Pruning Cannot Hurt Robustness: Certified Trade-offs in Reinforcement Learning
作者: James Pedley, Benjamin Etheridge, Stephen J. Roberts, Francesco Quinzan
分类: cs.LG
发布日期: 2025-10-14
备注: 24 pages, 13 figures
💡 一句话要点
提出剪枝策略,提升强化学习在对抗环境下的鲁棒性并进行理论保证。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 鲁棒性 剪枝 对抗攻击 认证鲁棒性
📋 核心要点
- 深度强化学习模型过度参数化,导致成本高昂且易受攻击,在对抗环境下的鲁棒性面临挑战。
- 论文提出通过剪枝来提升强化学习的鲁棒性,并从理论上证明剪枝不会降低策略的鲁棒性。
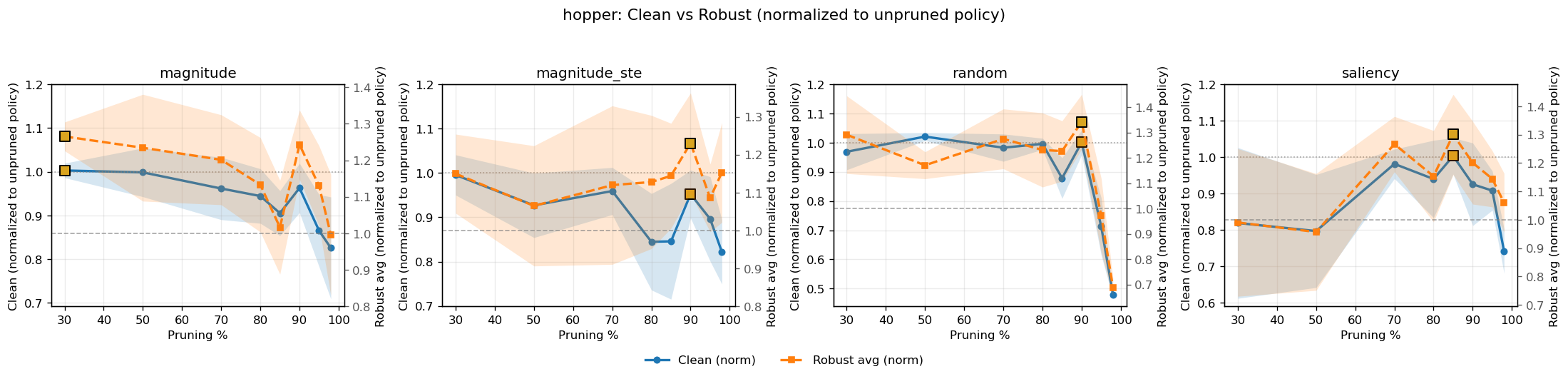
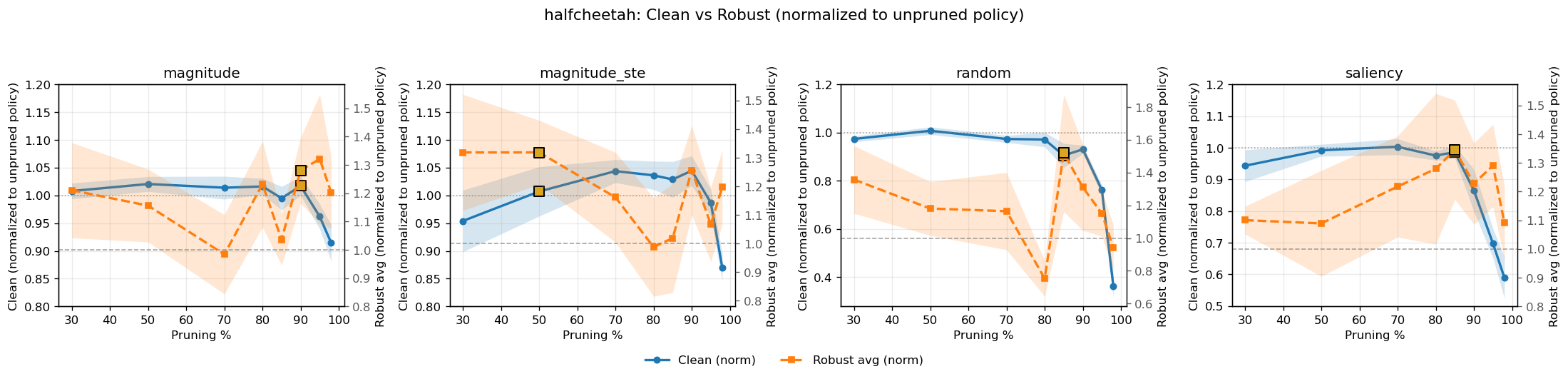
- 实验表明,适度剪枝可以在不损害甚至提高原始性能的情况下,显著提升强化学习策略的鲁棒性。
📝 摘要(中文)
本文研究了强化学习策略在对抗扰动下的鲁棒性问题,尤其关注剪枝技术在对抗强化学习中的作用。针对状态对抗马尔可夫决策过程(SA-MDPs),论文构建了首个剪枝下认证鲁棒性的理论框架。对于具有Lipschitz网络的Gaussian和categorical策略,证明了逐元素剪枝只能收紧认证鲁棒性边界,即剪枝不会降低策略的鲁棒性。在此基础上,推导了一个新的三项后悔分解,将clean-task性能、剪枝引起的性能损失和鲁棒性增益分离,揭示了性能-鲁棒性之间的基本权衡。实验结果表明,在连续控制基准测试中,剪枝能够在适度的稀疏水平下发现可重复的“最佳点”,从而在不损害甚至提高clean性能的情况下,显著提高鲁棒性。这些结果表明,剪枝不仅是一种压缩工具,而且是一种用于鲁棒强化学习的结构性干预。
🔬 方法详解
问题定义:论文旨在解决强化学习策略在状态对抗环境下的鲁棒性问题。现有深度强化学习模型通常过度参数化,导致计算成本高昂,并且容易受到对抗样本的攻击。虽然剪枝在监督学习中已被证明可以提高鲁棒性,但其在对抗强化学习中的作用尚不明确。因此,需要研究剪枝对强化学习策略鲁棒性的影响,并提供理论保证。
核心思路:论文的核心思路是证明在状态对抗马尔可夫决策过程(SA-MDPs)中,对具有Lipschitz网络的Gaussian和categorical策略进行逐元素剪枝,不会降低策略的认证鲁棒性。通过理论分析,证明剪枝可以收紧认证鲁棒性边界,从而提高策略的鲁棒性。此外,论文还提出了一个三项后悔分解,用于分析剪枝对性能和鲁棒性的影响。
技术框架:论文的技术框架主要包括以下几个部分:1) 形式化定义状态对抗马尔可夫决策过程(SA-MDPs);2) 针对具有Lipschitz网络的Gaussian和categorical策略,推导认证鲁棒性边界;3) 证明逐元素剪枝可以收紧认证鲁棒性边界;4) 提出三项后悔分解,分析剪枝对性能和鲁棒性的影响;5) 通过实验验证剪枝在连续控制任务中的有效性。
关键创新:论文的关键创新在于:1) 首次提出了剪枝下认证鲁棒性的理论框架,为剪枝在对抗强化学习中的应用提供了理论基础;2) 证明了剪枝不会降低策略的鲁棒性,颠覆了以往认为剪枝可能会损害模型性能的观点;3) 提出了三项后悔分解,能够更清晰地分析剪枝对性能和鲁棒性的影响。
关键设计:论文的关键设计包括:1) 采用Lipschitz网络来保证策略的平滑性,从而更容易推导认证鲁棒性边界;2) 使用逐元素剪枝,避免引入额外的结构性偏差;3) 通过调整剪枝率,探索性能和鲁棒性之间的权衡;4) 在连续控制任务中,使用magnitude和micro-pruning schedules进行实验,验证剪枝的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在连续控制基准测试中,剪枝能够在适度的稀疏水平下发现可重复的“最佳点”,从而在不损害甚至提高clean性能的情况下,显著提高鲁棒性。例如,在某些任务中,通过剪枝,策略的鲁棒性可以提高10%以上,同时clean性能保持不变甚至有所提升。这些结果验证了剪枝在对抗强化学习中的有效性。
🎯 应用场景
该研究成果可应用于对安全性要求较高的强化学习应用场景,例如自动驾驶、机器人控制等。通过剪枝,可以在保证策略鲁棒性的前提下,降低模型的计算成本和存储空间,从而更容易部署到资源受限的设备上。此外,该研究也为未来研究如何设计更有效的剪枝算法,以进一步提高强化学习策略的鲁棒性提供了理论指导。
📄 摘要(原文)
Reinforcement learning (RL) policies deployed in real-world environments must remain reliable under adversarial perturbations. At the same time, modern deep RL agents are heavily over-parameterized, raising costs and fragility concerns. While pruning has been shown to improve robustness in supervised learning, its role in adversarial RL remains poorly understood. We develop the first theoretical framework for certified robustness under pruning in state-adversarial Markov decision processes (SA-MDPs). For Gaussian and categorical policies with Lipschitz networks, we prove that element-wise pruning can only tighten certified robustness bounds; pruning never makes the policy less robust. Building on this, we derive a novel three-term regret decomposition that disentangles clean-task performance, pruning-induced performance loss, and robustness gains, exposing a fundamental performance--robustness frontier. Empirically, we evaluate magnitude and micro-pruning schedules on continuous-control benchmarks with strong policy-aware adversaries. Across tasks, pruning consistently uncovers reproducible ``sweet spots'' at moderate sparsity levels, where robustness improves substantially without harming - and sometimes even enhancing - clean performance. These results position pruning not merely as a compression tool but as a structural intervention for robust RL.