A Multimodal XAI Framework for Trustworthy CNNs and Bias Detection in Deep Representation Learning
作者: Noor Islam S. Mohammad
分类: cs.LG, cs.AI
发布日期: 2025-10-14
💡 一句话要点
提出多模态XAI框架,用于提升CNN可信度并检测深度表征学习中的偏见
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 可解释AI 偏见检测 深度表征学习 注意力机制
📋 核心要点
- 现有方法难以在复杂多模态数据中发现和缓解深度学习模型的潜在偏见,影响模型在高风险场景下的可信度。
- 该论文提出一种多模态XAI框架,结合注意力机制、局部解释和反馈循环,以检测和减轻模型中的偏见。
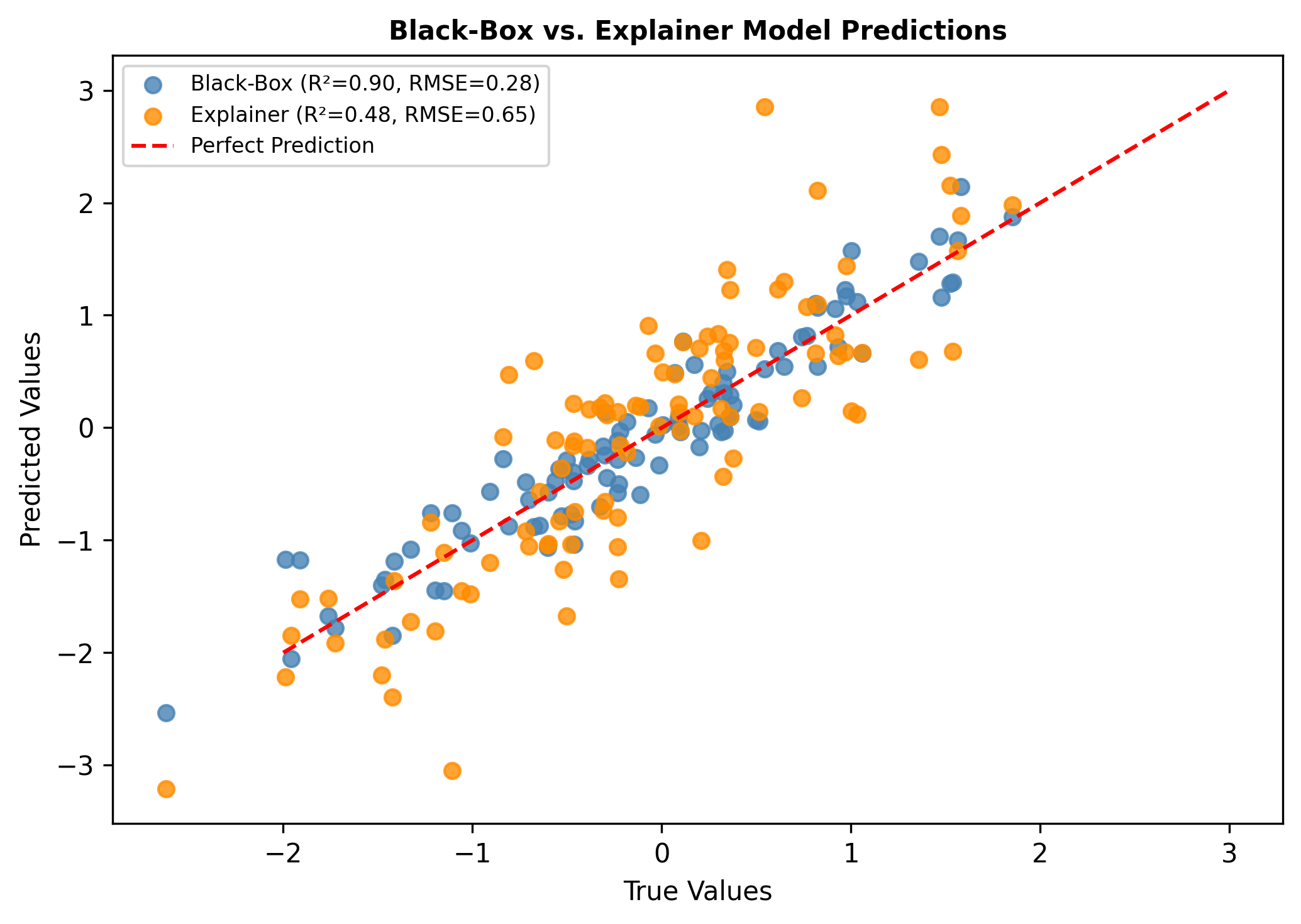
- 实验结果表明,该方法在多模态MNIST数据集上取得了优异的分类性能和解释保真度,并提升了模型的鲁棒性。
📝 摘要(中文)
标准基准数据集,如MNIST,通常无法暴露潜在的偏见和多模态特征的复杂性,从而限制了深度神经网络在高风险应用中的可信度。我们提出了一种新颖的多模态可解释AI(XAI)框架,该框架统一了注意力增强的特征融合、基于Grad-CAM++的局部解释以及用于偏见检测和缓解的Reveal-to-Revise反馈循环。在MNIST的多模态扩展数据集上进行评估,我们的方法实现了93.2%的分类准确率、91.6%的F1分数和78.1%的解释保真度(IoU-XAI),优于单模态和非可解释的基线方法。消融研究表明,将可解释性与偏见感知学习相结合可以增强鲁棒性和人类对齐。我们的工作弥合了性能、透明度和公平性之间的差距,突出了在敏感领域实现可信AI的实用途径。
🔬 方法详解
问题定义:现有深度学习模型,尤其是在处理多模态数据时,容易受到数据集中潜在偏见的影响,导致模型在特定群体上表现不佳。传统的基准数据集往往无法充分暴露这些偏见,使得模型的可信度受到质疑。因此,需要一种方法来检测和缓解深度学习模型中的偏见,并提高模型的可解释性,从而增强其在高风险应用中的可信度。
核心思路:该论文的核心思路是将可解释性融入到模型的训练过程中,通过分析模型对不同模态特征的关注程度,以及模型预测结果的局部解释,来发现模型中存在的偏见。同时,利用Reveal-to-Revise反馈循环,引导模型学习更加公平和鲁棒的特征表示。
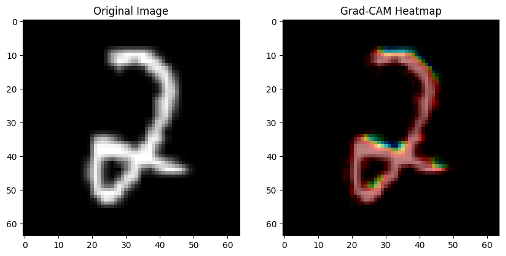
技术框架:该框架主要包含三个模块:1) 注意力增强的特征融合模块,用于融合来自不同模态的特征,并学习每个模态的重要性;2) 基于Grad-CAM++的局部解释模块,用于生成模型预测结果的局部解释,突出显示对预测结果贡献最大的区域;3) Reveal-to-Revise反馈循环模块,用于根据局部解释的结果,调整模型的参数,以减轻模型中的偏见。整体流程是,首先通过注意力机制融合多模态特征,然后利用Grad-CAM++生成局部解释,最后通过反馈循环调整模型参数,迭代优化模型。
关键创新:该论文的关键创新在于将注意力机制、局部解释和反馈循环有机地结合在一起,形成一个统一的多模态XAI框架。该框架不仅可以提高模型的可解释性,还可以有效地检测和缓解模型中的偏见。此外,该框架还提出了一种新的Reveal-to-Revise反馈循环,可以根据局部解释的结果,自动调整模型的参数,从而减轻模型中的偏见。
关键设计:注意力增强的特征融合模块使用自注意力机制来学习不同模态特征之间的关系,并为每个模态分配一个权重,表示该模态的重要性。Grad-CAM++用于生成高分辨率的局部解释图,突出显示对预测结果贡献最大的区域。Reveal-to-Revise反馈循环使用一个偏见检测器来评估模型的预测结果是否存在偏见,并根据检测结果调整模型的参数。具体的损失函数包括分类损失、解释损失和偏见损失,通过联合优化这些损失函数,可以提高模型的分类性能、解释保真度和公平性。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
在多模态MNIST数据集上的实验结果表明,该方法实现了93.2%的分类准确率、91.6%的F1分数和78.1%的解释保真度(IoU-XAI),显著优于单模态和非可解释的基线方法。消融研究进一步验证了各个模块的有效性,表明将可解释性与偏见感知学习相结合可以有效提升模型的鲁棒性和人类对齐。
🎯 应用场景
该研究成果可应用于医疗诊断、金融风控、自动驾驶等高风险领域。通过提高模型的可解释性和公平性,增强用户对AI系统的信任,从而促进AI技术在这些领域的应用。此外,该框架还可以用于评估和改进现有的深度学习模型,提高其鲁棒性和可靠性,具有重要的实际价值和未来影响。
📄 摘要(原文)
Standard benchmark datasets, such as MNIST, often fail to expose latent biases and multimodal feature complexities, limiting the trustworthiness of deep neural networks in high-stakes applications. We propose a novel multimodal Explainable AI (XAI) framework that unifies attention-augmented feature fusion, Grad-CAM++-based local explanations, and a Reveal-to-Revise feedback loop for bias detection and mitigation. Evaluated on multimodal extensions of MNIST, our approach achieves 93.2% classification accuracy, 91.6% F1-score, and 78.1% explanation fidelity (IoU-XAI), outperforming unimodal and non-explainable baselines. Ablation studies demonstrate that integrating interpretability with bias-aware learning enhances robustness and human alignment. Our work bridges the gap between performance, transparency, and fairness, highlighting a practical pathway for trustworthy AI in sensitive domains.