An Empirical Study of Lagrangian Methods in Safe Reinforcement Learning
作者: Lindsay Spoor, Álvaro Serra-Gómez, Aske Plaat, Thomas Moerland
分类: cs.LG, cs.AI, cs.RO, eess.SY
发布日期: 2025-10-20
🔗 代码/项目: GITHUB
💡 一句话要点
研究安全强化学习中拉格朗日方法的性能与稳定性,揭示自动更新乘子的挑战与改进方向。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 拉格朗日方法 约束优化 拉格朗日乘子 PID控制
📋 核心要点
- 安全强化学习面临如何在满足约束条件的同时优化性能的挑战,拉格朗日方法是常用手段,但乘子λ的选择缺乏理论指导。
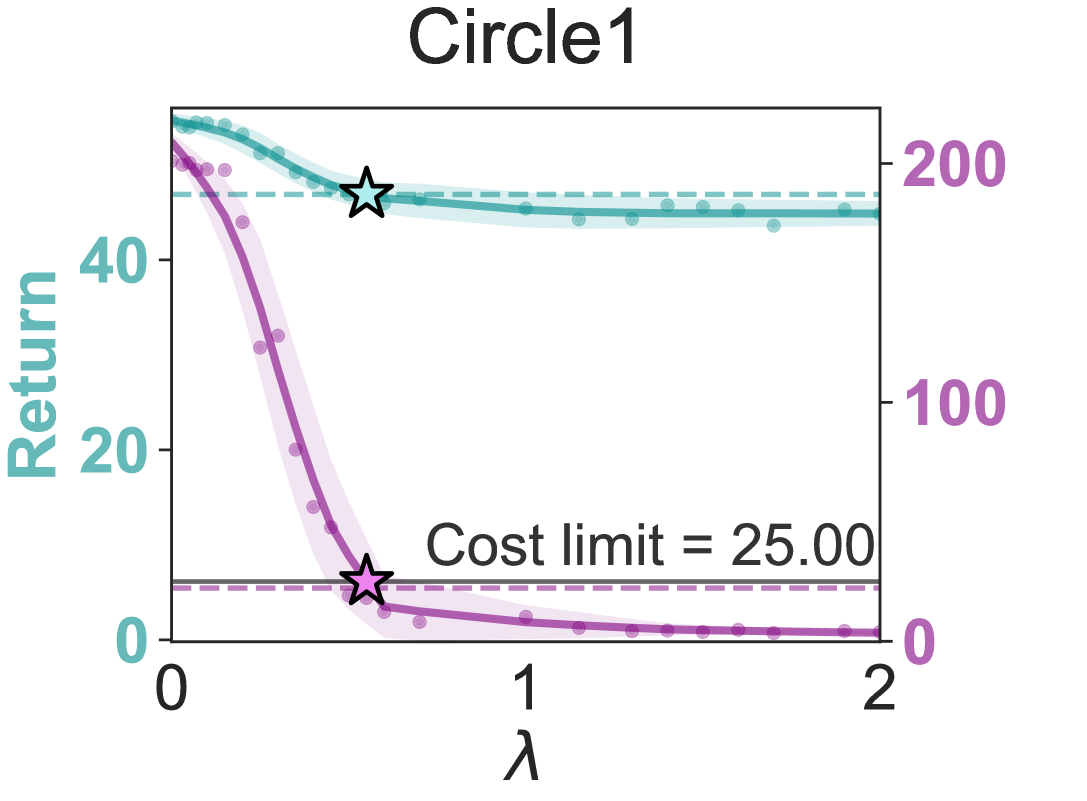
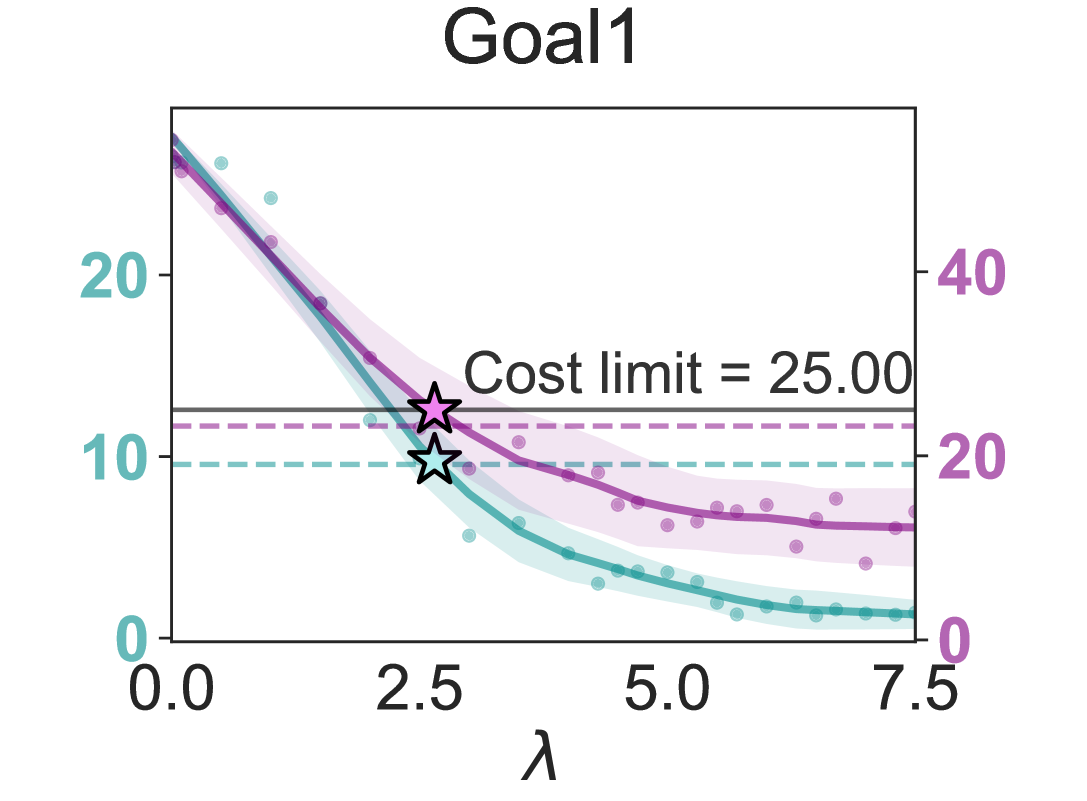
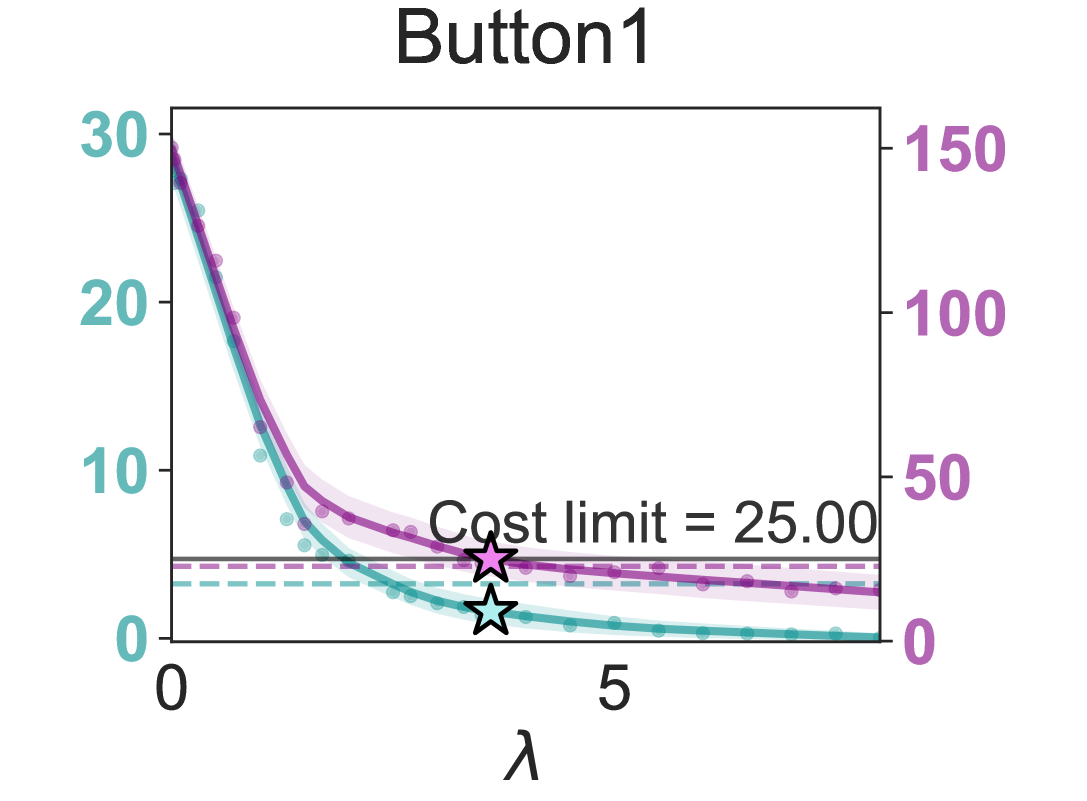
- 该研究通过λ-profiles可视化回报与约束成本的权衡,揭示了λ的高度敏感性,并分析了自动乘子更新的性能与稳定性。
- 实验表明自动乘子更新能超越固定λ的最优性能,但也存在振荡行为,PID控制虽可缓解,但需精细调参,未来需进一步研究。
📝 摘要(中文)
在机器人、导航和电力系统等安全关键领域,存在着约束优化问题,需要在最大化性能的同时仔细平衡相关约束。安全强化学习提供了一个解决这些挑战的框架,其中拉格朗日方法是一种流行的选择。然而,拉格朗日方法的有效性关键取决于拉格朗日乘子λ的选择,它控制着回报和约束成本之间的权衡。一种常见的方法是在训练期间自动更新乘子。虽然这在实践中很常见,但关于自动更新的鲁棒性及其对整体性能的影响的经验证据仍然有限。因此,我们分析了安全强化学习中拉格朗日乘子的(i)最优性和(ii)稳定性,涵盖了一系列任务。我们提供了λ-profiles,可以完整地可视化优化问题中回报和约束成本之间的权衡。这些profiles显示了λ的高度敏感性,并且证实了选择最优值λ缺乏一般的直觉。我们的发现还表明,由于学习轨迹的巨大差异,自动乘子更新能够恢复甚至超过在λ处发现的最佳性能。此外,我们表明自动乘子更新在训练期间表现出振荡行为,可以通过PID控制的更新来缓解。然而,这种方法需要仔细调整才能在各项任务中实现始终如一的更好性能。这突出了进一步研究稳定安全强化学习中拉格朗日方法的必要性。用于重现我们结果的代码可以在https://github.com/lindsayspoor/Lagrangian_SafeRL找到。
🔬 方法详解
问题定义:论文旨在解决安全强化学习中拉格朗日乘子λ难以选择的问题。现有方法通常采用手动调整或自动更新,但缺乏对自动更新策略的鲁棒性和稳定性的深入理解,导致难以获得最优性能,甚至可能出现训练不稳定等问题。
核心思路:论文的核心思路是通过实证研究,深入分析拉格朗日乘子λ在安全强化学习中的行为特性,特别是自动更新策略的性能和稳定性。通过可视化λ-profiles,揭示λ对回报和约束成本的敏感性,并探索PID控制等方法来缓解自动更新过程中的振荡行为。
技术框架:论文的技术框架主要包括以下几个部分:1) 定义安全强化学习问题,明确回报函数和约束条件;2) 实现基于拉格朗日方法的安全强化学习算法,包括策略优化和拉格朗日乘子更新;3) 设计实验环境,涵盖多种安全关键任务;4) 通过λ-profiles可视化回报和约束成本之间的权衡关系,分析λ的最优性和敏感性;5) 研究自动乘子更新策略的性能和稳定性,并探索PID控制等方法来缓解振荡行为。
关键创新:论文的关键创新在于对安全强化学习中拉格朗日乘子的行为进行了深入的实证分析,揭示了自动更新策略的优势和局限性。通过λ-profiles可视化了回报和约束成本之间的权衡关系,为理解λ的选择提供了新的视角。此外,探索了PID控制等方法来缓解自动更新过程中的振荡行为,为稳定拉格朗日方法提供了新的思路。
关键设计:论文的关键设计包括:1) λ-profiles的生成方法,通过扫描不同的λ值,记录对应的回报和约束成本,从而可视化权衡关系;2) 自动乘子更新策略的具体实现,包括更新步长、学习率等参数的设置;3) PID控制器的设计,包括比例、积分、微分系数的调整,以实现对乘子更新过程的稳定控制;4) 实验环境的设计,涵盖多种安全关键任务,以验证算法的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,自动乘子更新策略有时能够超越固定λ的最优性能,但同时也存在振荡行为。PID控制可以缓解振荡,但需要精细调参。λ-profiles清晰展示了λ对回报和约束成本的敏感性,验证了选择最优λ的困难性。代码已开源,方便复现和进一步研究。
🎯 应用场景
该研究成果可应用于机器人、导航、电力系统等安全关键领域,帮助设计更安全可靠的智能系统。通过优化拉格朗日乘子的选择和更新策略,可以提高系统在满足约束条件下的性能,降低安全风险,具有重要的实际应用价值和潜在的社会影响。
📄 摘要(原文)
In safety-critical domains such as robotics, navigation and power systems, constrained optimization problems arise where maximizing performance must be carefully balanced with associated constraints. Safe reinforcement learning provides a framework to address these challenges, with Lagrangian methods being a popular choice. However, the effectiveness of Lagrangian methods crucially depends on the choice of the Lagrange multiplier $λ$, which governs the trade-off between return and constraint cost. A common approach is to update the multiplier automatically during training. Although this is standard in practice, there remains limited empirical evidence on the robustness of an automated update and its influence on overall performance. Therefore, we analyze (i) optimality and (ii) stability of Lagrange multipliers in safe reinforcement learning across a range of tasks. We provide $λ$-profiles that give a complete visualization of the trade-off between return and constraint cost of the optimization problem. These profiles show the highly sensitive nature of $λ$ and moreover confirm the lack of general intuition for choosing the optimal value $λ^$. Our findings additionally show that automated multiplier updates are able to recover and sometimes even exceed the optimal performance found at $λ^$ due to the vast difference in their learning trajectories. Furthermore, we show that automated multiplier updates exhibit oscillatory behavior during training, which can be mitigated through PID-controlled updates. However, this method requires careful tuning to achieve consistently better performance across tasks. This highlights the need for further research on stabilizing Lagrangian methods in safe reinforcement learning. The code used to reproduce our results can be found at https://github.com/lindsayspoor/Lagrangian_SafeRL.