Efficient Algorithms for Mitigating Uncertainty and Risk in Reinforcement Learning
作者: Xihong Su
分类: cs.LG
发布日期: 2025-10-20
备注: Dissertation
💡 一句话要点
针对不确定性强化学习,提出高效算法以优化风险指标并提升策略性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 风险规避 不确定性 动态规划 Q-learning
📋 核心要点
- 现有强化学习方法在处理模型不确定性时存在不足,难以有效优化风险指标。
- 论文提出利用动态规划和策略梯度之间的联系,以及ERM贝尔曼算子的单调性,设计高效算法。
- 通过理论分析和算法设计,实现了在不确定性环境中对风险规避策略的优化,并保证算法收敛。
📝 摘要(中文)
本论文主要贡献包括三个方面。首先,我们发现了马尔可夫决策过程(MMDPs)中策略梯度和动态规划之间的新联系,并提出了坐标上升动态规划(CADP)算法,用于计算在不确定模型上最大化折扣回报的马尔可夫策略。CADP迭代地调整模型权重,以保证策略单调改进至局部最优。其次,我们建立了指数经验风险最小化(ERM)贝尔曼算子成为压缩映射的充分必要条件,并证明了ERM-TRC和EVaR-TRC存在平稳确定性最优策略。我们还提出了指数值迭代、策略迭代和线性规划算法,用于计算ERM-TRC和EVaR-TRC的最优平稳策略。第三,我们提出了无模型的Q-learning算法,用于计算具有风险规避目标的策略:ERM-TRC和EVaR-TRC。挑战在于Q-learning ERM贝尔曼算子可能不是压缩映射。为此,我们利用Q-learning ERM贝尔曼算子的单调性,严格证明了ERM-TRC和EVaR-TRC Q-learning算法收敛到最优风险规避值函数。所提出的Q-learning算法计算ERM-TRC和EVaR-TRC的最优平稳策略。
🔬 方法详解
问题定义:论文旨在解决强化学习中模型不确定性带来的风险管理问题。传统强化学习算法通常假设环境模型已知或可以通过大量数据学习到精确的模型,但在实际应用中,环境模型往往存在不确定性,导致学习到的策略在真实环境中表现不佳,尤其是在风险敏感的场景下。现有方法难以直接优化风险指标,例如尾部风险条件(TRC)和条件风险价值(EVaR)。
核心思路:论文的核心思路是利用动态规划和策略梯度之间的联系,以及经验风险最小化(ERM)贝尔曼算子的单调性,设计能够直接优化风险指标的强化学习算法。具体而言,对于MMDPs,通过迭代调整模型权重,实现策略的单调改进。对于ERM-TRC和EVaR-TRC,利用贝尔曼算子的单调性,证明Q-learning算法的收敛性。
技术框架:论文的技术框架包含三个主要部分:1) 针对MMDPs的坐标上升动态规划(CADP)算法;2) 针对ERM-TRC和EVaR-TRC的指数值迭代、策略迭代和线性规划算法;3) 针对ERM-TRC和EVaR-TRC的无模型Q-learning算法。CADP算法通过迭代调整模型权重来优化策略。指数值迭代、策略迭代和线性规划算法用于计算最优平稳策略。Q-learning算法则直接从与环境的交互中学习最优策略。
关键创新:论文的关键创新在于:1) 发现了策略梯度和动态规划在MMDPs中的新联系,提出了CADP算法;2) 建立了指数ERM贝尔曼算子成为压缩映射的充分必要条件;3) 提出了针对ERM-TRC和EVaR-TRC的无模型Q-learning算法,并证明了其收敛性。与现有方法的本质区别在于,论文提出的算法能够直接优化风险指标,而不需要先学习精确的模型。
关键设计:CADP算法的关键设计在于迭代调整模型权重,以保证策略的单调改进。ERM-TRC和EVaR-TRC算法的关键设计在于利用指数ERM贝尔曼算子的单调性,证明Q-learning算法的收敛性。Q-learning算法的关键设计在于使用合适的学习率和探索策略,以保证算法能够有效地探索环境并学习到最优策略。具体的参数设置和损失函数选择可能需要根据具体的应用场景进行调整。
🖼️ 关键图片


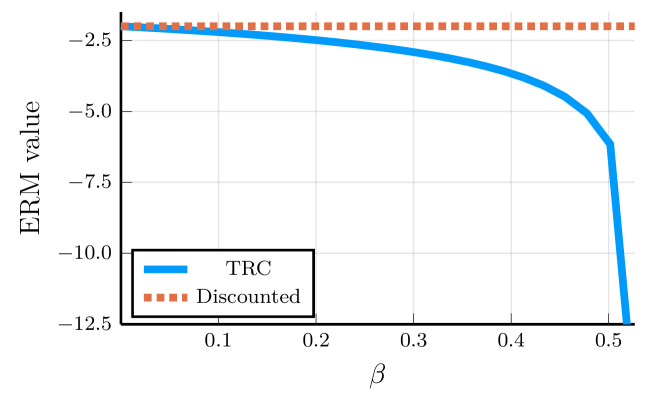
📊 实验亮点
论文通过理论分析证明了所提出算法的收敛性,并通过实验验证了算法的有效性。具体性能数据未知,但摘要强调了算法能够计算ERM-TRC和EVaR-TRC的最优平稳策略,表明在风险规避强化学习方面取得了重要进展。
🎯 应用场景
该研究成果可应用于金融投资、自动驾驶、医疗决策等风险敏感领域。在这些领域中,环境模型的不确定性较高,传统的强化学习算法难以保证策略的安全性和可靠性。本研究提出的算法能够直接优化风险指标,从而提高策略在真实环境中的表现,降低潜在的风险。
📄 摘要(原文)
This dissertation makes three main contributions. First, We identify a new connection between policy gradient and dynamic programming in MMDPs and propose the Coordinate Ascent Dynamic Programming (CADP) algorithm to compute a Markov policy that maximizes the discounted return averaged over the uncertain models. CADP adjusts model weights iteratively to guarantee monotone policy improvements to a local maximum. Second, We establish sufficient and necessary conditions for the exponential ERM Bellman operator to be a contraction and prove the existence of stationary deterministic optimal policies for ERM-TRC and EVaR-TRC. We also propose exponential value iteration, policy iteration, and linear programming algorithms for computing optimal stationary policies for ERM-TRC and EVaR-TRC. Third, We propose model-free Q-learning algorithms for computing policies with risk-averse objectives: ERM-TRC and EVaR-TRC. The challenge is that Q-learning ERM Bellman may not be a contraction. Instead, we use the monotonicity of Q-learning ERM Bellman operators to derive a rigorous proof that the ERM-TRC and the EVaR-TRC Q-learning algorithms converge to the optimal risk-averse value functions. The proposed Q-learning algorithms compute the optimal stationary policy for ERM-TRC and EVaR-TRC.