Towards Robust Zero-Shot Reinforcement Learning
作者: Kexin Zheng, Lauriane Teyssier, Yinan Zheng, Yu Luo, Xianyuan Zhan
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-17 (更新: 2025-10-23)
备注: Neurips 2025, 29 pages, 19 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出BREEZE,增强零样本强化学习的鲁棒性和泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本强化学习 离线强化学习 行为正则化 扩散模型 注意力机制
📋 核心要点
- 现有基于FB的零样本强化学习方法表达能力不足,离线学习中OOD动作导致表示偏差,影响性能。
- BREEZE通过行为正则化提升学习稳定性,使用任务条件扩散模型提取策略,增强表示学习质量。
- 实验表明,BREEZE在ExORL和D4RL Kitchen数据集上表现出优越的性能和鲁棒性。
📝 摘要(中文)
本文提出了一种名为Behavior-REgularizEd Zero-shot RL with Expressivity enhancement (BREEZE) 的框架,旨在提升零样本强化学习的鲁棒性。研究发现,基于Forward-Backward representations (FB) 的方法存在表达能力不足的问题,并且离线学习中由分布外(OOD)动作引起的推断误差会导致有偏的表示,从而影响性能。BREEZE通过行为正则化增强学习稳定性,利用任务条件扩散模型提取高质量策略,并采用基于注意力机制的架构来建模环境动态的复杂关系。在ExORL和D4RL Kitchen数据集上的实验表明,BREEZE在性能上达到最佳或接近最佳水平,并展现出比现有离线零样本强化学习方法更强的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决零样本强化学习中,现有方法(特别是基于Forward-Backward representations的方法)的鲁棒性问题。现有方法的痛点在于表达能力不足,无法充分捕捉环境动态的复杂关系;同时,离线学习过程中,由于策略可能采取训练数据中未出现的(out-of-distribution, OOD)动作,导致学习到的表示存在偏差,最终影响策略的泛化能力。
核心思路:论文的核心思路是通过行为正则化来约束策略的学习过程,使其更稳定,避免采取过多的OOD动作。同时,利用更具表达能力的模型(基于注意力机制的架构)来学习环境的表示,并使用任务条件扩散模型来提取高质量的策略。这样可以提高策略的泛化能力和鲁棒性,使其能够更好地适应新的任务。
技术框架:BREEZE框架主要包含三个关键模块:1) 行为正则化模块,用于约束策略的学习,使其更稳定;2) 基于注意力机制的表示学习模块,用于学习环境动态的复杂表示;3) 任务条件扩散模型,用于从学习到的表示中提取高质量的策略。整体流程是:首先,利用离线数据学习环境的表示;然后,使用行为正则化约束的策略学习算法来优化策略;最后,使用任务条件扩散模型从学习到的表示中提取策略。
关键创新:BREEZE的关键创新在于三个方面:1) 引入了行为正则化,将策略优化转化为一个更稳定的同分布学习范式;2) 使用任务条件扩散模型来提取策略,能够生成高质量和多模态的动作分布;3) 采用基于注意力机制的架构来建模环境动态,提高了表示学习的质量。与现有方法的本质区别在于,BREEZE更加注重学习的稳定性和表示的表达能力,从而提高了零样本强化学习的鲁棒性。
关键设计:行为正则化模块使用KL散度来约束策略的输出分布与数据集中的行为分布之间的差异。任务条件扩散模型使用U-Net架构,以任务描述作为条件输入,生成动作序列。基于注意力机制的表示学习模块使用Transformer架构,捕捉环境状态之间的长期依赖关系。损失函数包括行为正则化损失、扩散模型损失和表示学习损失。具体的参数设置和网络结构细节可以在论文的实现代码中找到。
🖼️ 关键图片
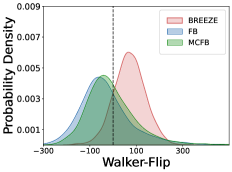
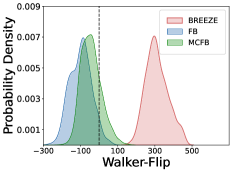

📊 实验亮点
实验结果表明,BREEZE在ExORL和D4RL Kitchen数据集上取得了最佳或接近最佳的性能,并且展现出比现有离线零样本强化学习方法更强的鲁棒性。具体来说,BREEZE在多个任务上的成功率显著高于其他基线方法,并且在面对噪声和干扰时,能够保持较好的性能。
🎯 应用场景
BREEZE在机器人控制、游戏AI、自动驾驶等领域具有广泛的应用前景。它可以用于训练能够适应各种新任务的通用策略,从而降低了开发和部署强化学习应用的成本。例如,在机器人控制中,可以使用BREEZE训练一个能够完成各种不同操作任务的机器人;在自动驾驶中,可以使用BREEZE训练一个能够适应各种交通场景的自动驾驶系统。
📄 摘要(原文)
The recent development of zero-shot reinforcement learning (RL) has opened a new avenue for learning pre-trained generalist policies that can adapt to arbitrary new tasks in a zero-shot manner. While the popular Forward-Backward representations (FB) and related methods have shown promise in zero-shot RL, we empirically found that their modeling lacks expressivity and that extrapolation errors caused by out-of-distribution (OOD) actions during offline learning sometimes lead to biased representations, ultimately resulting in suboptimal performance. To address these issues, we propose Behavior-REgularizEd Zero-shot RL with Expressivity enhancement (BREEZE), an upgraded FB-based framework that simultaneously enhances learning stability, policy extraction capability, and representation learning quality. BREEZE introduces behavioral regularization in zero-shot RL policy learning, transforming policy optimization into a stable in-sample learning paradigm. Additionally, BREEZE extracts the policy using a task-conditioned diffusion model, enabling the generation of high-quality and multimodal action distributions in zero-shot RL settings. Moreover, BREEZE employs expressive attention-based architectures for representation modeling to capture the complex relationships between environmental dynamics. Extensive experiments on ExORL and D4RL Kitchen demonstrate that BREEZE achieves the best or near-the-best performance while exhibiting superior robustness compared to prior offline zero-shot RL methods. The official implementation is available at: https://github.com/Whiterrrrr/BREEZE.