Data-driven learning of feedback maps for explicit robust predictive control: an approximation theoretic view
作者: Siddhartha Ganguly, Shubham Gupta, Debasish Chatterjee
分类: math.OC, cs.LG, eess.SY
发布日期: 2025-10-15
备注: 27 pages; submitted
💡 一句话要点
提出一种数据驱动的鲁棒预测控制反馈映射学习算法,保证递归可行性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 鲁棒模型预测控制 数据驱动控制 反馈映射学习 近似理论 递归可行性
📋 核心要点
- 传统鲁棒MPC计算复杂度高,难以实时应用,数据驱动方法可以降低计算负担,但难以保证鲁棒性和可行性。
- 该论文提出一种数据驱动的反馈映射学习算法,直接在设计阶段考虑近似误差,确保控制器的递归可行性。
- 通过数值实验验证了所提算法的有效性,在保证稳定性的前提下,实现了对鲁棒MPC的近似。
📝 摘要(中文)
本文提出了一种从数据中学习反馈映射的算法,用于解决一类鲁棒模型预测控制(MPC)问题。该算法在综合阶段直接考虑了学习带来的近似误差,从而保证了递归可行性。所考虑的最优控制问题包含一个线性噪声动态系统,一个二次阶段成本和一个二次终端成本作为目标函数,以及状态、控制和扰动序列上的凸约束;控制最小化目标函数,而扰动最大化目标函数。算法分为两个步骤:(a)数据生成:首先,将给定的minmax问题重新表述为一个凸半无限规划问题,并利用最近开发的工具在状态空间的网格点上精确地解决它,以生成(状态,动作)数据。(b)学习近似反馈映射:采用几种近似方案,在可容许的状态空间内提供预先指定的均匀误差界限内的紧密近似,以学习未知的反馈策略。在标准假设下,近似反馈策略下闭环系统的稳定性也得到了保证。提供了两个基准数值例子来说明结果。
🔬 方法详解
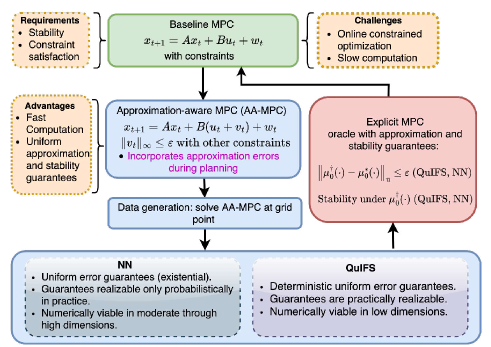
问题定义:论文旨在解决线性噪声动态系统下的鲁棒模型预测控制问题,该问题具有二次型成本函数和凸约束。传统的鲁棒MPC方法通常需要求解复杂的min-max优化问题,计算量大,难以满足实时性要求。数据驱动的方法可以降低计算复杂度,但如何保证学习到的控制策略的鲁棒性和递归可行性是一个挑战。
核心思路:论文的核心思路是通过数据驱动的方式学习反馈映射,从而近似求解鲁棒MPC问题。为了保证鲁棒性和递归可行性,该算法在学习过程中直接考虑了近似误差,并将其纳入控制器的设计中。具体来说,通过将min-max问题转化为凸半无限规划问题,并在状态空间网格点上精确求解,生成训练数据。然后,利用近似理论学习反馈映射,并保证近似误差在预先设定的范围内。
技术框架:该方法主要包含两个阶段:(1)数据生成阶段:将鲁棒MPC问题转化为凸半无限规划问题,并在状态空间网格点上求解,得到状态-控制数据对。(2)反馈映射学习阶段:利用近似理论,如径向基函数或多项式回归,学习从状态到控制的映射。在学习过程中,需要考虑近似误差,并将其纳入控制器的设计中,以保证鲁棒性和递归可行性。
关键创新:该论文的关键创新在于将近似误差直接纳入控制器设计中,从而保证了学习到的控制策略的鲁棒性和递归可行性。传统的基于数据驱动的控制方法通常忽略近似误差,导致控制性能下降甚至不稳定。该论文通过理论分析和算法设计,有效地解决了这个问题。
关键设计:在数据生成阶段,需要选择合适的网格点和求解器,以保证数据的质量和精度。在反馈映射学习阶段,需要选择合适的近似方法和误差界限,以保证控制器的性能和鲁棒性。此外,还需要设计合适的损失函数,以最小化近似误差,并保证控制器的稳定性。
🖼️ 关键图片
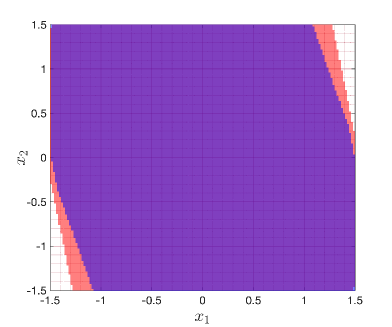
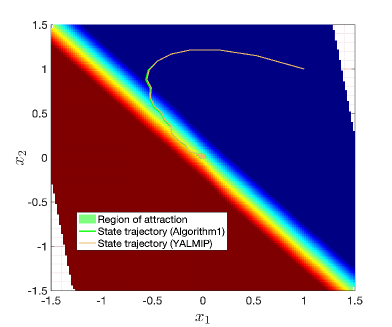
📊 实验亮点
论文通过两个基准数值例子验证了所提算法的有效性。实验结果表明,该算法能够在保证稳定性的前提下,有效地近似鲁棒MPC,并降低计算复杂度。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要鲁棒控制的场景,例如机器人控制、自动驾驶、电力系统控制等。通过数据驱动的方式学习控制策略,可以降低计算复杂度,提高控制系统的实时性和适应性。此外,该方法还可以应用于不确定性较大的系统,提高控制系统的鲁棒性。
📄 摘要(原文)
We establish an algorithm to learn feedback maps from data for a class of robust model predictive control (MPC) problems. The algorithm accounts for the approximation errors due to the learning directly at the synthesis stage, ensuring recursive feasibility by construction. The optimal control problem consists of a linear noisy dynamical system, a quadratic stage and quadratic terminal costs as the objective, and convex constraints on the state, control, and disturbance sequences; the control minimizes and the disturbance maximizes the objective. We proceed via two steps -- (a) Data generation: First, we reformulate the given minmax problem into a convex semi-infinite program and employ recently developed tools to solve it in an exact fashion on grid points of the state space to generate (state, action) data. (b) Learning approximate feedback maps: We employ a couple of approximation schemes that furnish tight approximations within preassigned uniform error bounds on the admissible state space to learn the unknown feedback policy. The stability of the closed-loop system under the approximate feedback policies is also guaranteed under a standard set of hypotheses. Two benchmark numerical examples are provided to illustrate the results.