LILO: Bayesian Optimization with Interactive Natural Language Feedback
作者: Katarzyna Kobalczyk, Zhiyuan Jerry Lin, Benjamin Letham, Zhuokai Zhao, Maximilian Balandat, Eytan Bakshy
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-20
💡 一句话要点
提出LILO框架,利用自然语言反馈进行贝叶斯优化,提升人机交互效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯优化 自然语言反馈 人机交互 大型语言模型 优化算法
📋 核心要点
- 现有方法难以将复杂、细致或主观的目标转化为可量化的优化目标,反馈至关重要。
- LILO框架利用大型语言模型将自然语言反馈转化为标量效用,用于贝叶斯优化。
- 实验表明,LILO在样本效率和性能上优于传统贝叶斯优化和纯LLM优化方法。
📝 摘要(中文)
本文提出了一种语言在环(LILO)框架,该框架使用大型语言模型(LLM)将非结构化的自然语言反馈转换为标量效用,从而在数值搜索空间上进行贝叶斯优化(BO)。与仅接受受限反馈格式并需要为每个特定领域问题定制模型的偏好贝叶斯优化不同,我们的方法利用LLM将各种文本反馈转换为一致的效用信号,并轻松包含灵活的用户先验,而无需手动设计核函数。同时,我们的方法保持了BO的样本效率和有原则的不确定性量化。我们表明,这种混合方法不仅为决策者提供了更自然的界面,而且优于传统的BO基线和仅LLM优化器,尤其是在反馈受限的情况下。
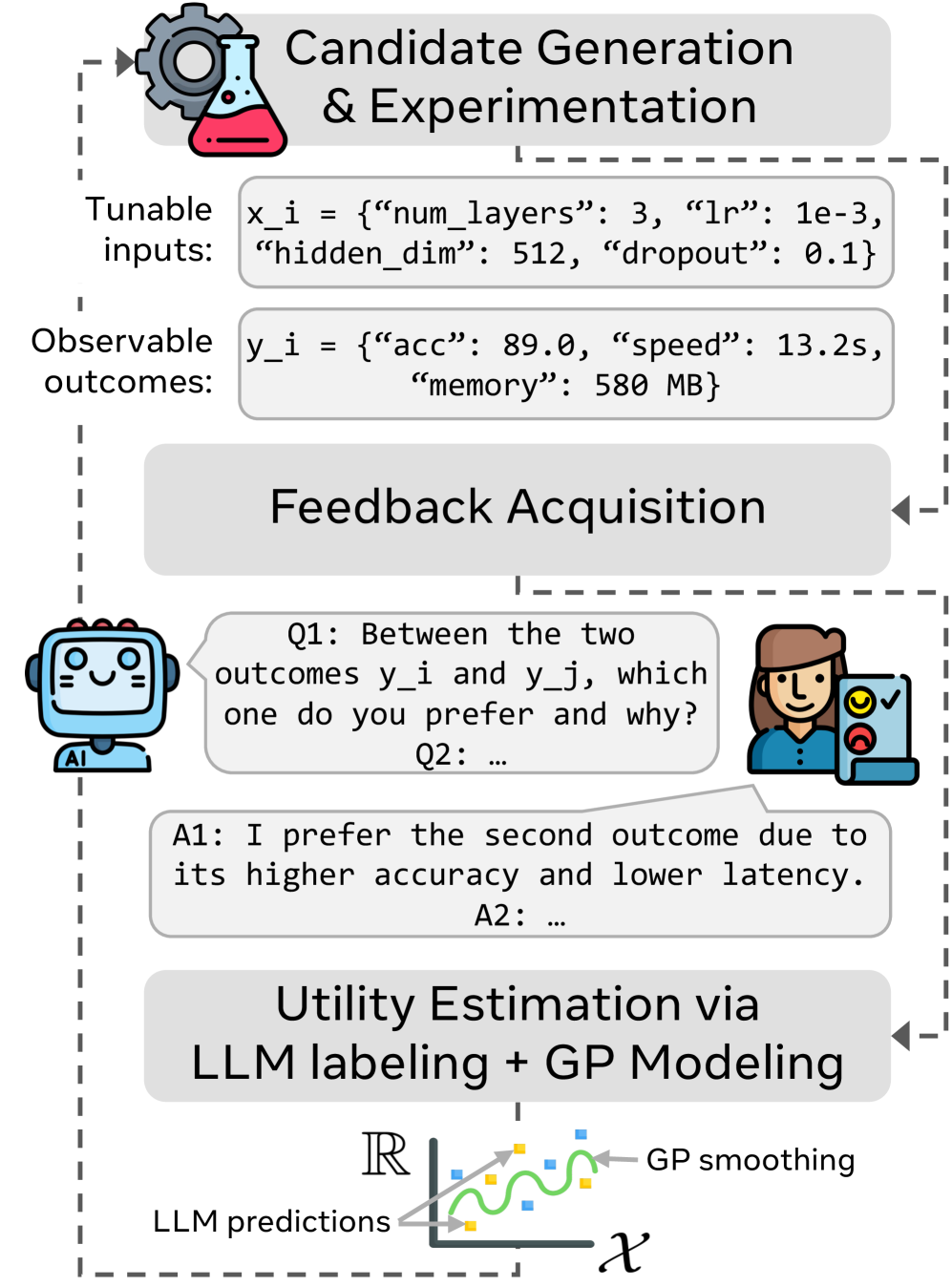
🔬 方法详解
问题定义:论文旨在解决在贝叶斯优化过程中,如何有效地利用用户提供的自然语言反馈来指导优化过程的问题。现有方法,如偏好贝叶斯优化,通常需要预定义的反馈格式和针对特定领域定制的模型,限制了其通用性和灵活性。此外,手动设计核函数来融入用户先验知识也十分困难。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言理解和生成能力,将用户提供的各种形式的文本反馈转化为一致的效用信号,从而指导贝叶斯优化过程。通过这种方式,可以更自然地与决策者进行交互,并灵活地融入用户先验知识。
技术框架:LILO框架包含以下主要模块:1) 用户提供自然语言反馈;2) LLM将自然语言反馈转换为标量效用值;3) 贝叶斯优化算法利用这些效用值来选择下一个采样点;4) 用户对采样点进行评估并提供新的反馈。这个过程迭代进行,直到找到最优解。
关键创新:LILO框架的关键创新在于将大型语言模型与贝叶斯优化相结合,从而能够处理非结构化的自然语言反馈。这使得用户能够以更自然、更灵活的方式与优化系统进行交互,并允许系统利用用户提供的丰富信息来指导优化过程。与传统的偏好贝叶斯优化相比,LILO不需要预定义的反馈格式,也不需要为每个特定领域定制模型。
关键设计:LILO框架的关键设计包括:1) 如何选择合适的LLM,并对其进行微调,以使其能够准确地将自然语言反馈转换为标量效用值;2) 如何设计合适的提示(prompt),以引导LLM生成高质量的效用值;3) 如何将LLM生成的效用值融入到贝叶斯优化算法中,以有效地指导优化过程。论文可能还涉及损失函数的设计,以确保LLM生成的效用值与用户的真实意图相符(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LILO框架在反馈受限的情况下,优于传统的贝叶斯优化基线和仅使用LLM的优化器。具体性能数据未知,但摘要强调了LILO在样本效率和性能方面的优势,尤其是在需要少量反馈就能达到较好效果的场景下。
🎯 应用场景
LILO框架可应用于各种需要人机交互的优化问题,例如产品设计、超参数优化、机器人控制等。通过利用用户的自然语言反馈,LILO能够更有效地找到满足用户需求的解决方案,提高优化效率和用户满意度。未来,LILO有望成为一种通用的人机交互优化工具,在各个领域发挥重要作用。
📄 摘要(原文)
For many real-world applications, feedback is essential in translating complex, nuanced, or subjective goals into quantifiable optimization objectives. We propose a language-in-the-loop framework that uses a large language model (LLM) to convert unstructured feedback in the form of natural language into scalar utilities to conduct BO over a numeric search space. Unlike preferential BO, which only accepts restricted feedback formats and requires customized models for each domain-specific problem, our approach leverages LLMs to turn varied types of textual feedback into consistent utility signals and to easily include flexible user priors without manual kernel design. At the same time, our method maintains the sample efficiency and principled uncertainty quantification of BO. We show that this hybrid method not only provides a more natural interface to the decision maker but also outperforms conventional BO baselines and LLM-only optimizers, particularly in feedback-limited regimes.