Simplicial Embeddings Improve Sample Efficiency in Actor-Critic Agents
作者: Johan Obando-Ceron, Walter Mayor, Samuel Lavoie, Scott Fujimoto, Aaron Courville, Pablo Samuel Castro
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-15
💡 一句话要点
提出基于单纯复形嵌入的强化学习方法,提升Actor-Critic算法的样本效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Actor-Critic 样本效率 单纯复形嵌入 几何归纳偏置
📋 核心要点
- 现有Actor-Critic方法虽然利用环境并行化加速训练,但仍需大量样本,样本效率有待提高。
- 论文提出单纯复形嵌入,通过几何归纳偏置生成稀疏离散特征,稳定评论家引导并增强策略梯度。
- 实验表明,在FastTD3、FastSAC和PPO中应用单纯复形嵌入,可显著提升样本效率和最终性能。
📝 摘要(中文)
本文提出了一种利用单纯复形嵌入来加速Actor-Critic方法训练的技术。现有方法虽然通过大规模环境并行化来缩短训练时间,但仍需大量的环境交互才能达到理想性能。本文观察到良好结构化的表示可以提高深度强化学习(RL)智能体的泛化能力和样本效率,因此引入单纯复形嵌入:一种轻量级的表示层,它将嵌入约束到单纯复形结构。这种几何归纳偏置产生稀疏和离散的特征,从而稳定评论家引导并增强策略梯度。将单纯复形嵌入应用于FastTD3、FastSAC和PPO时,在各种连续和离散控制环境中,都能持续提高样本效率和最终性能,且不损失运行速度。
🔬 方法详解
问题定义:现有Actor-Critic算法,即使通过大规模环境并行化加速训练,仍然需要大量的环境交互才能达到期望的性能水平,样本效率较低。如何提高Actor-Critic算法的样本效率,减少训练所需的交互次数,是本文要解决的核心问题。
核心思路:论文的核心思路是利用单纯复形嵌入(Simplicial Embeddings)来约束智能体的表示空间。通过引入几何归纳偏置,使得学习到的特征具有稀疏性和离散性,从而稳定评论家(Critic)的引导过程,并增强策略梯度,最终提高样本效率。这种方法旨在利用几何结构来改善表示学习,从而提升强化学习的性能。
技术框架:整体框架是在现有的Actor-Critic算法(如FastTD3、FastSAC、PPO)中,在输入层之后添加一个单纯复形嵌入层。该嵌入层将原始输入映射到单纯复形结构中,生成稀疏且离散的特征表示。然后,这些特征表示被输入到后续的Actor和Critic网络中进行训练。整个流程保持了原有Actor-Critic算法的结构,只是在表示学习阶段引入了单纯复形嵌入。
关键创新:最关键的创新点在于单纯复形嵌入的使用。与传统的稠密嵌入相比,单纯复形嵌入通过几何约束,强制学习到的特征具有稀疏性和离散性。这种稀疏离散的表示方式,能够更好地捕捉环境中的关键信息,减少冗余,从而提高样本效率。与现有方法的本质区别在于,它不是直接优化策略或价值函数,而是通过改善表示学习来间接提升性能。
关键设计:单纯复形嵌入层的具体实现涉及将输入数据映射到单纯复形的顶点上,并定义顶点之间的连接关系。关键参数包括单纯复形的维度、顶点数量以及连接规则。损失函数方面,除了原有的Actor-Critic损失函数外,可能还会引入正则化项,以鼓励学习到的嵌入具有期望的稀疏性和离散性。具体的网络结构取决于所使用的Actor-Critic算法,但单纯复形嵌入层通常作为输入层的一部分存在。
🖼️ 关键图片


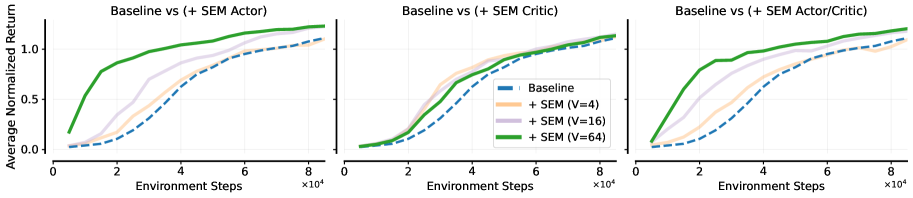
📊 实验亮点
实验结果表明,在多种连续和离散控制环境中,将单纯复形嵌入应用于FastTD3、FastSAC和PPO算法,均能显著提高样本效率和最终性能。具体而言,在某些任务上,使用单纯复形嵌入的算法能够以更少的环境交互次数达到与基线算法相同的性能水平,甚至超越基线算法的最终性能。
🎯 应用场景
该研究成果可广泛应用于机器人控制、游戏AI、自动驾驶等需要高效学习的强化学习任务中。通过提高样本效率,可以降低训练成本,加速算法落地。未来,该方法有望与其他表示学习技术结合,进一步提升强化学习的性能和泛化能力,例如探索更复杂的几何结构或自适应地调整单纯复形的参数。
📄 摘要(原文)
Recent works have proposed accelerating the wall-clock training time of actor-critic methods via the use of large-scale environment parallelization; unfortunately, these can sometimes still require large number of environment interactions to achieve a desired level of performance. Noting that well-structured representations can improve the generalization and sample efficiency of deep reinforcement learning (RL) agents, we propose the use of simplicial embeddings: lightweight representation layers that constrain embeddings to simplicial structures. This geometric inductive bias results in sparse and discrete features that stabilize critic bootstrapping and strengthen policy gradients. When applied to FastTD3, FastSAC, and PPO, simplicial embeddings consistently improve sample efficiency and final performance across a variety of continuous- and discrete-control environments, without any loss in runtime speed.