Peering Inside the Black Box: Uncovering LLM Errors in Optimization Modelling through Component-Level Evaluation
作者: Dania Refai, Moataz Ahmed
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-19
💡 一句话要点
提出组件级评估框架,诊断LLM在优化建模中的错误,提升模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 优化建模 组件级评估 错误诊断 精确率 召回率 均方根误差 提示工程
📋 核心要点
- 现有评估方法将LLM生成的优化公式视为整体,缺乏细粒度的错误诊断能力,难以发现结构性和数值性错误。
- 提出组件级评估框架,从决策变量、约束条件、目标函数等多个维度评估LLM生成的优化公式,实现更精准的错误定位。
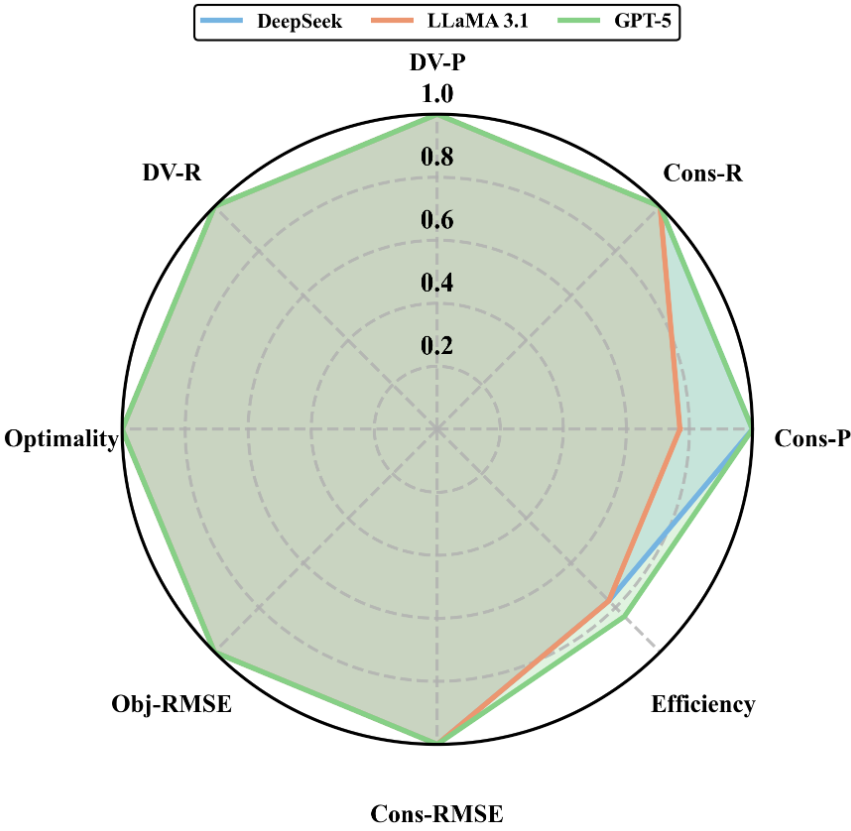
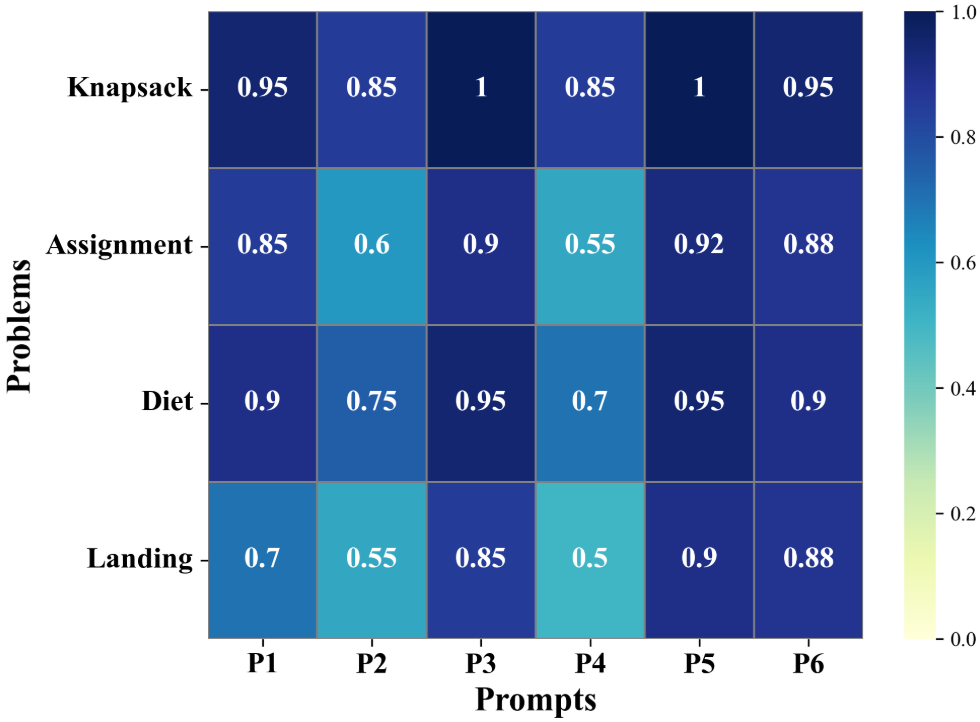
- 实验结果表明,GPT-5在多种提示策略下表现最佳,高约束召回率和低约束RMSE是保证求解器性能的关键因素。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于将自然语言描述转换为数学优化公式。目前的评估通常将公式视为一个整体,依赖于诸如解的准确性或运行时间等粗略指标,这掩盖了结构或数值错误。本研究提出了一个全面的、组件级的评估框架,用于评估LLM生成的公式。除了传统的optimality gap之外,我们的框架还引入了决策变量和约束的精确率和召回率、约束和目标函数的均方根误差(RMSE)以及基于token使用和延迟的效率指标。我们评估了GPT-5、LLaMA 3.1 Instruct和DeepSeek Math在不同复杂度的优化问题下,六种提示策略的表现。结果表明,GPT-5始终优于其他模型,并且思维链、自洽性和模块化提示被证明是最有效的。分析表明,求解器性能主要取决于高约束召回率和低约束RMSE,它们共同确保了结构正确性和解的可靠性。约束精确率和决策变量指标起次要作用,而简洁的输出可提高计算效率。这些发现强调了NLP到优化建模的三个原则:(i)完整的约束覆盖可防止违规,(ii)最小化约束RMSE可确保求解器级别的准确性,以及(iii)简洁的输出可提高计算效率。所提出的框架为优化建模中LLM的细粒度诊断评估奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在将自然语言描述转化为数学优化模型时产生的错误难以被有效诊断的问题。现有评估方法通常只关注最终解的准确性或运行时间等粗略指标,忽略了公式内部的结构性或数值性错误,导致难以改进LLM在优化建模任务中的表现。
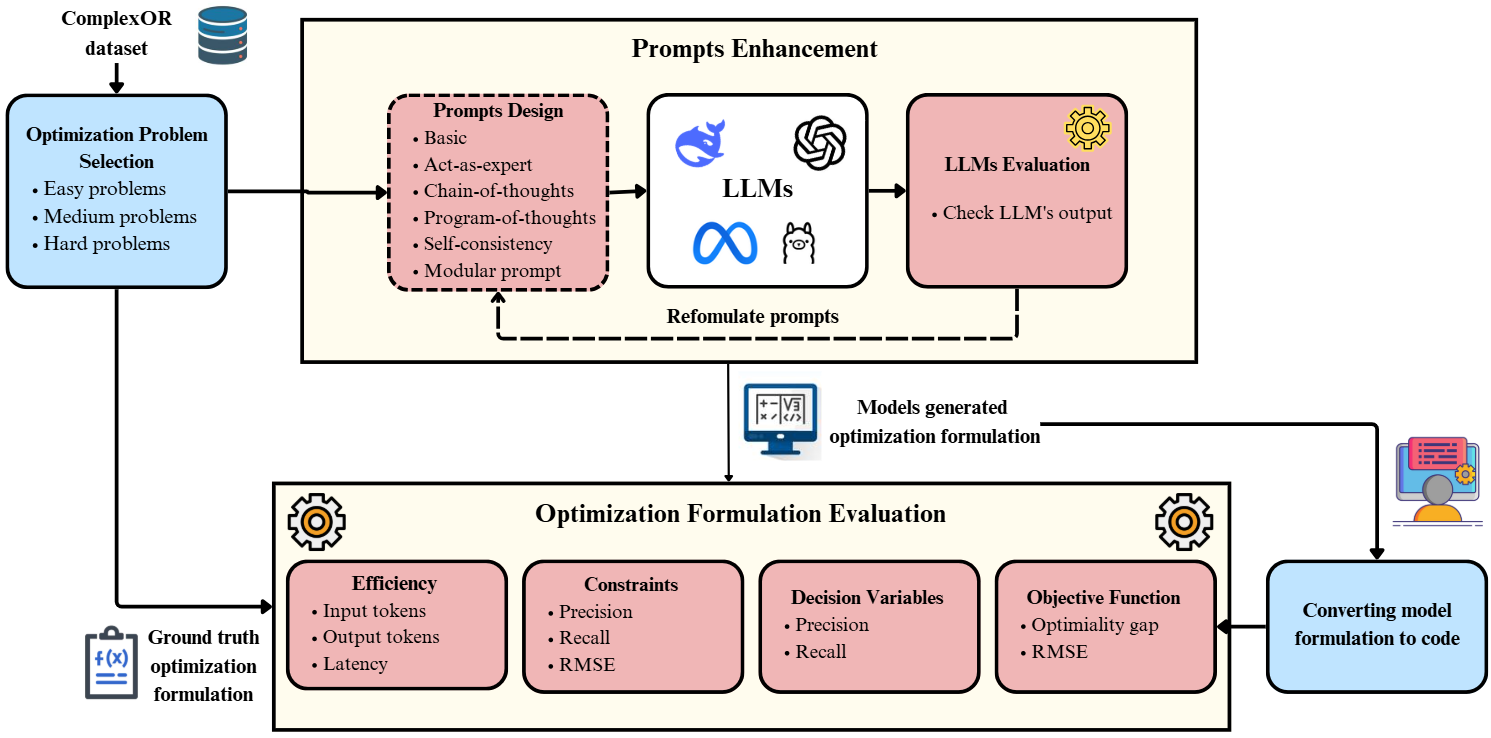
核心思路:论文的核心思路是将优化模型分解为多个组件(如决策变量、约束条件、目标函数),并针对每个组件设计细粒度的评估指标。通过对每个组件的性能进行评估,可以更精确地定位LLM在生成优化模型时产生的错误,从而为改进LLM提供更具体的指导。
技术框架:论文提出的评估框架包含以下几个主要模块:1) 公式生成:使用LLM将自然语言描述转化为数学优化公式。2) 组件分解:将生成的公式分解为决策变量、约束条件和目标函数等组件。3) 指标计算:针对每个组件,计算精确率、召回率、均方根误差(RMSE)等评估指标。4) 性能分析:分析各组件的性能指标,找出LLM在生成优化模型时的瓶颈和错误类型。
关键创新:论文最重要的技术创新点在于提出了一个组件级的评估框架,能够对LLM生成的优化模型进行细粒度的评估。与现有方法相比,该框架能够更精确地定位LLM在生成优化模型时产生的错误,为改进LLM提供更具体的指导。
关键设计:论文的关键设计包括:1) 针对决策变量和约束条件,设计了精确率和召回率等指标,用于评估LLM生成的公式的结构正确性。2) 针对约束条件和目标函数,设计了均方根误差(RMSE)等指标,用于评估LLM生成的公式的数值准确性。3) 考虑了token使用和延迟等效率指标,用于评估LLM生成公式的计算效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-5在所有模型中表现最佳,尤其是在结合思维链、自洽性和模块化提示策略时。研究发现,高约束召回率和低约束RMSE是保证求解器性能的关键因素。具体来说,约束召回率的提升能够有效防止约束违规,而约束RMSE的降低则能够提高求解器级别的准确性。
🎯 应用场景
该研究成果可应用于自动化优化建模领域,例如智能供应链管理、资源调度、金融投资组合优化等。通过该评估框架,可以更有效地评估和改进LLM在优化建模任务中的表现,从而提高自动化优化建模的效率和准确性,降低人工干预成本,并加速相关领域的智能化进程。
📄 摘要(原文)
Large language models (LLMs) are increasingly used to convert natural language descriptions into mathematical optimization formulations. Current evaluations often treat formulations as a whole, relying on coarse metrics like solution accuracy or runtime, which obscure structural or numerical errors. In this study, we present a comprehensive, component-level evaluation framework for LLM-generated formulations. Beyond the conventional optimality gap, our framework introduces metrics such as precision and recall for decision variables and constraints, constraint and objective root mean squared error (RMSE), and efficiency indicators based on token usage and latency. We evaluate GPT-5, LLaMA 3.1 Instruct, and DeepSeek Math across optimization problems of varying complexity under six prompting strategies. Results show that GPT-5 consistently outperforms other models, with chain-of-thought, self-consistency, and modular prompting proving most effective. Analysis indicates that solver performance depends primarily on high constraint recall and low constraint RMSE, which together ensure structural correctness and solution reliability. Constraint precision and decision variable metrics play secondary roles, while concise outputs enhance computational efficiency. These findings highlight three principles for NLP-to-optimization modeling: (i) Complete constraint coverage prevents violations, (ii) minimizing constraint RMSE ensures solver-level accuracy, and (iii) concise outputs improve computational efficiency. The proposed framework establishes a foundation for fine-grained, diagnostic evaluation of LLMs in optimization modeling.