Certified Self-Consistency: Statistical Guarantees and Test-Time Training for Reliable Reasoning in LLMs
作者: Paula Cordero-Encinar, Andrew B. Duncan
分类: stat.ML, cs.LG
发布日期: 2025-10-20 (更新: 2025-10-23)
💡 一句话要点
提出自洽性认证框架,为LLM推理提供统计保证和测试时训练方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自洽性 统计认证 测试时训练 可靠性 推理 集中界 后训练
📋 核心要点
- 现有自洽性和测试时强化学习等方法缺乏对LLM可靠性的统计保证和机制理解。
- 论文提出自洽性认证框架,利用多数投票提供统计保证,并优化后训练目标以提高可靠性。
- 论文推导了有限样本集中界,提出了自适应停止规则MMC,并证明TTRL能有效锐化答案分布。
📝 摘要(中文)
本文提出了一个统一的框架,用于大型语言模型(LLM)中可认证的推理。研究表明,多数投票提供了一种自洽性的统计认证:在温和的假设下,聚合答案与模型终端分布的模式高度一致。论文推导了有限样本和随时有效的集中界,量化了这种置信度,并引入了Martingale Majority Certificate (MMC),这是一种自适应地确定何时抽取足够样本的序贯停止规则。此外,论文证明了诸如测试时强化学习(TTRL)等无标签后训练方法,通过将答案分布指数级地倾斜向其模式,从而隐式地锐化答案分布,从而减少了认证所需的样本数量。基于此,论文提出了新的后训练目标,明确地优化了锐度和偏差之间的权衡。总之,这些结果在一个用于推理LLM中无标签、可认证可靠性的单一统计框架内,解释并连接了自洽性和TTRL这两种核心的测试时缩放策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理结果可靠性难以保证的问题。现有的自洽性(Self-Consistency)和测试时强化学习(Test-Time Reinforcement Learning, TTRL)等方法虽然能提升LLM的可靠性,但缺乏理论支撑,无法提供统计意义上的保证,难以量化其置信度。此外,这些方法背后的机制尚不明确,如何进一步优化也缺乏指导。
核心思路:论文的核心思路是利用统计学方法,将LLM的自洽性与模型输出分布的模式联系起来。通过证明多数投票的结果与模型输出分布的模式具有高度一致性,从而为LLM的推理结果提供统计认证。此外,论文还研究了TTRL等后训练方法对模型输出分布的影响,并提出了新的后训练目标,以优化模型输出分布的锐度和偏差之间的权衡。
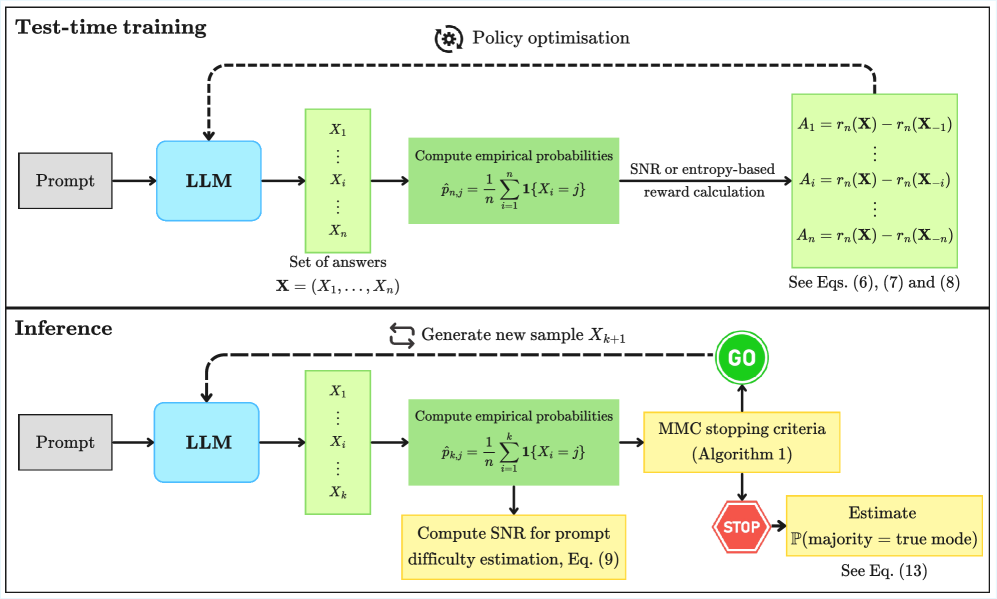
技术框架:论文的技术框架主要包含以下几个部分: 1. 自洽性认证框架:利用多数投票机制,对LLM的多个输出进行聚合,得到最终的答案。 2. 统计保证:推导有限样本和随时有效的集中界,量化多数投票结果与模型输出分布模式的一致性。 3. Martingale Majority Certificate (MMC):提出一种自适应的停止规则,根据统计保证动态地决定需要采样的数量。 4. 后训练优化:分析TTRL等后训练方法对模型输出分布的影响,并提出新的后训练目标,以优化模型输出分布的锐度和偏差。
关键创新:论文最重要的技术创新点在于将统计学方法引入到LLM的可靠性分析中,为LLM的推理结果提供了统计意义上的保证。具体来说,论文首次证明了多数投票的结果与模型输出分布的模式具有高度一致性,并提出了相应的统计认证方法。此外,论文还提出了新的后训练目标,能够更有效地优化模型输出分布,提高推理结果的可靠性。
关键设计:论文的关键设计包括: 1. 集中界的选择:论文选择了合适的集中界,以量化多数投票结果与模型输出分布模式的一致性。 2. MMC的停止规则:MMC的停止规则基于Martingale理论,能够自适应地调整采样数量,以满足统计保证的要求。 3. 后训练目标的设计:论文提出的后训练目标旨在优化模型输出分布的锐度和偏差之间的权衡,从而提高推理结果的可靠性。具体形式未知。
🖼️ 关键图片

📊 实验亮点
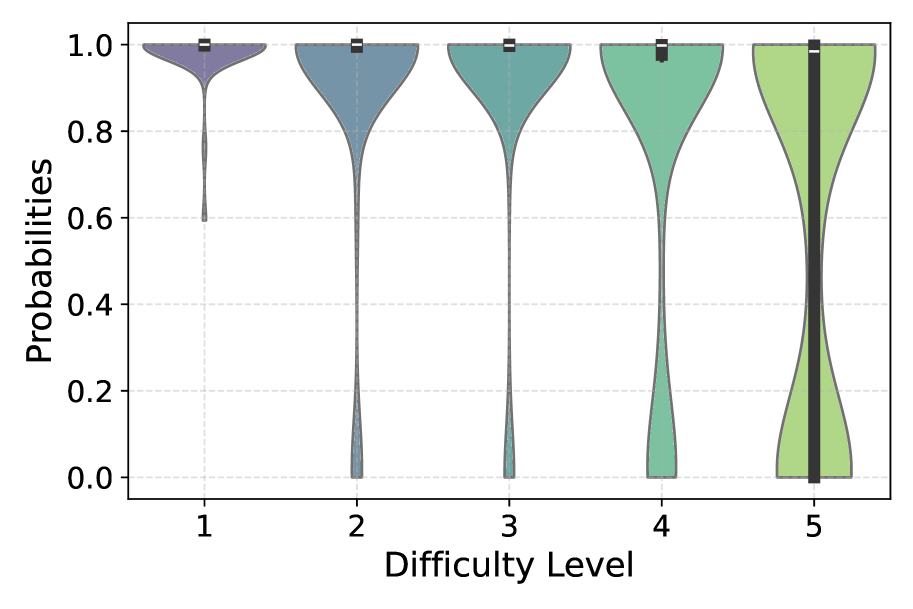
论文提出了自洽性认证框架,为LLM推理提供统计保证。通过实验验证,该框架能够有效地量化LLM推理结果的置信度,并指导后训练方法的优化。具体性能数据未知,但论文强调了该框架在提高LLM可靠性方面的潜力。
🎯 应用场景
该研究成果可应用于对可靠性要求较高的LLM应用场景,如医疗诊断、金融风控、法律咨询等。通过提供统计保证,可以提高用户对LLM推理结果的信任度,并降低因错误推理带来的风险。此外,该研究提出的后训练方法可以进一步提升LLM的可靠性,使其在实际应用中更具竞争力。
📄 摘要(原文)
Recent advances such as self-consistency and test-time reinforcement learning (TTRL) improve the reliability of large language models (LLMs) without additional supervision, yet their underlying mechanisms and statistical guarantees remain poorly understood. We present a unified framework for certifiable inference in LLMs, showing that majority voting provides a statistical certificate of self-consistency: under mild assumptions, the aggregated answer coincides with the mode of the model's terminal distribution with high probability. We derive finite-sample and anytime-valid concentration bounds that quantify this confidence, and introduce the Martingale Majority Certificate (MMC), a sequential stopping rule that adaptively determines when sufficient samples have been drawn. We further prove that label-free post-training methods such as TTRL implicitly sharpen the answer distribution by exponentially tilting it toward its mode, thereby reducing the number of samples required for certification. Building on this insight, we propose new post-training objectives that explicitly optimise this trade-off between sharpness and bias. Together, these results explain and connect two central test-time scaling strategies, self-consistency and TTRL, within a single statistical framework for label-free, certifiable reliability in reasoning LLMs.