Lifting Manifolds to Mitigate Pseudo-Alignment in LLM4TS
作者: Liangwei Nathan Zheng, Wenhao Liang, Wei Emma Zhang, Miao Xu, Olaf Maennel, Weitong Chen
分类: cs.LG
发布日期: 2025-10-14
💡 一句话要点
提出TimeSUP,通过提升流形维度缓解LLM4TS中的伪对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 大语言模型 伪对齐 流形学习 锥形效应
📋 核心要点
- 现有LLM4TS模型受伪对齐问题困扰,性能受限,但对其原因缺乏深入研究。
- TimeSUP通过增加时间序列流形维度,使其与语言嵌入维度匹配,从而区分时间信号。
- TimeSUP在多个LLM4TS流程中显著提升了长期预测性能,优于现有方法。
📝 摘要(中文)
伪对齐是时间序列大语言模型(LLM4TS)中普遍存在的挑战,导致其性能通常不如线性模型或随机初始化的骨干网络。本文深入研究了LLM4TS中伪对齐的根本原因,并将其与LLM中的锥形效应联系起来。研究表明,伪对齐源于预训练LLM组件中的锥形效应与时间序列数据内在的低维流形之间的相互作用。此外,我们还提出了一种名为TimeSUP的新技术,旨在缓解此问题并提高现有LLM4TS方法的预测性能。TimeSUP通过增加时间序列流形,使其更接近语言嵌入的内在维度,从而使模型能够清晰地区分时间信号,同时捕获跨模态的共享结构。实验结果表明,TimeSUP始终优于最先进的LLM4TS方法和其他轻量级基线,并且可以无缝集成到四个现有的LLM4TS流程中,从而显著提高预测性能。
🔬 方法详解
问题定义:论文旨在解决LLM4TS模型中普遍存在的伪对齐问题。伪对齐导致模型无法有效利用预训练语言模型的知识,使得其预测性能甚至不如简单的线性模型。现有方法缺乏对伪对齐根本原因的深入理解,难以有效缓解该问题。
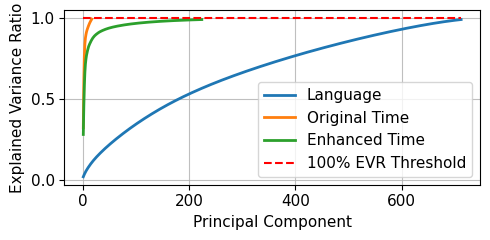
核心思路:论文的核心思路是将伪对齐问题与LLM中的锥形效应联系起来,并认为时间序列数据固有的低维流形是导致伪对齐的原因之一。TimeSUP的核心思想是通过增加时间序列数据的流形维度,使其更接近语言嵌入的维度,从而使模型能够更好地区分时间信号和语言信号,避免二者混淆。
技术框架:TimeSUP可以无缝集成到现有的LLM4TS流程中。其主要步骤包括:首先,对时间序列数据进行预处理,通过某种方式(具体方式论文未详细说明,属于TimeSUP的具体实现)增加其流形维度;然后,将处理后的时间序列数据输入到LLM4TS模型中进行训练;最后,使用训练好的模型进行时间序列预测。
关键创新:TimeSUP的关键创新在于其对伪对齐问题的独特视角,以及通过增加时间序列流形维度来缓解该问题的思路。与现有方法不同,TimeSUP并非直接修改模型结构或训练方式,而是从数据层面入手,通过改变时间序列数据的表示方式来改善模型的性能。
关键设计:论文中并未详细描述TimeSUP的具体实现细节,例如如何增加时间序列数据的流形维度,以及具体的参数设置和损失函数。这些细节属于TimeSUP的具体实现,需要在阅读原文后才能了解。但论文强调,TimeSUP的设计目标是使时间和语言token的表示保持区分,同时具有较高的余弦相似度,以便模型能够同时捕捉两种模态的独特特征和共同结构。
🖼️ 关键图片


📊 实验亮点
TimeSUP在多个数据集上进行了实验,并与最先进的LLM4TS方法和其他轻量级基线进行了比较。实验结果表明,TimeSUP始终优于其他方法,并在长期预测任务中表现出显著的优势。具体性能提升数据未知,需要在阅读原文后才能了解。
🎯 应用场景
该研究成果可广泛应用于需要利用大语言模型进行时间序列预测的领域,例如金融市场预测、供应链管理、能源需求预测、交通流量预测等。通过缓解伪对齐问题,TimeSUP能够提升LLM4TS模型的预测精度和泛化能力,为相关领域的决策提供更可靠的依据,具有重要的实际应用价值。
📄 摘要(原文)
Pseudo-Alignment is a pervasive challenge in many large language models for time series (LLM4TS) models, often causing them to underperform compared to linear models or randomly initialised backbones. However, there is limited discussion in the community for the reasons that pseudo-alignment occurs. In this work, we conduct a thorough investigation into the root causes of pseudo-alignment in LLM4TS and build a connection of pseudo-alignment to the cone effect in LLM. We demonstrate that pseudo-alignment arises from the interplay of cone effect within pretrained LLM components and the intrinsically low-dimensional manifold of time-series data. In addition, we also introduce \textit{\textbf{TimeSUP}}, a novel technique designed to mitigate this issue and improve forecast performance in existing LLM4TS approaches. TimeSUP addresses this by increasing the time series manifold to more closely match the intrinsic dimension of language embeddings, allowing the model to distinguish temporal signals clearly while still capturing shared structures across modalities. As a result, representations for time and language tokens remain distinct yet exhibit high cosine similarity, signifying that the model preserves each modality unique features while learning their commonalities in a unified embedding space. Empirically, TimeSUP consistently outperforms state-of-the-art LLM4TS methods and other lightweight baselines on long-term forecasting performance. Furthermore, it can be seamlessly integrated into four existing LLM4TS pipelines and delivers significant improvements in forecasting performance.