Unbiased Gradient Low-Rank Projection
作者: Rui Pan, Yang Luo, Yuxing Liu, Yang You, Tong Zhang
分类: cs.LG, cs.AI, math.OC
发布日期: 2025-10-20
💡 一句话要点
提出GUM:一种基于层采样和Muon算法的无偏梯度低秩投影优化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低秩优化 梯度投影 无偏估计 层采样 Muon算法 内存效率
📋 核心要点
- 现有梯度低秩投影方法在优化大型语言模型时存在偏差,导致收敛性差和性能下降。
- 论文提出一种基于层采样的无偏低秩优化方法GUM,结合GaLore和Muon算法,减少偏差。
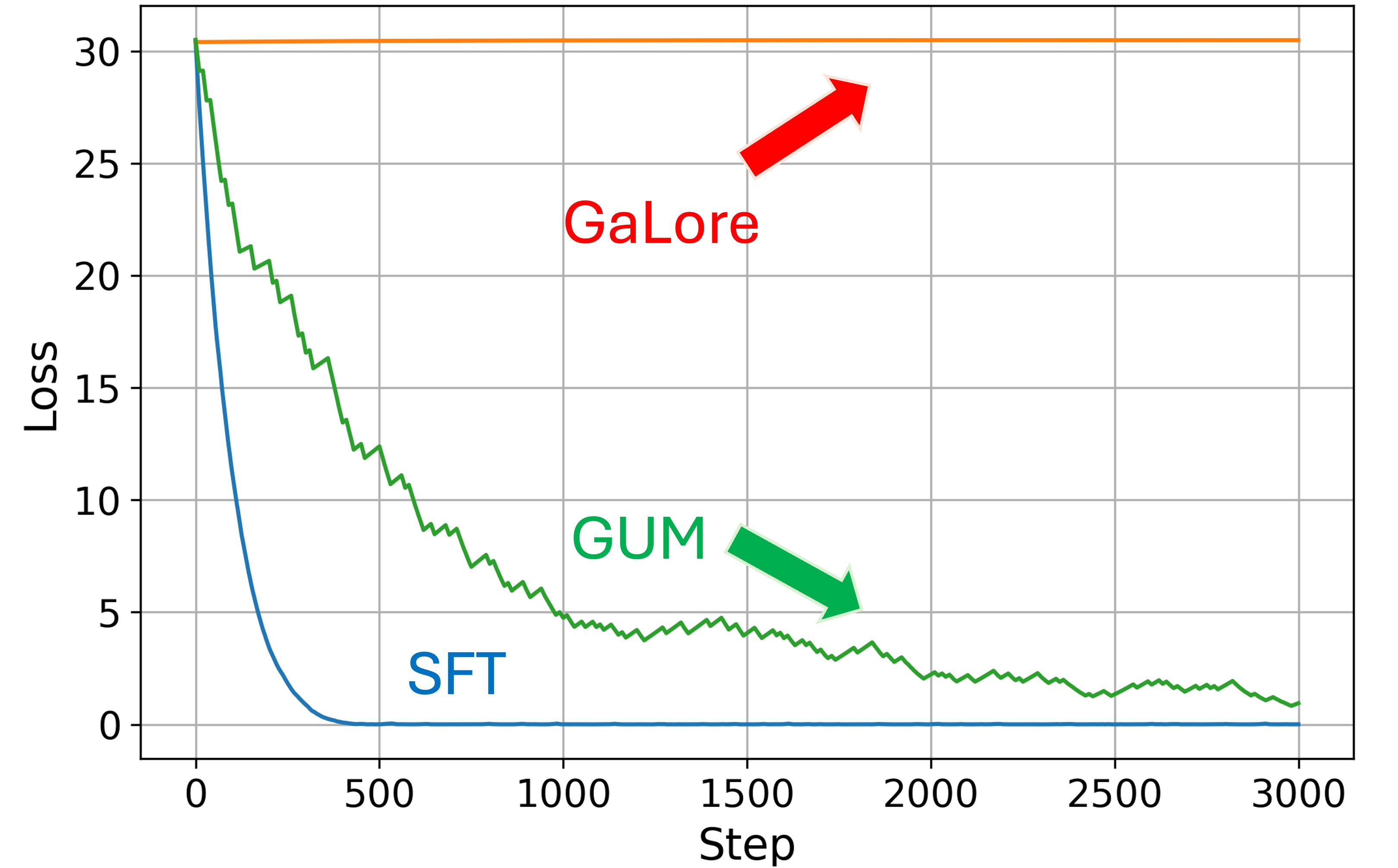
- 实验表明,GUM在LLM微调和预训练上优于GaLore,甚至超越全参数训练,提升模型性能。
📝 摘要(中文)
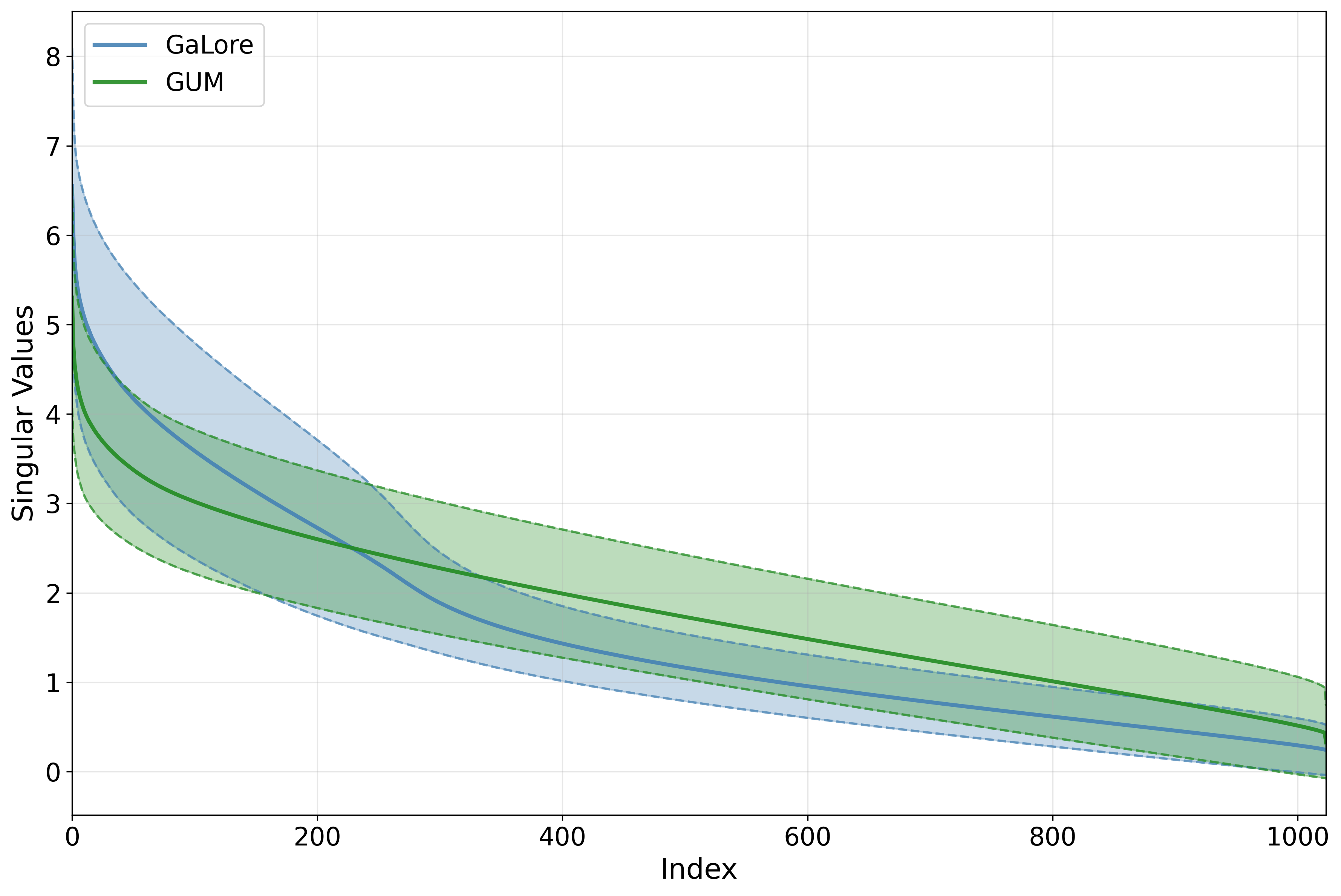
针对日益增长的大型语言模型(LLM)训练需求,内存高效的优化至关重要。梯度低秩投影是一种常用策略,它仅存储投影后的优化器状态,GaLore是其中的代表。然而,许多此类方法的一个显著缺点是缺乏收敛保证,因为各种低秩投影方法相对于原始优化算法引入了固有的偏差,导致与全参数训练相比存在性能差距。为了解决这个问题,本文研究了用于去偏低秩投影机制的层采样技术。特别是,该范例的一个实例化产生了一种新颖且无偏的低秩优化方法,该方法建立在GaLore的机制和Muon算法之上,名为GaLore Unbiased with Muon(GUM)。我们在理论上证明了我们的方法与基础Muon算法的收敛保证相匹配,同时保留了低秩技术的内存效率。在LLM微调和预训练上的实验也证明了相对于GaLore的显著改进,甚至优于全参数训练。进一步的研究表明,该技术的改进来自于层内知识的更均匀分布,从而更有效地利用模型参数空间并更好地记忆。
🔬 方法详解
问题定义:论文旨在解决现有梯度低秩投影方法在训练大型语言模型时引入偏差的问题。这些偏差导致优化算法无法收敛到最优解,从而降低了模型的性能,使其不如全参数训练的模型。GaLore等方法虽然节省了内存,但由于其固有的偏差,无法保证收敛性。
核心思路:论文的核心思路是利用层采样技术来消除低秩投影引入的偏差。通过对每一层进行采样,并结合Muon算法,可以构建一个无偏的低秩优化器。这种方法旨在保留低秩投影的内存效率优势,同时恢复原始优化算法的收敛保证。
技术框架:GUM方法建立在GaLore的低秩投影机制之上,并结合了Muon算法。整体流程包括:1) 对每一层进行采样;2) 使用采样的层计算梯度;3) 对梯度进行低秩投影;4) 使用Muon算法更新模型参数。该框架的关键在于层采样策略,它确保了梯度的无偏估计。
关键创新:最重要的技术创新点是结合层采样和Muon算法,实现无偏的低秩梯度估计。与GaLore等有偏方法相比,GUM能够提供与全参数训练相当的收敛保证,同时保持内存效率。本质区别在于GUM通过层采样消除了低秩投影引入的偏差。
关键设计:GUM的关键设计包括:1) 层采样策略:具体采样概率的确定方式(论文中可能涉及,但摘要未明确说明,此处标记为未知);2) Muon算法的使用:Muon算法作为基础优化器,保证了收敛性;3) 低秩投影的秩的选择:秩的大小决定了内存效率和模型性能之间的权衡(具体数值未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GUM在LLM微调和预训练任务上均优于GaLore,并且在某些情况下甚至超过了全参数训练的性能。这表明GUM不仅能够有效地降低内存需求,还能提升模型的学习能力。具体性能提升幅度在摘要中未给出明确数据,需查阅论文全文。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的训练和微调,尤其是在计算资源受限的情况下。通过使用GUM,可以在保证模型性能的同时,显著降低内存需求,从而使得在消费级硬件上训练大型模型成为可能。此外,该方法还可以推广到其他需要内存高效优化的机器学习任务中。
📄 摘要(原文)
Memory-efficient optimization is critical for training increasingly large language models (LLMs). A popular strategy involves gradient low-rank projection, storing only the projected optimizer states, with GaLore being a representative example. However, a significant drawback of many such methods is their lack of convergence guarantees, as various low-rank projection approaches introduce inherent biases relative to the original optimization algorithms, which contribute to performance gaps compared to full-parameter training. Aiming to tackle this problem, this paper investigates the layerwise sampling technique for debiasing low-rank projection mechanisms. In particular, an instantiation of the paradigm gives rise to a novel and unbiased low-rank optimization method built upon GaLore's mechanism and the Muon algorithm, named GaLore Unbiased with Muon (GUM). We theoretically prove our method matches the convergence guarantees of the base Muon algorithm while preserving the memory efficiency of low-rank techniques. Empirical experiments on LLM fine-tuning and pretraining also demonstrate non-trivial improvements over GaLore and even better performance than full-parameter training. Further investigation shows that the improvement of this technique comes from a more uniform distribution of knowledge inside layers, leading to more efficient utilization of the model parameter space and better memorization.