Auto-Rubric: Learning to Extract Generalizable Criteria for Reward Modeling
作者: Lipeng Xie, Sen Huang, Zhuo Zhang, Anni Zou, Yunpeng Zhai, Dingchao Ren, Kezun Zhang, Haoyuan Hu, Boyin Liu, Haoran Chen, Zhaoyang Liu, Bolin Ding
分类: cs.LG, cs.AI
发布日期: 2025-10-20
💡 一句话要点
提出Auto-Rubric框架,通过学习可泛化准则提升奖励模型的数据效率和可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 数据效率 可解释性 评分细则 大型语言模型
📋 核心要点
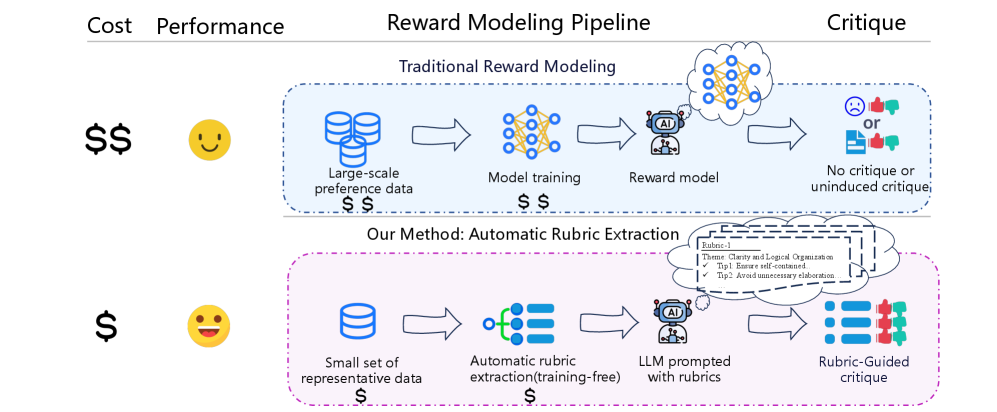
- 现有奖励模型依赖大量偏好数据,且缺乏可解释性,基于评分细则的方法虽有改进,但质量控制和优化不足。
- Auto-Rubric框架利用人类偏好评估细则的泛化能力,通过两阶段流程提取高质量、可泛化的评分准则。
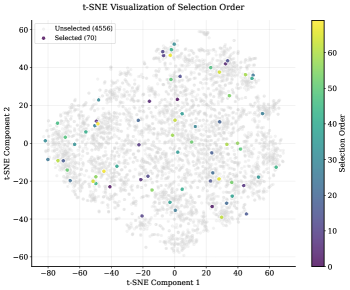
- 实验表明,该框架仅用少量数据(1.5%)即可训练出高性能奖励模型,甚至超越了完全训练的专用模型。
📝 摘要(中文)
奖励模型对于将大型语言模型(LLM)与人类价值观对齐至关重要,但其开发受到昂贵的偏好数据集和较差的可解释性的阻碍。虽然最近基于评分细则的方法提供了透明性,但它们通常缺乏系统的质量控制和优化,从而在可扩展性和可靠性之间造成权衡。我们通过一个新颖的、无需训练的框架来解决这些限制,该框架基于一个关键假设:人类偏好背后的评估细则在不同的查询中表现出显著的泛化能力,这一特性实现了卓越的数据效率。我们的两阶段方法首先使用验证引导的Propose-Evaluate-Revise流程推断高质量的、特定于查询的细则。其次,它通过最大化信息论编码率将这些细粒度的细则泛化为紧凑的、非冗余的核心集。最终输出是一个可解释的、分层的“主题-提示”细则集。广泛的实验证明了该框架卓越的数据效率和性能。关键的是,仅使用70个偏好对(占源数据的1.5%),我们的方法也使像Qwen3-8B这样的小型模型能够胜过专门的、完全训练的同类模型。这项工作开创了一条可扩展、可解释且数据高效的奖励建模路径。
🔬 方法详解
问题定义:现有奖励模型训练依赖大量人工标注的偏好数据,成本高昂。同时,模型的可解释性较差,难以理解模型做出决策的原因。基于评分细则的方法虽然提高了可解释性,但缺乏系统的质量控制和优化,导致可扩展性和可靠性难以兼顾。
核心思路:论文的核心思路是利用人类在评估不同任务时,其潜在的评分细则具有一定的泛化能力。也就是说,即使是不同的query,人们在进行偏好判断时,所依据的评价标准(例如,流畅性、相关性、创造性等)可能存在共性。因此,可以通过少量数据学习到这些通用的评分准则,并将其应用于新的任务中,从而提高数据效率。
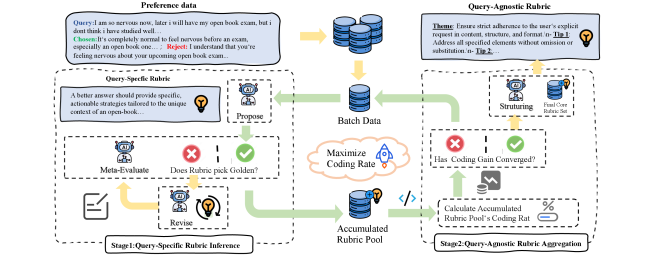
技术框架:Auto-Rubric框架主要包含两个阶段: 1. Propose-Evaluate-Revise (PER):针对每个query,生成query-specific的评分细则。该阶段通过迭代的方式,首先提出一些候选的评分细则,然后使用验证集进行评估,并根据评估结果对评分细则进行修正,最终得到高质量的、特定于query的评分细则。 2. Information-Theoretic Coding Rate Maximization:将第一阶段生成的细则泛化为一个紧凑的、非冗余的核心集。该阶段通过最大化信息论编码率,选择最具代表性的评分细则,并去除冗余的细则,最终得到一个可解释的、分层的“主题-提示”细则集。
关键创新:该方法最大的创新在于发现了人类偏好评估细则的泛化能力,并将其应用于奖励模型的训练中。与现有方法相比,该方法无需大量人工标注的偏好数据,即可训练出高性能的奖励模型。此外,该方法生成的评分细则具有良好的可解释性,可以帮助人们理解模型做出决策的原因。
关键设计: * Propose-Evaluate-Revise (PER) 流程:通过迭代的方式,不断优化评分细则的质量。 * 信息论编码率最大化:用于选择最具代表性的评分细则,并去除冗余的细则。 * “主题-提示”细则集:一种可解释的、分层的评分细则表示方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Auto-Rubric框架仅使用70个偏好对(占源数据的1.5%),即可使Qwen3-8B等小型模型在奖励建模任务中超越完全训练的专用模型。这充分证明了该框架的数据效率和泛化能力。此外,该框架生成的评分细则具有良好的可解释性,可以帮助人们理解模型做出决策的原因。
🎯 应用场景
该研究成果可应用于各种需要奖励模型的场景,例如对话系统、文本生成、代码生成等。通过减少对大量标注数据的依赖,降低了奖励模型训练的成本,并提高了模型的可解释性,有助于构建更安全、可靠和符合人类价值观的人工智能系统。未来,该方法可以进一步扩展到更复杂的任务和模态中。
📄 摘要(原文)
Reward models are essential for aligning Large Language Models (LLMs) with human values, yet their development is hampered by costly preference datasets and poor interpretability. While recent rubric-based approaches offer transparency, they often lack systematic quality control and optimization, creating a trade-off between scalability and reliability. We address these limitations with a novel, training-free framework built on a key assumption: \textit{evaluation rubrics underlying human preferences exhibit significant generalization ability across diverse queries}, a property that enables remarkable data efficiency. Our two-stage approach first infers high-quality, query-specific rubrics using a validation-guided \textbf{Propose-Evaluate-Revise} pipeline. Second, it generalizes these granular rubrics into a compact, non-redundant core set by maximizing an \textbf{information-theoretic coding rate}. The final output is an interpretable, hierarchical "Theme-Tips" rubric set. Extensive experiments demonstrate the framework's exceptional data efficiency and performance. Critically, using just 70 preference pairs (1.5\% of the source data), our method also empowers smaller models like Qwen3-8B to outperform specialized, fully-trained counterparts. This work pioneers a scalable, interpretable, and data-efficient path for reward modeling.