Plasma Shape Control via Zero-shot Generative Reinforcement Learning
作者: Niannian Wu, Rongpeng Li, Zongyu Yang, Yong Xiao, Ning Wei, Yihang Chen, Bo Li, Zhifeng Zhao, Wulyu Zhong
分类: physics.plasm-ph, cs.LG
发布日期: 2025-10-20
💡 一句话要点
提出基于零样本生成强化学习的等离子体形状控制方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 等离子体形状控制 零样本学习 生成对抗模仿学习 希尔伯特空间 强化学习
📋 核心要点
- 传统PID控制器适应性有限,特定任务强化学习泛化性差且需重复训练,难以满足等离子体形状控制需求。
- 结合生成对抗模仿学习和希尔伯特空间表示学习,从离线数据中学习通用控制策略,实现零样本轨迹跟踪。
- 在HL-3托卡马克模拟器上的实验表明,该策略能精确稳定地跟踪各种等离子体场景下的参考轨迹。
📝 摘要(中文)
本文提出了一种新颖的框架,旨在从大规模离线历史PID控制放电数据集中开发一种通用的零样本控制策略,以克服传统PID控制器在等离子体形状控制方面的适应性限制以及特定任务强化学习(RL)方法的泛化能力不足和重复再训练的需求。该方法将生成对抗模仿学习(GAIL)与希尔伯特空间表示学习相结合,实现了双重目标:模仿PID数据的稳定运行风格,并构建几何结构化的潜在空间,以实现高效的、目标导向的控制。所得到的策略可以以零样本方式部署于各种轨迹跟踪任务,无需任何特定任务的微调。在HL-3托卡马克模拟器上的评估表明,该策略擅长精确且稳定地跟踪各种等离子体场景中关键形状参数的参考轨迹。这项工作为未来聚变反应堆开发高度灵活和数据高效的智能控制系统提供了一条可行的途径。
🔬 方法详解
问题定义:等离子体形状控制是聚变反应堆运行的关键环节。传统PID控制器难以适应复杂多变的等离子体环境,而针对特定任务训练的强化学习方法泛化能力不足,需要大量在线训练数据和时间。因此,如何利用已有的历史数据,开发一种通用的、能够零样本适应不同等离子体场景的控制策略,是一个亟待解决的问题。
核心思路:论文的核心思路是从大规模离线PID控制数据中学习一种通用的控制策略,该策略能够模仿PID控制器的稳定运行风格,并具备高效的目标导向控制能力。通过结合生成对抗模仿学习(GAIL)和希尔伯特空间表示学习,构建一个几何结构化的潜在空间,从而实现对不同等离子体状态的有效表示和控制。
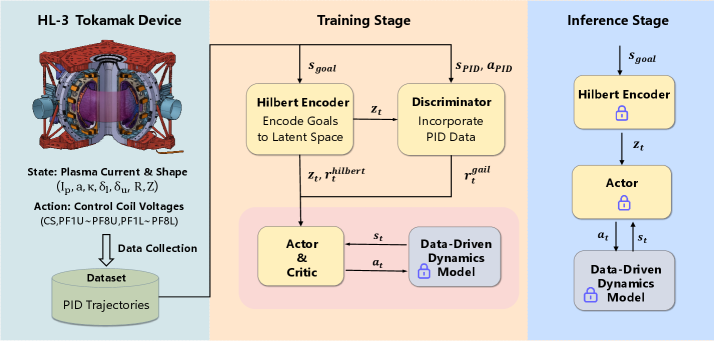
技术框架:该方法的技术框架主要包含以下几个阶段:1) 数据收集:收集历史PID控制下的等离子体运行数据。2) 希尔伯特空间表示学习:利用自编码器等方法,将高维的等离子体状态数据映射到低维的希尔伯特空间,并学习状态的几何结构化表示。3) 生成对抗模仿学习:利用GAIL,训练一个策略网络,使其能够模仿PID控制器的行为,并在希尔伯特空间中进行探索和学习。4) 零样本部署:将训练好的策略网络直接部署到新的等离子体场景中,无需任何微调。
关键创新:该方法最重要的技术创新点在于将生成对抗模仿学习与希尔伯特空间表示学习相结合,从而实现了从离线数据中学习通用控制策略的目标。与传统的强化学习方法相比,该方法无需在线训练,具有更高的效率和更好的泛化能力。与传统的模仿学习方法相比,该方法能够利用生成对抗网络进行探索,从而学习到更优的控制策略。
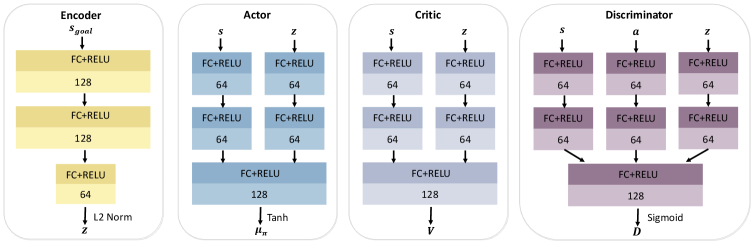
关键设计:在希尔伯特空间表示学习中,使用了自编码器来学习状态的低维表示,并设计了相应的损失函数来保证表示的几何结构化。在生成对抗模仿学习中,使用了GAIL算法,并对奖励函数进行了精心设计,以鼓励策略网络模仿PID控制器的稳定运行风格。策略网络和判别器网络均采用了多层感知机结构,并使用了ReLU激活函数。
🖼️ 关键图片

📊 实验亮点
在HL-3托卡马克模拟器上的实验结果表明,该方法能够精确且稳定地跟踪各种等离子体场景中关键形状参数的参考轨迹,无需任何特定任务的微调。与传统的PID控制器相比,该方法具有更好的适应性和更高的控制精度。具体性能数据(例如跟踪误差、稳定性指标等)在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于未来聚变反应堆的智能控制系统,实现对等离子体形状的精确控制,提高反应堆的运行效率和稳定性。此外,该方法还可以推广到其他需要从离线数据中学习通用控制策略的领域,例如机器人控制、自动驾驶等。
📄 摘要(原文)
Traditional PID controllers have limited adaptability for plasma shape control, and task-specific reinforcement learning (RL) methods suffer from limited generalization and the need for repetitive retraining. To overcome these challenges, this paper proposes a novel framework for developing a versatile, zero-shot control policy from a large-scale offline dataset of historical PID-controlled discharges. Our approach synergistically combines Generative Adversarial Imitation Learning (GAIL) with Hilbert space representation learning to achieve dual objectives: mimicking the stable operational style of the PID data and constructing a geometrically structured latent space for efficient, goal-directed control. The resulting foundation policy can be deployed for diverse trajectory tracking tasks in a zero-shot manner without any task-specific fine-tuning. Evaluations on the HL-3 tokamak simulator demonstrate that the policy excels at precisely and stably tracking reference trajectories for key shape parameters across a range of plasma scenarios. This work presents a viable pathway toward developing highly flexible and data-efficient intelligent control systems for future fusion reactors.