Alignment is Localized: A Causal Probe into Preference Layers
作者: Archie Chaudhury
分类: cs.LG, cs.CL
发布日期: 2025-10-17
💡 一句话要点
通过因果探针揭示偏好层局部对齐现象,优化语言模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 人类反馈强化学习 因果推断 层级分析 偏好优化
📋 核心要点
- 现有基于人类反馈的强化学习(RLHF)对齐方法,其内部工作机制仍然不够透明,缺乏对对齐过程的深入理解。
- 该论文提出了一种基于层级因果修补的方法,通过分析模型不同层之间的因果关系,来研究偏好优化对语言模型对齐的影响。
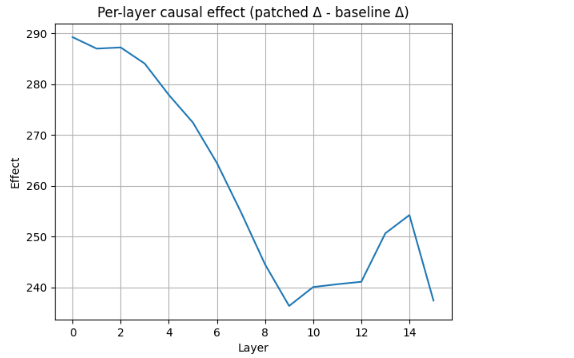
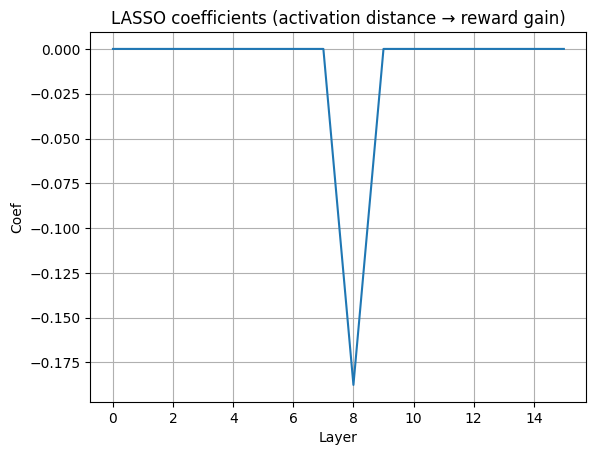
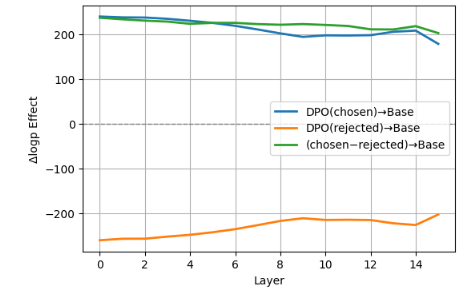
- 实验结果表明,对齐过程在模型中是局部化的,主要集中在中间层,并且是一个低秩过程,而非扩散式的参数调整。
📝 摘要(中文)
本文深入研究了语言模型对齐中的偏好优化过程,尤其关注利用人类反馈的强化学习(RLHF)方法。通过在基础模型及其微调版本之间应用层级因果修补,系统性地分析了人类偏好对齐的影响。实验基于Llama-3.2-1B模型,发现对齐过程在空间上是局部化的:中间层激活编码了一个独特的子空间,该子空间因果地决定了与奖励一致的行为,而早期和后期层则基本不受影响。利用LASSO回归,还发现只有少数层具有非零系数,将激活距离与奖励增益联系起来。总而言之,研究表明,至少对于某些语言模型而言,基于人类偏好的微调所实现的对齐是一个定向的、低秩的过程,而不是扩散的和参数化的。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法在对齐语言模型时,其内部机制如同黑盒,难以理解哪些层负责对齐,以及对齐是如何实现的。现有方法缺乏对对齐过程的细粒度分析,无法有效指导模型对齐的优化。
核心思路:该论文的核心思路是通过因果干预来探究模型内部不同层对对齐的贡献。具体来说,通过将微调模型的激活状态注入到基础模型的不同层中,观察模型行为的变化,从而确定哪些层对奖励一致的行为具有因果影响。这种方法能够揭示对齐过程在模型中的空间分布。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择一个基础语言模型(Llama-3.2-1B)和一个经过人类偏好微调后的对齐模型。2) 构建人类偏好对,包含模型输出和对应的奖励。3) 对模型进行层级因果修补,即将对齐模型的某一层激活替换基础模型的对应层激活。4) 评估修补后的模型在偏好对上的表现,计算奖励变化。5) 使用LASSO回归分析激活距离与奖励增益之间的关系,确定关键层。
关键创新:该论文的关键创新在于使用因果修补的方法来研究语言模型对齐过程。与传统的参数分析方法不同,因果修补能够直接揭示不同层对模型行为的因果影响,从而更准确地定位对齐的关键层。此外,该研究还发现对齐过程是一个低秩过程,这意味着只需要调整模型的一小部分参数就可以实现有效的对齐。
关键设计:在因果修补过程中,关键的设计包括:1) 选择合适的激活替换策略,确保替换后的模型能够正常运行。2) 使用LASSO回归来识别与奖励增益相关的关键层,并控制模型的复杂度。3) 精确计算奖励变化,以评估不同层的因果影响。此外,实验还仔细选择了人类偏好对,以确保评估结果的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Llama-3.2-1B模型的对齐过程主要集中在中间层,这些层的激活编码了一个独特的子空间,对奖励一致的行为具有因果影响。LASSO回归分析发现,只有少数层具有非零系数,将激活距离与奖励增益联系起来。这些发现表明,对齐是一个定向的、低秩的过程,而非扩散式的参数调整。
🎯 应用场景
该研究成果可应用于提升语言模型对齐效率和可控性。通过了解对齐的关键层,可以更有针对性地进行模型微调,减少计算资源消耗。此外,该研究还有助于开发更安全、更符合人类价值观的语言模型,降低模型产生有害或不当内容的风险。未来,该方法可以推广到其他类型的语言模型和对齐任务中。
📄 摘要(原文)
Reinforcement Learning frameworks, particularly those utilizing human annotations, have become an increasingly popular method for preference fine-tuning, where the outputs of a language model are tuned to match a certain set of behavioral policies or guidelines. Reinforcement Learning through Human Feedback (RLHF) is perhaps the most popular implementation of such a framework, particularly for aligning LMs toward safety and human intent. However, the internal workings of how such alignment is achieved remain largely opaque. In this work, we systematically analyze preference optimization for language model alignment by applying layer-wide causal patching between a base model and its tuned counterpart across human preference pairs. We implement our methodology on \textit{Llama-3.2-1B}, and find that alignment is spatially localized: mid-layer activations encode a distinct subspace that causally determines reward-consistent behavior, while early and late layers remain largely unaffected. Utilizing LASSO regression, we also find that only a small number of layers possess non-zero coefficients linking activation distances to reward gains. Overall, we show that, at least for some language models, alignment from human-based, preferential tuning is a directional, low rank process, rather than diffuse and parameteric.