TabR1: Taming GRPO for tabular reasoning LLMs
作者: Pengxiang Cai, Zihao Gao, Jintai Chen
分类: cs.LG, cs.AI
发布日期: 2025-10-20 (更新: 2025-10-23)
💡 一句话要点
TabR1:提出基于GRPO的表格推理LLM,提升零样本和小样本学习能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格推理 大型语言模型 强化学习 置换不变性 零样本学习
📋 核心要点
- 现有表格预测模型泛化性差、可解释性弱,而LLM在表格数据上的推理能力尚未充分挖掘。
- TabR1通过置换相对策略优化(PRPO)方法,将列置换不变性作为先验知识融入强化学习过程。
- 实验表明,TabR1在零样本和小样本学习中表现出色,甚至超越了更大规模的LLM。
📝 摘要(中文)
表格预测传统上依赖于梯度提升决策树和专用深度学习模型,这些模型在特定任务中表现出色,但可解释性有限,且在不同表格之间的泛化能力较弱。推理大型语言模型(LLM)有望实现跨任务适应性,并提供透明的推理过程,但其在表格数据方面的潜力尚未完全发挥。本文提出了TabR1,这是第一个用于表格预测的多步推理LLM。其核心是置换相对策略优化(PRPO),这是一种简单而有效的强化学习方法,它将列置换不变性编码为结构先验。通过为每个样本构建多个保持标签不变的置换,并在置换内部和之间估计优势,PRPO将稀疏奖励转化为密集的学习信号,并提高泛化能力。在有限的监督下,PRPO激活了LLM用于表格预测的推理能力,从而提高了少样本和零样本性能以及可解释性。综合实验表明,TabR1在完全监督微调下实现了与强大基线相当的性能。在零样本设置中,TabR1的性能接近于32-shot设置下的强大基线。此外,TabR1 (8B) 在各种任务中显著优于更大的LLM,比DeepSeek-R1 (685B) 提高了高达 53.17%。
🔬 方法详解
问题定义:论文旨在解决表格数据预测问题,现有方法如梯度提升决策树和专用深度学习模型虽然在特定任务上表现良好,但缺乏跨表格的泛化能力和可解释性。大型语言模型(LLM)虽然具有推理能力,但在表格数据上的应用潜力尚未被充分挖掘。
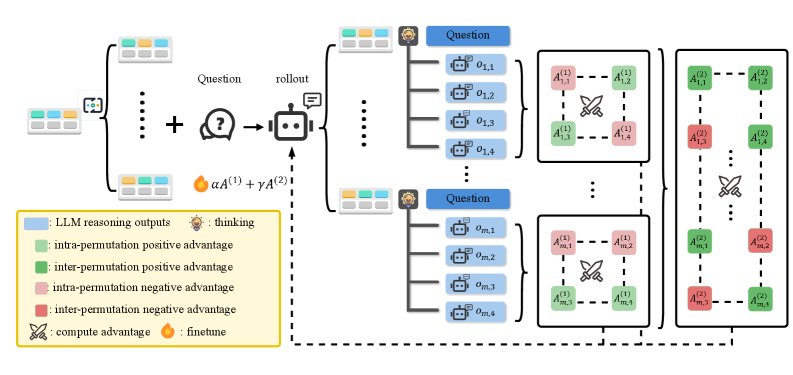
核心思路:论文的核心思路是利用强化学习方法,训练LLM在表格数据上进行推理。通过引入置换相对策略优化(PRPO),将列置换不变性作为结构先验,提高模型的泛化能力。PRPO通过构建多个保持标签不变的列置换,并在置换内部和之间估计优势,从而将稀疏奖励转化为密集的学习信号。
技术框架:TabR1的整体框架包含一个LLM作为策略网络,以及PRPO作为强化学习算法。LLM接收表格数据作为输入,输出预测结果。PRPO通过与环境交互,根据预测结果的奖励信号,更新LLM的参数。框架的关键在于PRPO如何利用列置换不变性来提高学习效率和泛化能力。
关键创新:论文的关键创新在于提出了置换相对策略优化(PRPO)方法。PRPO将列置换不变性编码为结构先验,通过构建多个保持标签不变的列置换,并在置换内部和之间估计优势,从而将稀疏奖励转化为密集的学习信号。这与传统的强化学习方法不同,后者通常只考虑单个样本的奖励信号。
关键设计:PRPO的关键设计包括:1) 构建多个保持标签不变的列置换;2) 在置换内部和之间估计优势;3) 使用优势函数来指导策略更新。具体的参数设置和损失函数细节在论文中进行了详细描述,但此处未提供具体数值。
🖼️ 关键图片
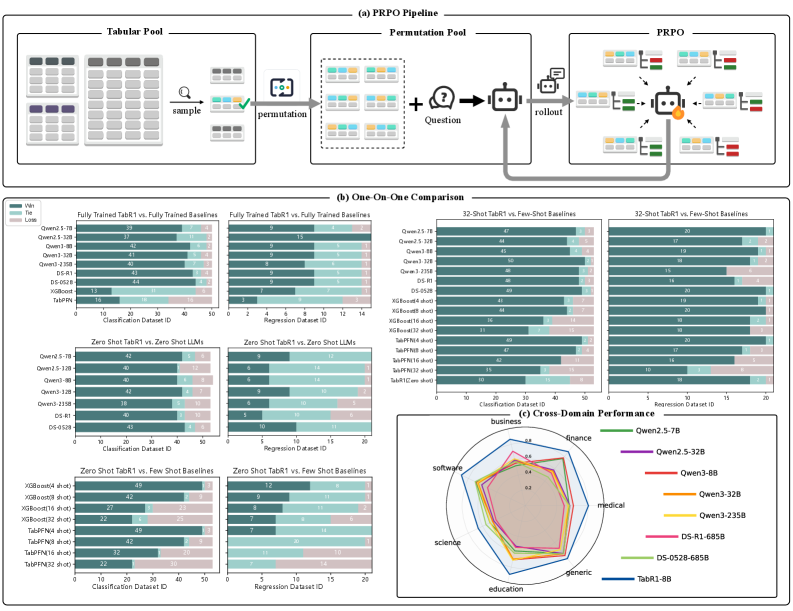

📊 实验亮点
TabR1在实验中表现出色,在完全监督微调下实现了与强大基线相当的性能。在零样本设置中,TabR1的性能接近于32-shot设置下的强大基线。更重要的是,TabR1 (8B) 在各种任务中显著优于更大的LLM,比DeepSeek-R1 (685B) 提高了高达 53.17%。这些结果表明,TabR1能够有效地利用LLM的推理能力,并在表格数据预测任务中取得显著的性能提升。
🎯 应用场景
TabR1在金融、医疗、销售等领域具有广泛的应用前景。它可以用于预测客户流失、疾病诊断、销售额预测等任务。该研究的实际价值在于提高了表格数据预测的准确性和可解释性,并降低了对大量标注数据的依赖。未来,TabR1有望成为表格数据分析的重要工具。
📄 摘要(原文)
Tabular prediction has traditionally relied on gradient-boosted decision trees and specialized deep learning models, which excel within tasks but provide limited interpretability and weak transfer across tables. Reasoning large language models (LLMs) promise cross-task adaptability with trans- parent reasoning traces, yet their potential has not been fully realized for tabular data. This paper presents TabR1, the first reasoning LLM for tabular prediction with multi-step reasoning. At its core is Permutation Relative Policy Optimization (PRPO), a simple yet efficient reinforcement learning method that encodes column-permutation invariance as a structural prior. By construct- ing multiple label-preserving permutations per sample and estimating advantages both within and across permutations, PRPO transforms sparse rewards into dense learning signals and improves generalization. With limited supervision, PRPO activates the reasoning ability of LLMs for tabular prediction, enhancing few-shot and zero-shot performance as well as interpretability. Comprehensive experiments demonstrate that TabR1 achieves performance comparable to strong baselines under full-supervision fine-tuning. In the zero-shot setting, TabR1 approaches the performance of strong baselines under the 32-shot setting. Moreover, TabR1 (8B) substantially outperforms much larger LLMs across various tasks, achieving up to 53.17% improvement over DeepSeek-R1 (685B).