扩散模型的能力。通过定义合适的奖励函数,引导模型学习如何有效地进行多模态交互,从而提升整体性能。
技术框架:UniRL-Zero 的整体框架包含一个统一模型,该模型同时具备语言理解和多媒体生成能力。框架的关键在于使用强化学习算法来训练该模型,使其能够根据环境反馈调整自身的行为。具体流程包括:1) 定义环境和状态空间;2) 设计奖励函数,鼓励模型完成特定任务;3) 使用 RL 算法(例如,策略梯度或 Q-learning)训练模型;4) 评估模型在不同场景下的表现。
关键创新:该论文的关键创新在于提出了一个统一的强化学习框架,能够同时优化语言模型和扩散模型,并促进它们之间的有效交互。此外,论文还定义了六个具体的统一模型强化学习场景,为该领域的研究提供了标准化的基准。
关键设计:论文的关键设计包括:1) 针对不同场景设计了特定的奖励函数,以引导模型学习期望的行为;2) 采用了合适的强化学习算法,例如,策略梯度或 Q-learning,来训练模型;3) 对模型结构进行了优化,使其能够更好地处理多模态输入和输出。
🖼️ 关键图片

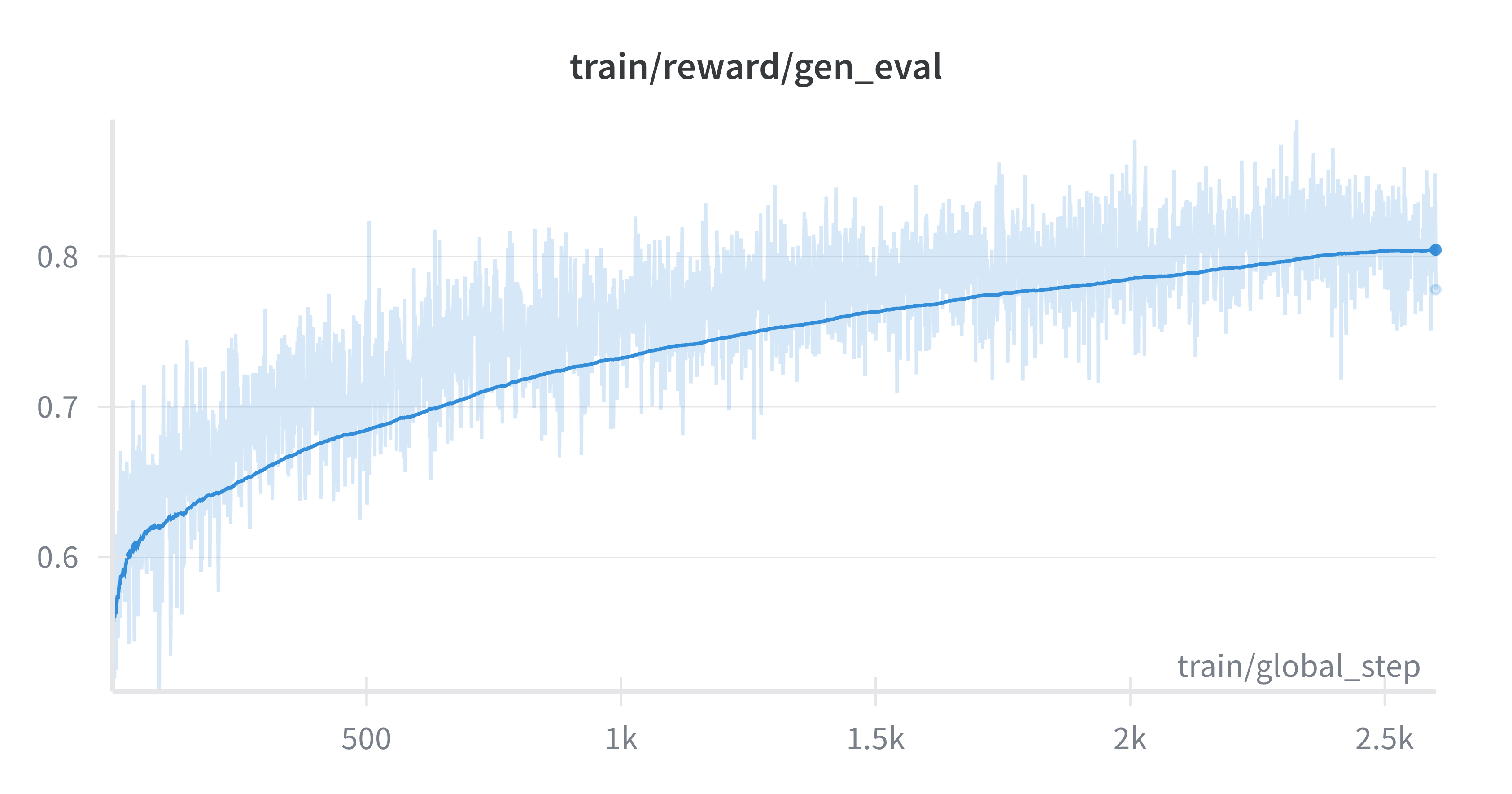
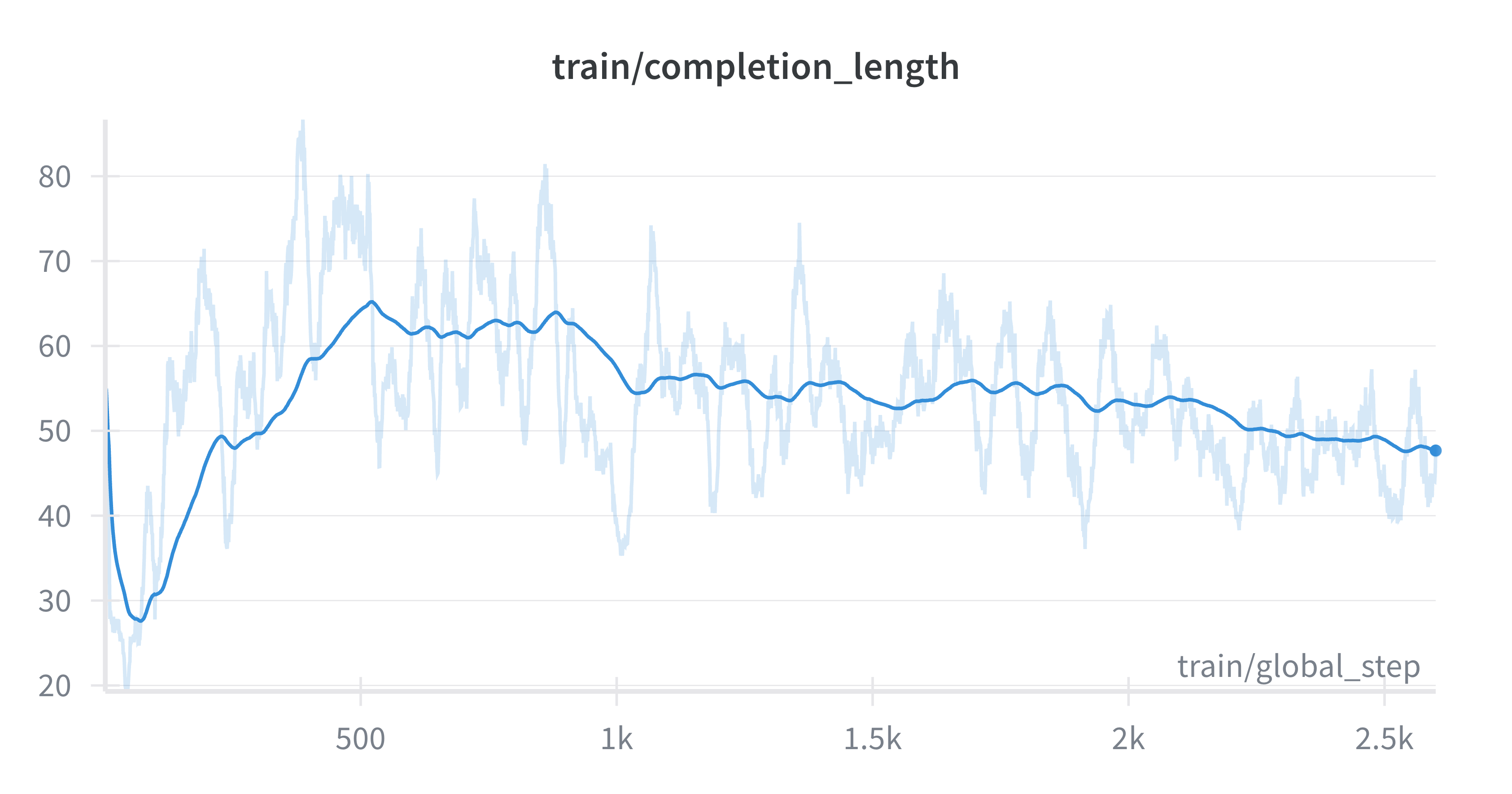
📊 实验亮点
UniRL-Zero 提出了六个统一模型强化学习场景,并为每个场景提供了基线结果。虽然摘要中没有明确给出具体的性能数据和提升幅度,但该工作为后续研究提供了一个标准化的评估框架,方便研究者比较不同方法的优劣。
🎯 应用场景
UniRL-Zero 有潜力应用于各种多模态任务,例如:智能对话系统、图像描述生成、视频内容创作等。通过提升模型的多模态理解和生成能力,可以实现更自然、更智能的人机交互,并为内容创作提供更强大的工具。未来,该技术有望在教育、娱乐、医疗等领域发挥重要作用。
📄 摘要(原文)
We present UniRL-Zero, a unified reinforcement learning (RL) framework that boosts, multimodal language model understanding and reasoning, diffusion model multimedia generation, and their beneficial interaction capabilities within a unified model. Our work defines six scenarios for unified model reinforcement learning, providing systematic baselines for reinforcement learning of unified understanding and generation model. Our code is available at https://github.com/G-U-N/UniRL.