A New Perspective on Transformers in Online Reinforcement Learning for Continuous Control
作者: Nikita Kachaev, Daniil Zelezetsky, Egor Cherepanov, Alexey K. Kovelev, Aleksandr I. Panov
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-15
💡 一句话要点
探索Transformer在在线强化学习连续控制中的应用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Transformer 强化学习 连续控制 在线学习 Actor-Critic
📋 核心要点
- 在线无模型强化学习中,Transformer对训练设置敏感,策略和价值网络的设计缺乏明确指导。
- 本文探索了Transformer在在线强化学习连续控制中的应用,并研究了输入调节、组件共享和数据切片等关键设计问题。
- 实验结果表明,通过稳定的架构和训练策略,Transformer可以在多种任务和设置中实现有竞争力的性能。
📝 摘要(中文)
尽管Transformer在离线或基于模型的强化学习(RL)中表现出色且应用广泛,但由于其对训练设置和模型设计决策的敏感性,例如如何构建策略和价值网络、共享组件或处理时间信息,Transformer在在线无模型RL中的应用仍未得到充分探索。本文表明,Transformer可以作为在线无模型RL中连续控制的强大基线。我们研究了关键的设计问题:如何调节输入、在actor和critic之间共享组件以及如何对顺序数据进行切片以进行训练。我们的实验揭示了稳定的架构和训练策略,从而在完全和部分可观察的任务中以及在基于向量和图像的设置中实现有竞争力的性能。这些发现为在在线RL中应用Transformer提供了实践指导。
🔬 方法详解
问题定义:论文旨在解决在线无模型强化学习中,Transformer应用于连续控制任务时面临的挑战。现有方法在设计Transformer架构(如策略网络和价值网络)时缺乏明确的指导,导致训练不稳定,性能难以保证。尤其是在如何有效处理时间序列信息、共享actor和critic组件等方面存在不足。
核心思路:论文的核心思路是系统性地研究Transformer在在线强化学习中的应用,通过实验分析不同的架构设计和训练策略,找到适用于连续控制任务的稳定且高效的Transformer配置。重点关注输入调节、actor-critic组件共享以及序列数据切片等关键因素。
技术框架:整体框架基于标准的actor-critic强化学习算法,其中actor和critic均采用Transformer架构。输入状态(向量或图像)首先经过预处理,然后输入到Transformer编码器中。编码器的输出用于生成策略(actor)和价值函数(critic)。论文探索了不同的组件共享策略,例如共享部分或全部Transformer层。训练过程采用标准的强化学习算法,如PPO或SAC。
关键创新:论文的主要创新在于对Transformer在在线强化学习中的应用进行了系统性的研究和实验分析,并提出了适用于连续控制任务的稳定架构和训练策略。与以往研究相比,本文更加关注实际应用中的工程细节和设计选择,并提供了具体的实践指导。
关键设计:论文研究了多种关键设计,包括:1) 输入调节方式:例如使用embedding层将状态向量或图像特征映射到Transformer的输入空间。2) Actor-critic组件共享策略:例如共享Transformer编码器的前几层,而actor和critic分别拥有独立的输出层。3) 序列数据切片方式:例如使用固定长度的滑动窗口对时间序列数据进行切片,并使用masking机制处理序列边界。4) 损失函数:采用标准的策略梯度损失函数和价值函数损失函数,并根据具体任务进行调整。
🖼️ 关键图片
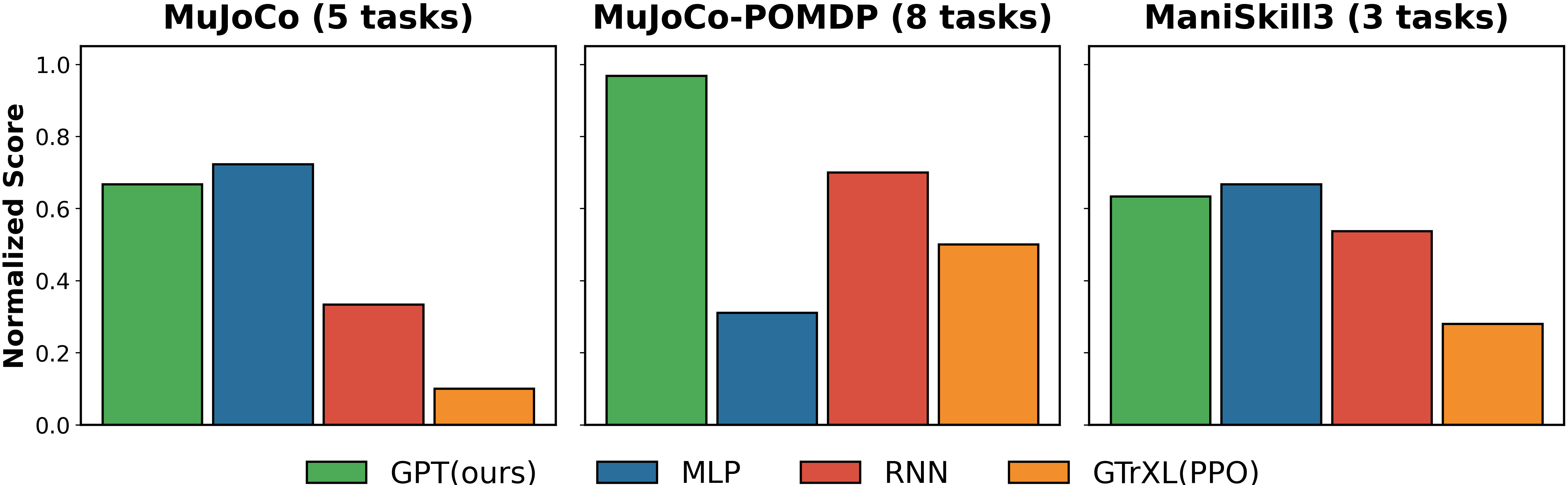
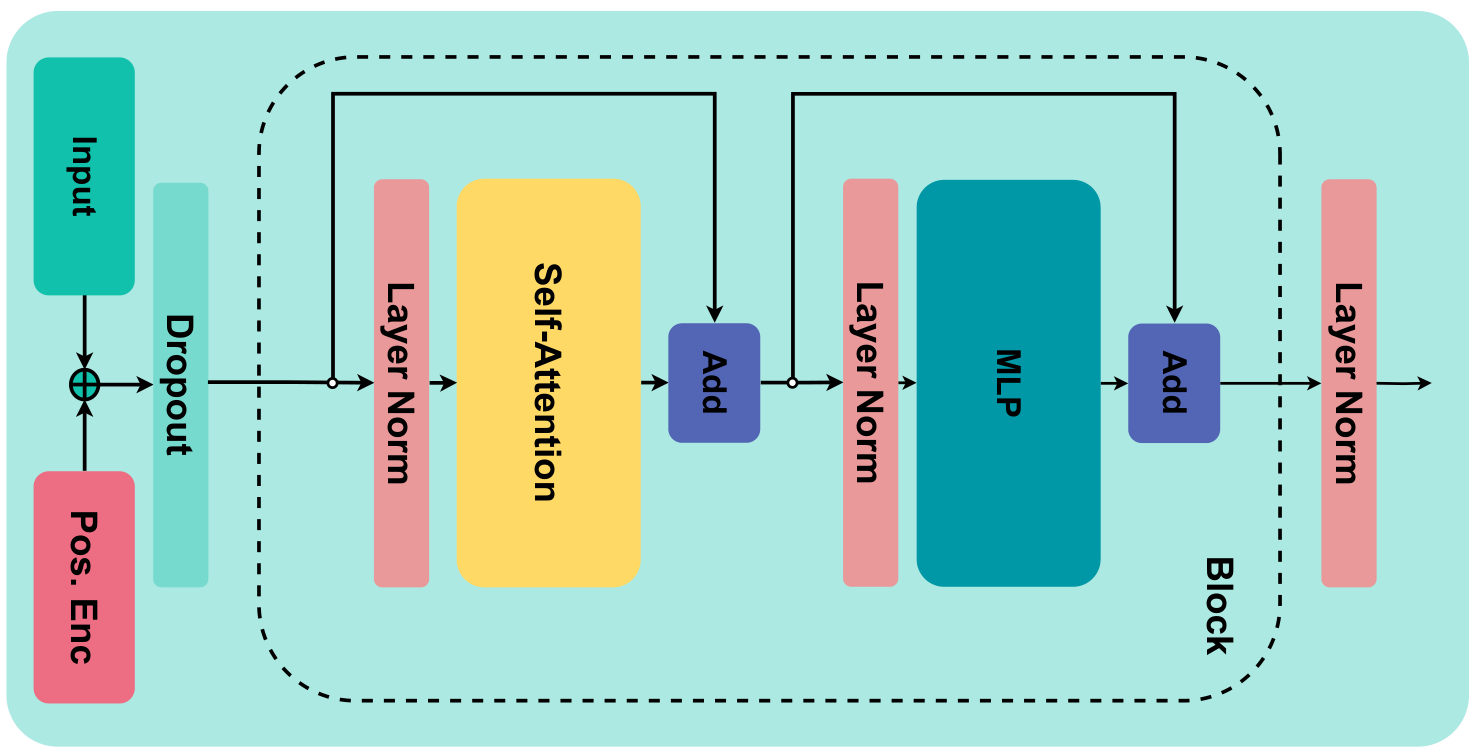

📊 实验亮点
实验结果表明,通过合理的架构设计和训练策略,Transformer可以在多种连续控制任务中取得与传统方法(如MLP)相当甚至更好的性能。特别是在部分可观察的任务中,Transformer能够更好地利用历史信息,从而提升智能体的鲁棒性和适应性。论文还提供了不同设计选择的性能对比,为实际应用提供了有价值的参考。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过使用Transformer作为策略网络,可以提升智能体在复杂环境中的决策能力和控制精度。此外,该研究提供的实践指导可以帮助研究人员和工程师更有效地将Transformer应用于在线强化学习任务中,加速相关领域的发展。
📄 摘要(原文)
Despite their effectiveness and popularity in offline or model-based reinforcement learning (RL), transformers remain underexplored in online model-free RL due to their sensitivity to training setups and model design decisions such as how to structure the policy and value networks, share components, or handle temporal information. In this paper, we show that transformers can be strong baselines for continuous control in online model-free RL. We investigate key design questions: how to condition inputs, share components between actor and critic, and slice sequential data for training. Our experiments reveal stable architectural and training strategies enabling competitive performance across fully and partially observable tasks, and in both vector- and image-based settings. These findings offer practical guidance for applying transformers in online RL.