Adaptive vector steering: A training-free, layer-wise intervention for hallucination mitigation in large audio and multimodal models
作者: Tsung-En Lin, Kuan-Yi Lee, Hung-Yi Lee
分类: cs.SD, cs.LG, eess.AS
发布日期: 2025-10-14
备注: Note: This preprint is a version of the paper submitted to ICASSP 2026. The author list here includes contributors who provided additional supervision and guidance. The official ICASSP submission may differ slightly in author composition
💡 一句话要点
提出自适应向量引导(AVS)方法,无需训练即可缓解大型音频和多模态模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频幻觉 向量引导 自适应干预 大型语言模型 多模态模型 音频理解 无训练方法
📋 核心要点
- 大型音频和多模态模型易产生音频内容幻觉,现有方法难以有效解决。
- 提出自适应向量引导(AVS),通过干预模型内部状态,使生成内容更好地基于音频。
- 实验表明,AVS在多个模型和数据集上均能显著提升性能,有效缓解幻觉问题。
📝 摘要(中文)
大型音频-语言模型和多模态大型语言模型在音频问答(AQA)、音频字幕和自动语音识别(ASR)等任务中表现出强大的能力。然而,越来越多的证据表明这些模型可能会产生关于音频内容的幻觉。为了解决这个问题,我们探测了模型的内部状态,并提出了一种自适应向量引导(AVS)方法,该方法可以更好地将生成内容与音频内容对齐。我们还发现输出正确性与内部表示之间存在很强的相关性。实验表明,该方法在两个模型和两个基准测试中都取得了持续的性能提升。在音频幻觉问答数据集上,我们的方法将Gemma的F1分数从0.550提高到0.619,将Qwen的F1分数从0.626提高到0.632。此外,我们的方法将Qwen在MMAU上的准确率从0.548提高到0.592,相对提升了8%。据我们所知,这是第一项将向量引导应用于缓解音频幻觉的工作。
🔬 方法详解
问题定义:大型音频语言模型和多模态大型语言模型在处理音频相关任务时,容易产生与实际音频内容不符的“幻觉”。现有方法通常需要大量训练数据或复杂的模型结构,难以有效且高效地缓解这一问题。论文旨在提出一种无需额外训练,且易于集成的方法,以减少模型在音频理解任务中的幻觉现象。
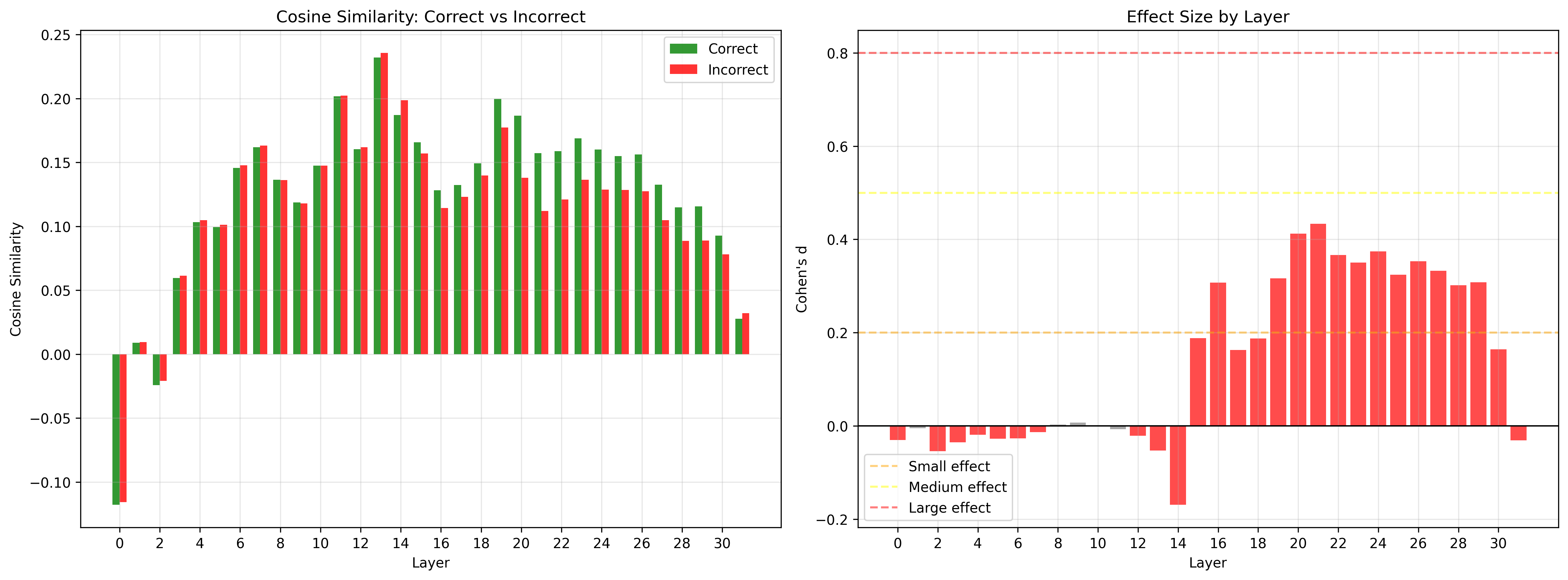
核心思路:论文的核心思路是,通过分析模型内部表征与输出正确性之间的关系,发现模型内部状态中包含着关于音频内容的关键信息。通过对这些内部状态进行引导(steering),可以促使模型生成更符合音频内容的输出,从而减少幻觉。这种引导是自适应的,能够根据不同的音频输入调整引导方向和强度。
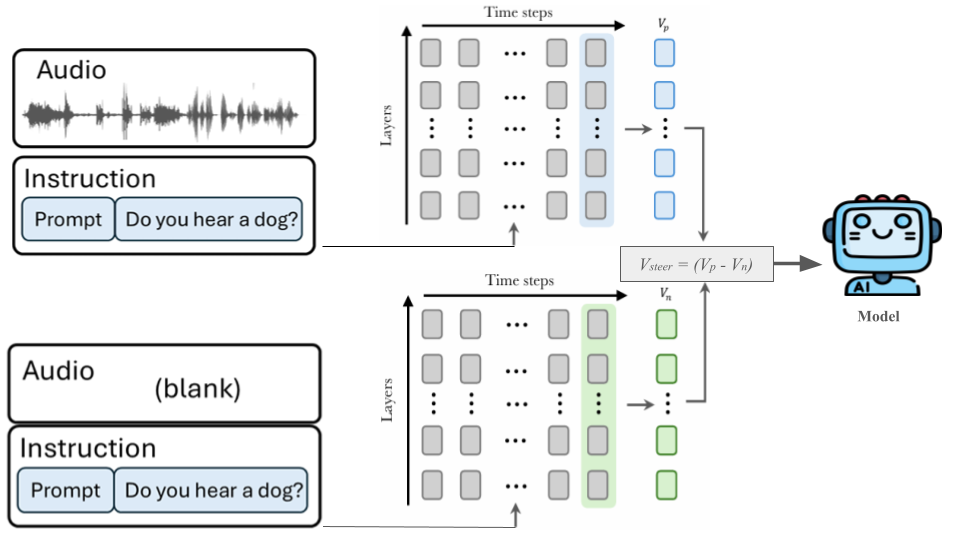
技术框架:AVS方法主要包含以下几个阶段:1) 内部状态探测:分析模型在处理音频输入时各层的内部表征。2) 引导向量计算:基于探测结果,计算用于引导模型生成方向的向量。该向量的设计目标是使模型输出更贴近真实的音频内容。3) 自适应引导:将计算得到的引导向量应用到模型的内部状态,影响模型的后续生成过程。引导的强度是自适应的,根据当前层的状态和引导向量的匹配程度进行调整。
关键创新:AVS的关键创新在于其无需训练的特性和自适应的引导机制。与需要大量训练数据的方法不同,AVS可以直接应用于预训练模型,无需额外的训练开销。自适应引导机制使得AVS能够根据不同的音频输入和模型状态进行调整,从而更有效地缓解幻觉。此外,该方法是layer-wise的,可以灵活地应用于模型的不同层,进一步提升了其适应性。
关键设计:AVS的关键设计包括:1) 引导向量的计算方式:论文具体描述了如何从模型的内部表征中提取出引导向量,可能涉及到对内部表征进行统计分析、降维或变换等操作。2) 自适应引导强度的计算方式:论文详细说明了如何根据当前层的状态和引导向量的匹配程度来调整引导强度,可能涉及到相似度计算、注意力机制或门控机制等技术。3) layer-wise应用策略:论文阐述了如何选择应用AVS的层,以及如何在不同层之间调整引导策略,以达到最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AVS方法在音频幻觉问答(Audio Hallucination QA)数据集上,将Gemma模型的F1分数从0.550提升至0.619,将Qwen模型的F1分数从0.626提升至0.632。在MMAU数据集上,AVS将Qwen模型的准确率从0.548提升至0.592,实现了8%的相对提升。这些结果证明了AVS方法在缓解音频幻觉方面的有效性。
🎯 应用场景
该研究成果可广泛应用于各种依赖音频理解的场景,如智能语音助手、自动语音转录、音频内容分析和多模态信息检索等。通过减少模型幻觉,可以提高这些应用在实际场景中的可靠性和用户体验。未来,该方法有望扩展到其他模态,提升多模态模型的整体性能。
📄 摘要(原文)
Large Audio-Language Models and Multi-Modal Large Language Models have demonstrated strong capabilities in tasks such as Audio Question Answering (AQA), Audio Captioning, and Automatic Speech Recognition (ASR). However, there is growing evidence that these models can hallucinate about the content of the audio. To address this issue, we probe the models' internal states and propose Adaptive Vector Steering (AVS), a method that better grounds generation in audio content. We also identify a strong correlation between output correctness and internal representations. Experiments show consistent performance gains across two models and two benchmarks. On the Audio Hallucination QA dataset, our method boosts the F1-score of Gemma from 0.550 to 0.619 and Qwen from 0.626 to 0.632. Furthermore, our method increases the accuracy of Qwen on MMAU from 0.548 to 0.592, marking an 8% relative increase. To the best of our knowledge, this is the first work to apply vector steering to mitigate hallucination in audio.