Simulation-Based Pretraining and Domain Adaptation for Astronomical Time Series with Minimal Labeled Data
作者: Rithwik Gupta, Daniel Muthukrishna, Jeroen Audenaert
分类: astro-ph.IM, astro-ph.HE, astro-ph.SR, cs.LG
发布日期: 2025-10-14
💡 一句话要点
利用模拟数据预训练和领域自适应,解决天文时间序列分析中标注数据稀缺问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 天文时间序列 预训练 领域自适应 对比学习 对抗学习 模拟数据 零样本迁移
📋 核心要点
- 天文时间序列分析面临标注数据不足的挑战,限制了模型性能和泛化能力。
- 利用模拟数据进行预训练,结合对比学习和对抗学习,学习领域无关的通用表征。
- 实验表明,该方法在分类、红移估计和异常检测任务上,显著优于基线方法,并具备零样本迁移能力。
📝 摘要(中文)
天文时间序列分析面临着标注观测数据稀缺的严峻挑战。本文提出了一种利用模拟数据进行预训练的方法,从而显著降低了对真实观测数据标注的需求。我们的模型在多个天文巡天项目(ZTF和LSST)的模拟数据上进行训练,学习到可泛化的表征,并能有效地迁移到下游任务。通过使用基于分类器的架构,并结合对比和对抗目标,我们创建了领域无关的模型,这些模型在分类、红移估计和异常检测方面,在少量真实数据上进行微调后,表现出比基线方法显著的性能提升。值得注意的是,我们的模型表现出有效的零样本迁移能力,仅使用现有望远镜(ZTF)的数据进行训练,就能在未来望远镜(LSST)的模拟数据上获得相当的性能。此外,尽管模型是在瞬变事件上训练的,但它也能推广到非常不同的天文现象(即NASA extit{Kepler}望远镜的变星),展示了跨领域的能力。我们的方法为在标注数据稀缺但领域知识可以编码在模拟中的情况下,构建通用模型提供了一种实用的解决方案。
🔬 方法详解
问题定义:天文时间序列分析中,真实观测数据的标注成本高昂,导致有监督学习方法难以应用。现有方法依赖大量标注数据,泛化能力有限,难以适应不同天文现象和望远镜设备。
核心思路:利用模拟数据进行预训练,学习通用的时间序列表征。通过对比学习和对抗学习,减小模拟数据和真实数据之间的领域差异,提高模型在真实数据上的泛化能力。这种方法的核心在于利用领域知识构建高质量的模拟数据,从而弥补真实标注数据的不足。
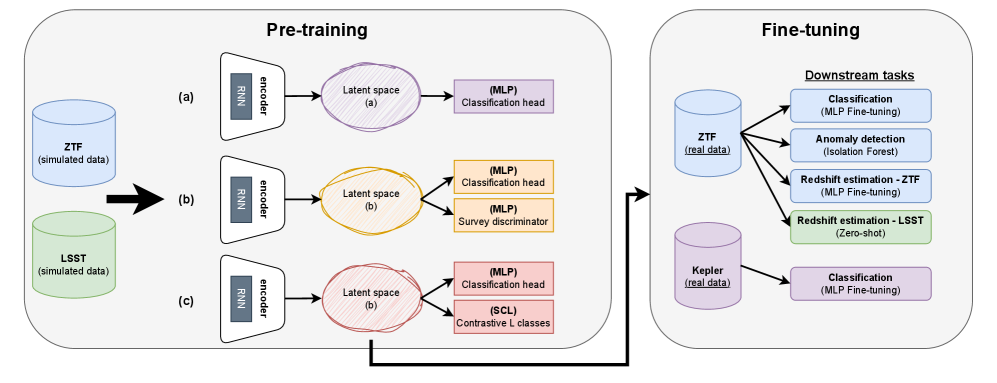
技术框架:整体框架包括三个阶段:1) 在模拟数据上进行预训练,使用分类器架构,并结合对比学习和对抗学习目标;2) 在少量真实标注数据上进行微调,以适应特定任务;3) 在目标数据集上进行评估。主要模块包括:时间序列特征提取器、分类器、对比学习模块和对抗学习模块。
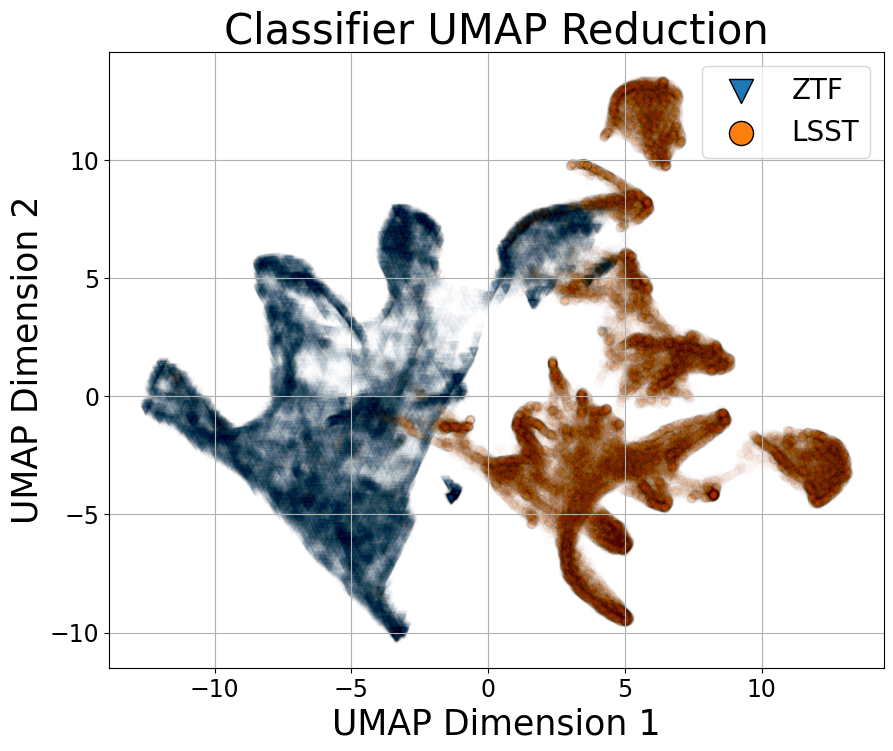
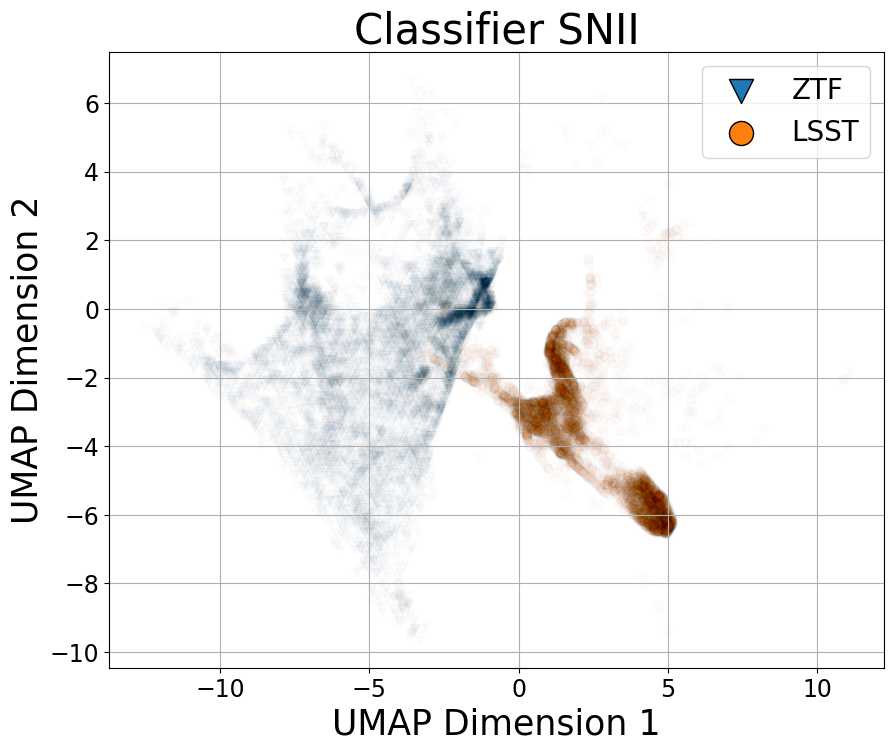
关键创新:最重要的创新点在于结合模拟数据预训练、对比学习和对抗学习,构建领域无关的天文时间序列分析模型。与传统方法相比,该方法显著降低了对真实标注数据的依赖,提高了模型的泛化能力和跨领域适应性。
关键设计:对比学习模块采用InfoNCE损失函数,鼓励模型学习区分不同的时间序列样本。对抗学习模块采用梯度反转层,使特征提取器学习领域不变的特征表示。网络结构采用卷积神经网络和循环神经网络相结合的方式,以提取时间序列的时序特征和空间特征。具体的参数设置和网络结构根据不同的数据集和任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在ZTF和LSST模拟数据上进行预训练后,在真实数据集上进行微调,分类准确率显著优于基线方法。在零样本迁移实验中,仅使用ZTF数据训练的模型,在LSST数据上取得了可比的性能。此外,该模型还成功迁移到Kepler望远镜的变星数据上,证明了其跨领域泛化能力。性能提升幅度根据具体任务和数据集而异,但总体上优于现有方法。
🎯 应用场景
该研究成果可广泛应用于天文时间序列数据的自动分类、红移估计、异常检测等任务。尤其适用于新一代大型天文巡天项目,如LSST,能够有效处理海量数据,发现新的天文现象,并提高天文研究的效率和精度。此外,该方法也可推广到其他领域,如金融时间序列分析、医疗诊断等,解决标注数据稀缺的问题。
📄 摘要(原文)
Astronomical time-series analysis faces a critical limitation: the scarcity of labeled observational data. We present a pre-training approach that leverages simulations, significantly reducing the need for labeled examples from real observations. Our models, trained on simulated data from multiple astronomical surveys (ZTF and LSST), learn generalizable representations that transfer effectively to downstream tasks. Using classifier-based architectures enhanced with contrastive and adversarial objectives, we create domain-agnostic models that demonstrate substantial performance improvements over baseline methods in classification, redshift estimation, and anomaly detection when fine-tuned with minimal real data. Remarkably, our models exhibit effective zero-shot transfer capabilities, achieving comparable performance on future telescope (LSST) simulations when trained solely on existing telescope (ZTF) data. Furthermore, they generalize to very different astronomical phenomena (namely variable stars from NASA's \textit{Kepler} telescope) despite being trained on transient events, demonstrating cross-domain capabilities. Our approach provides a practical solution for building general models when labeled data is scarce, but domain knowledge can be encoded in simulations.