Rewarding the Journey, Not Just the Destination: A Composite Path and Answer Self-Scoring Reward Mechanism for Test-Time Reinforcement Learning
作者: Jingyu Xing, Chenwei Tang, Xinyu Liu, Deng Xiong, Shudong Huang, Wei Ju, Jiancheng Lv, Ziyue Qiao
分类: cs.LG, cs.AI
发布日期: 2025-10-20 (更新: 2025-12-09)
💡 一句话要点
提出COMPASS,解决无监督测试时强化学习中LLM奖励估计难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 无监督学习 奖励机制 测试时强化学习
📋 核心要点
- 现有强化学习方法依赖人工标注数据进行奖励建模,面临可扩展性瓶颈,限制了大型语言模型的发展。
- COMPASS通过双重校准答案奖励和决定性路径奖励,在无监督条件下实现可靠的奖励估计,提升模型推理能力。
- 实验结果表明,COMPASS在多种推理任务和模型架构上均取得了显著且一致的性能提升。
📝 摘要(中文)
强化学习(RL)已成为提升大型语言模型(LLM)的强大范例,在数学和代码生成等复杂推理领域取得了显著的性能。然而,当前的RL方法由于严重依赖人工标注的偏好数据或标记数据集进行奖励建模,面临着根本的可扩展性瓶颈。为了克服这一限制,我们探索在无标签数据上的RL,模型从连续的经验流中自主学习。这种设置中的核心挑战在于在没有ground-truth监督的情况下进行可靠的奖励估计。现有的方法,如Test-Time RL,通过自我一致性共识来解决这个问题,但存在强化从多数投票中获得的错误伪标签的风险。我们引入了COMPASS(复合路径和答案自评分),一种在没有外部监督下运行的新型测试时奖励机制。COMPASS集成了两个互补的组件:双重校准答案奖励(DCAR),通过置信度和可信度校准建立可信的伪标签,从而稳定训练;以及决定性路径奖励(DPR),直接优化推理过程的质量,而不仅仅是结果监督。通过共同强化可信的共识答案和高度决定性的推理链,COMPASS系统地增强了模型的分析能力。广泛的实验表明,COMPASS在不同的推理任务和模型架构上实现了显著且一致的性能提升,为LLM从连续经验中学习提供了一个更具可扩展性的方向。
🔬 方法详解
问题定义:论文旨在解决在无监督的测试时强化学习(Test-Time RL)中,如何为大型语言模型(LLM)提供可靠的奖励信号的问题。现有方法,如基于自我一致性共识的方法,容易受到错误伪标签的影响,导致模型学习到错误的推理模式。因此,如何在没有人工标注的情况下,准确评估LLM的推理过程和结果,是本研究要解决的核心问题。
核心思路:COMPASS的核心思路是通过结合答案的置信度和推理路径的质量,来构建更可靠的奖励信号。具体来说,它包含两个互补的组件:双重校准答案奖励(DCAR)用于评估答案的正确性,决定性路径奖励(DPR)用于评估推理过程的质量。通过同时优化答案和推理路径,COMPASS能够更有效地引导LLM学习正确的推理策略。
技术框架:COMPASS的整体框架包括以下几个主要步骤:1) LLM生成多个答案和对应的推理路径;2) DCAR评估每个答案的置信度和可信度,生成答案奖励;3) DPR评估每个推理路径的决定性,生成路径奖励;4) 将答案奖励和路径奖励结合起来,作为最终的奖励信号,用于更新LLM的策略。
关键创新:COMPASS的关键创新在于提出了双重校准答案奖励(DCAR)和决定性路径奖励(DPR)这两个互补的奖励机制。DCAR通过置信度和可信度校准,能够更准确地评估答案的正确性,避免了错误伪标签的影响。DPR则直接优化推理过程的质量,而不仅仅是结果,从而能够更有效地引导LLM学习正确的推理策略。与现有方法相比,COMPASS能够更有效地利用无标签数据,提升LLM的推理能力。
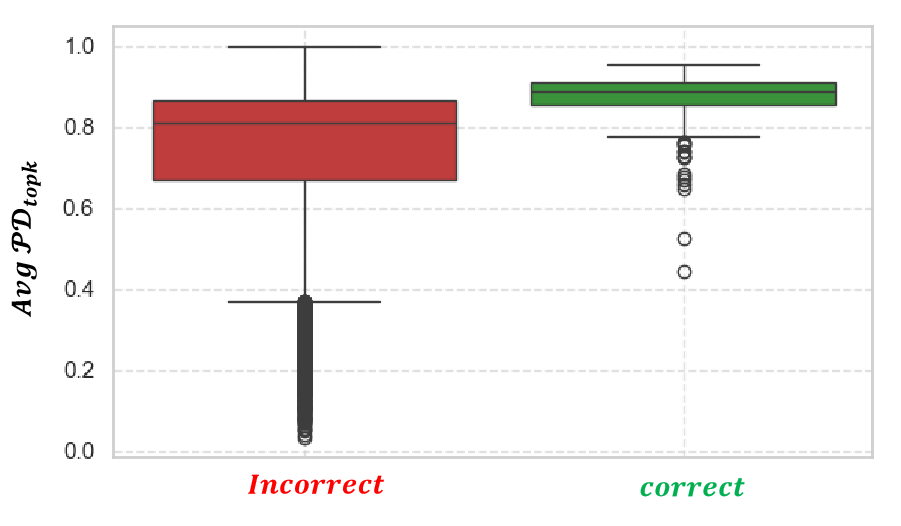
关键设计:DCAR的关键设计在于使用两个校准函数,分别校准答案的置信度和可信度。置信度校准用于评估答案本身的可信程度,可信度校准则用于评估生成该答案的模型的可信程度。DPR的关键设计在于使用一个决定性度量来评估推理路径的质量。该度量考虑了推理步骤的数量、每一步的逻辑强度等因素。最终的奖励信号是DCAR和DPR的加权和,权重可以通过实验进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,COMPASS在多个推理任务上取得了显著的性能提升。例如,在GSM8K数据集上,COMPASS相比于基线方法提升了5%的准确率。此外,COMPASS在不同的模型架构上都表现出了良好的泛化能力,证明了其有效性和鲁棒性。这些结果表明,COMPASS是一种有效的无监督测试时强化学习方法,能够显著提升大型语言模型的推理能力。
🎯 应用场景
COMPASS具有广泛的应用前景,可以应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。该研究成果有助于降低对人工标注数据的依赖,推动大型语言模型在更多领域的应用。未来,COMPASS可以进一步扩展到其他类型的任务和模型,例如多模态推理、对话生成等。
📄 摘要(原文)
Reinforcement Learning (RL) has emerged as a powerful paradigm for advancing Large Language Models (LLMs), achieving remarkable performance in complex reasoning domains such as mathematics and code generation. However, current RL methods face a fundamental scalability bottleneck due to their heavy reliance on human-curated preference data or labeled datasets for reward modeling. To overcome this limitation, we explore RL on unlabeled data where models learn autonomously from continuous experience streams. The core challenge in this setting lies in reliable reward estimation without ground-truth supervision. Existing approaches like Test-Time RL address this through self-consistent consensus, but risk reinforcing incorrect pseudo-labels derived from majority voting. We introduce COMPASS (Composite Path and Answer Self-Scoring), a novel test-time reward mechanism that operates without external supervision. COMPASS integrates two complementary components: the Dual-Calibration Answer Reward (DCAR), which stabilizes training by establishing trustworthy pseudo-labels through confidence and credibility calibration, and the Decisive Path Reward (DPR), which directly optimizes the reasoning process quality beyond mere outcome supervision. By jointly reinforcing trustworthy consensus answers and highly decisive reasoning chains, the COMPASS systematically enhances the model's analytical capabilities. Extensive experiments show that COMPASS achieves significant and consistent performance gains across diverse reasoning tasks and model architectures, advancing a more scalable direction for LLMs to learn from continuous experience.