Can GRPO Help LLMs Transcend Their Pretraining Origin?
作者: Kangqi Ni, Zhen Tan, Zijie Liu, Pingzhi Li, Tianlong Chen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-14
💡 一句话要点
研究表明GRPO对LLM的增强受限于预训练偏差,仅能微调而非创造新能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 分布外泛化 预训练偏差 推理能力
📋 核心要点
- 现有基于GRPO的强化学习方法在提升LLM推理能力时表现不稳定,缺乏对泛化能力的深入理解。
- 论文证明GRPO本质上是一种保守的重加权策略,其性能提升受限于预训练数据的分布偏差。
- 通过实验验证,GRPO仅在目标任务与预训练偏差对齐时才能实现分布外泛化,否则效果有限。
📝 摘要(中文)
本文研究了基于可验证奖励的强化学习(RLVR),特别是Group Relative Policy Optimization (GRPO)算法,在提升大型语言模型(LLM)推理能力方面的作用。尽管GRPO被广泛采用,但其效果并不稳定,例如,模型在数学推理方面可能显著提升,但在医学领域却停滞不前。本文从数据分布的角度探讨了GRPO改进推理和泛化到分布外(OOD)的条件。理论证明GRPO是一种保守的重加权方案,受限于基础模型的分布,无法发现全新的解决方案。通过精心设计的受控实验,从头训练Transformer,并评估其在推理深度、输入长度、token表示和组合性方面的泛化能力,验证了这一结论。结果表明,OOD改进仅在目标任务与模型的预训练偏差一致时才会出现,而分布内(ID)任务的收益会随着性能饱和而减少。因此,GRPO并非通用的推理增强器,而是强化预训练偏差的工具。研究结果推动了超越模型预训练起源的算法的未来发展。
🔬 方法详解
问题定义:现有方法,特别是基于GRPO的强化学习方法,在提升大型语言模型(LLM)的推理能力时,效果并不稳定且缺乏可解释性。一个关键的痛点是,我们不清楚GRPO在什么条件下能够有效提升LLM的推理能力,以及它在分布外(OOD)数据上的泛化能力如何。现有方法缺乏对GRPO内在机制的深入理解,导致其应用具有一定的盲目性。
核心思路:本文的核心思路是从数据分布的角度来分析GRPO的局限性。作者认为,GRPO本质上是一种保守的重加权策略,它只能在预训练数据分布的基础上进行微调,而无法创造出全新的能力。因此,GRPO的性能提升受限于预训练数据的偏差。如果目标任务与预训练数据的偏差一致,那么GRPO可以实现较好的泛化能力;反之,如果目标任务与预训练数据的偏差不一致,那么GRPO的性能提升将受到限制。
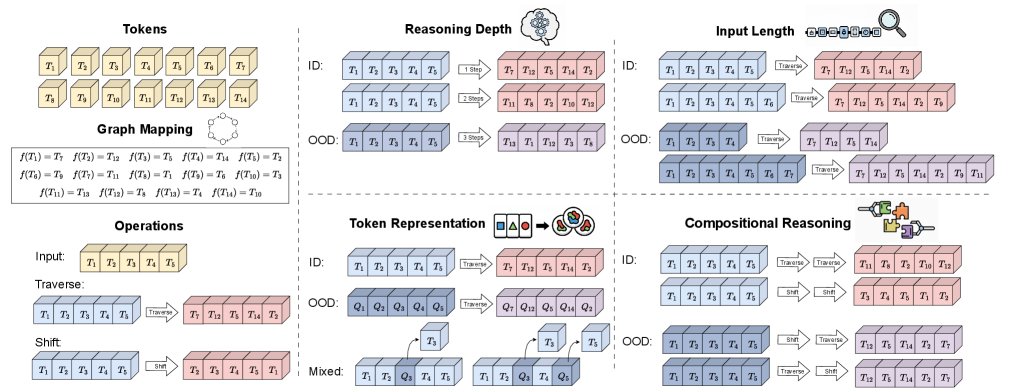
技术框架:本文的技术框架主要包括理论分析和实验验证两个部分。首先,作者从理论上证明了GRPO是一种保守的重加权方案,其性能受限于基础模型的分布。然后,作者通过精心设计的受控实验,从头训练Transformer模型,并评估其在推理深度、输入长度、token表示和组合性等方面的泛化能力。实验结果验证了理论分析的结论,即GRPO的性能提升受限于预训练数据的偏差。
关键创新:本文最重要的技术创新点在于,它从数据分布的角度揭示了GRPO的局限性。与以往的研究不同,本文没有将GRPO视为一种通用的推理增强器,而是将其视为一种强化预训练偏差的工具。这一新的视角有助于我们更好地理解GRPO的内在机制,并为未来的算法设计提供了新的思路。
关键设计:在实验设计方面,作者精心设计了多个受控实验,以评估GRPO在不同条件下的泛化能力。例如,作者通过改变推理深度、输入长度、token表示和组合性等因素,来模拟不同的目标任务。此外,作者还从头训练Transformer模型,以避免预训练数据的干扰。在损失函数方面,作者使用了标准的交叉熵损失函数。在网络结构方面,作者使用了标准的Transformer结构。
🖼️ 关键图片

📊 实验亮点
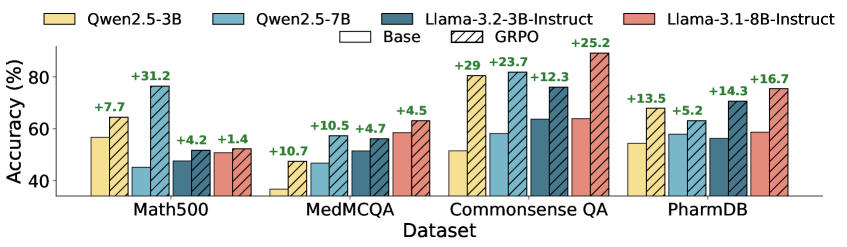
实验结果表明,GRPO在目标任务与预训练偏差对齐时,能够实现分布外泛化,但在分布内任务上,随着性能饱和,收益会逐渐减少。例如,在数学推理任务上,如果预训练数据包含大量的数学知识,那么GRPO可以显著提升模型的推理能力;反之,如果预训练数据缺乏数学知识,那么GRPO的性能提升将受到限制。
🎯 应用场景
该研究成果有助于更好地理解和应用基于强化学习的LLM微调方法,避免盲目使用GRPO,并指导开发能够超越预训练偏差的新算法。潜在应用领域包括自然语言处理、智能问答、机器翻译等,可提升模型在特定领域的专业能力和泛化性能,例如在医疗、金融等领域构建更可靠的AI系统。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR), primarily driven by the Group Relative Policy Optimization (GRPO) algorithm, is a leading approach for enhancing the reasoning abilities of Large Language Models (LLMs). Despite its wide adoption, GRPO's gains are often inconsistent; for instance, a model may show significant improvement in one reasoning domain, like mathematics, yet remain stagnant in another, such as medicine. This inconsistency raises a critical question: under what conditions does GRPO improve reasoning and generalize out-of-distribution (OOD)? We investigate this from a data distribution perspective. We first prove theoretically that GRPO is a conservative reweighting scheme, bounded by the base model's distribution and thus unable to discover completely novel solutions. We further validate this in carefully designed controlled studies by training transformers from scratch, evaluating generalization across reasoning depth, input length, token representation, and compositionality. Our results provide a principled explanation for GRPO's boundaries: OOD improvement emerges only when the target task aligns with the model's pretrained biases, while gains on in-distribution (ID) tasks diminish as performance saturates. This reframes GRPO not as a universal reasoning enhancer but as a tool that sharpens pretraining biases. Our findings motivate future development of algorithms that can expand a model's capabilities beyond its pretraining origin.