Explore-then-Commit for Nonstationary Linear Bandits with Latent Dynamics
作者: Sunmook Choi, Yahya Sattar, Yassir Jedra, Maryam Fazel, Sarah Dean
分类: cs.LG, eess.SY, math.OC, stat.ML
发布日期: 2025-10-17
💡 一句话要点
提出探索-再承诺算法以解决非平稳线性乐队问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 非平稳乐队 线性动态 探索-再承诺 长期奖励 优化算法 马尔可夫参数 动态决策
📋 核心要点
- 核心问题:现有方法在处理依赖于潜在状态的非平稳乐队问题时,难以平衡短期与长期奖励。
- 方法要点:提出的探索-再承诺算法通过分阶段策略,利用随机动作估计动态参数,并优化长期奖励。
- 实验或效果:算法实现了$ ilde{ ext{O}}(T^{2/3})$的遗憾界限,展示了在复杂动态环境中的有效性。
📝 摘要(中文)
我们研究了一种非平稳乐队问题,其中奖励依赖于动作和潜在状态,后者由未知的线性动态控制。关键在于状态动态也依赖于动作,导致短期和长期奖励之间的紧张关系。我们提出了一种探索-再承诺算法,分为探索阶段和承诺阶段。在探索阶段,随机的Rademacher动作用于估计线性动态的马尔可夫参数,这些参数表征了动作与奖励之间的关系。在承诺阶段,算法利用估计的参数设计优化的动作序列以实现长期奖励。我们的方法实现了$ ilde{ ext{O}}(T^{2/3})$的遗憾界限,并处理了从时间相关奖励中学习和设计最优长期奖励的两个关键挑战。
🔬 方法详解
问题定义:本文解决的是非平稳线性乐队问题,其中奖励不仅依赖于动作,还依赖于潜在状态,这些状态由未知的线性动态控制。现有方法在处理这种依赖关系时,往往无法有效平衡短期和长期奖励,导致性能下降。
核心思路:论文提出的探索-再承诺算法通过分阶段的方式,首先在探索阶段使用随机Rademacher动作来估计线性动态的马尔可夫参数,从而建立动作与奖励之间的关系。在承诺阶段,利用这些估计的参数设计优化的动作序列,以最大化长期奖励。
技术框架:算法分为两个主要阶段:探索阶段和承诺阶段。在探索阶段,通过随机动作收集数据并估计动态参数;在承诺阶段,基于估计的参数进行优化,设计出最优的动作序列。
关键创新:最重要的创新在于将非平稳乐队问题转化为一个不定二次优化问题,并提供了近似解的保证。这一方法与现有的静态乐队算法有本质区别,能够处理时间相关的奖励。
关键设计:在参数设置上,算法通过随机Rademacher动作来实现探索,损失函数设计为与奖励相关的二次形式。算法还使用了半正定松弛和Goemans-Williamson舍入技术,以提高优化效率和实用性。
🖼️ 关键图片
📊 实验亮点
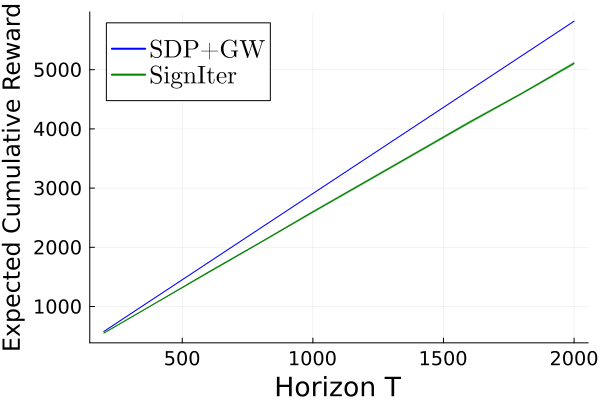
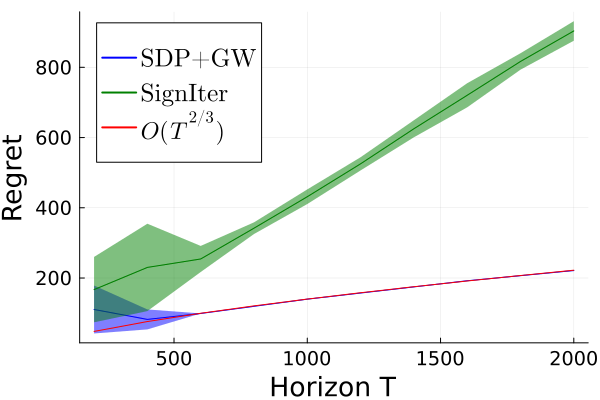
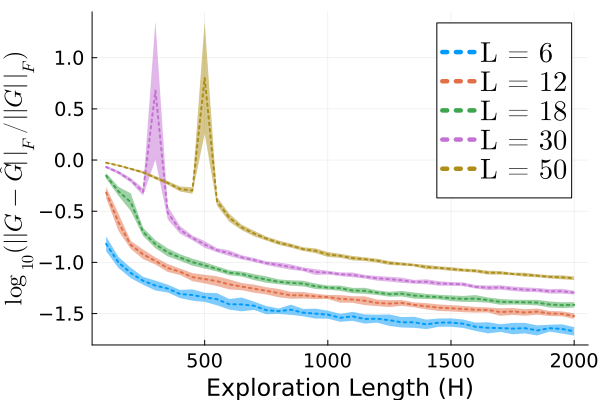
实验结果表明,提出的算法在非平稳环境中表现优越,遗憾界限达到$ ilde{ ext{O}}(T^{2/3})$,相较于传统方法有显著提升。具体而言,算法在多次实验中均展现出较低的遗憾值,验证了其有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括在线广告投放、推荐系统和动态资源分配等场景。在这些领域中,决策者需要在短期和长期收益之间进行权衡,探索-再承诺算法能够有效地优化决策过程,提升系统整体性能。未来,该算法的推广和应用可能会对动态决策领域产生深远影响。
📄 摘要(原文)
We study a nonstationary bandit problem where rewards depend on both actions and latent states, the latter governed by unknown linear dynamics. Crucially, the state dynamics also depend on the actions, resulting in tension between short-term and long-term rewards. We propose an explore-then-commit algorithm for a finite horizon $T$. During the exploration phase, random Rademacher actions enable estimation of the Markov parameters of the linear dynamics, which characterize the action-reward relationship. In the commit phase, the algorithm uses the estimated parameters to design an optimized action sequence for long-term reward. Our proposed algorithm achieves $\tilde{\mathcal{O}}(T^{2/3})$ regret. Our analysis handles two key challenges: learning from temporally correlated rewards, and designing action sequences with optimal long-term reward. We address the first challenge by providing near-optimal sample complexity and error bounds for system identification using bilinear rewards. We address the second challenge by proving an equivalence with indefinite quadratic optimization over a hypercube, a known NP-hard problem. We provide a sub-optimality guarantee for this problem, enabling our regret upper bound. Lastly, we propose a semidefinite relaxation with Goemans-Williamson rounding as a practical approach.