Data-Model Co-Evolution: Growing Test Sets to Refine LLM Behavior
作者: Minjae Lee, Minsuk Kahng
分类: cs.HC, cs.LG
发布日期: 2025-10-14
💡 一句话要点
提出数据-模型协同进化框架,通过增长测试集优化LLM行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示工程 数据-模型协同进化 测试集增长 人机协作
📋 核心要点
- 现有LLM应用中,将领域特定策略编码到提示指令中存在挑战,难以应对边缘情况和模糊策略。
- 论文提出数据-模型协同进化框架,通过构建和增长测试集,迭代优化LLM的提示指令。
- 用户研究表明,该框架能帮助用户系统地改进指令,更具体地指定策略,提升LLM应用的鲁棒性。
📝 摘要(中文)
机器学习领域长期存在数据工作和模型改进之间严格分离的挑战,这受到缓慢的微调周期的限制。大型语言模型(LLM)的兴起克服了这一障碍,允许应用程序开发者通过编辑提示指令来即时控制模型行为。这种转变促成了一种新的范式:数据-模型协同进化,其中动态的测试集和模型的指令同步演进。本文在一个交互式系统中实现了这种范式,旨在解决将细微的、特定领域的策略编码到提示指令中的关键挑战。该系统的结构化工作流程引导人们发现边缘案例,阐明期望行为的理由,并根据不断增长的测试集迭代评估指令修订。用户研究表明,本文的工作流程有助于参与者系统地改进指令,并更具体地指定模糊的策略。这项工作指向通过与本地偏好和策略对齐的人工参与开发,实现更强大和负责任的LLM应用。
🔬 方法详解
问题定义:论文旨在解决如何将细微的、特定领域的策略有效地编码到大型语言模型(LLM)的提示指令中。现有方法依赖于缓慢的微调周期,难以快速适应新的数据和策略。此外,现有方法在处理边缘情况和模糊策略时表现不佳,导致LLM的行为不稳定且难以预测。
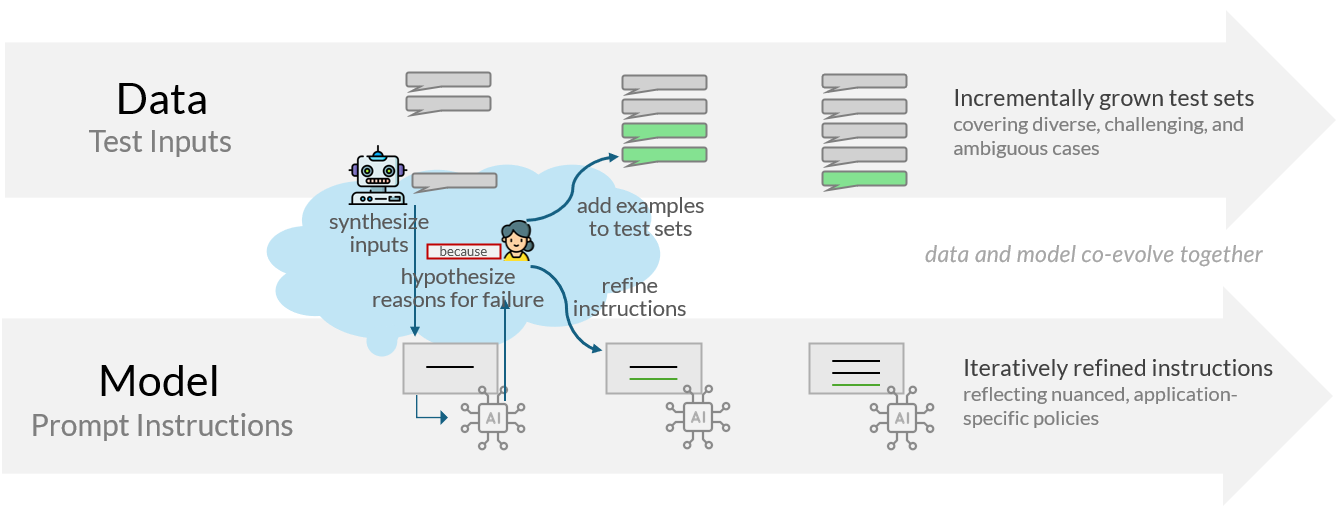
核心思路:论文的核心思路是建立一个数据-模型协同进化的框架,其中测试数据集和LLM的提示指令同步演进。通过迭代地发现边缘案例,阐明期望行为的理由,并根据不断增长的测试集评估指令修订,可以逐步完善LLM的行为,使其更好地符合特定领域的策略。这种方法强调人工参与,允许开发者根据本地偏好和策略调整LLM的行为。
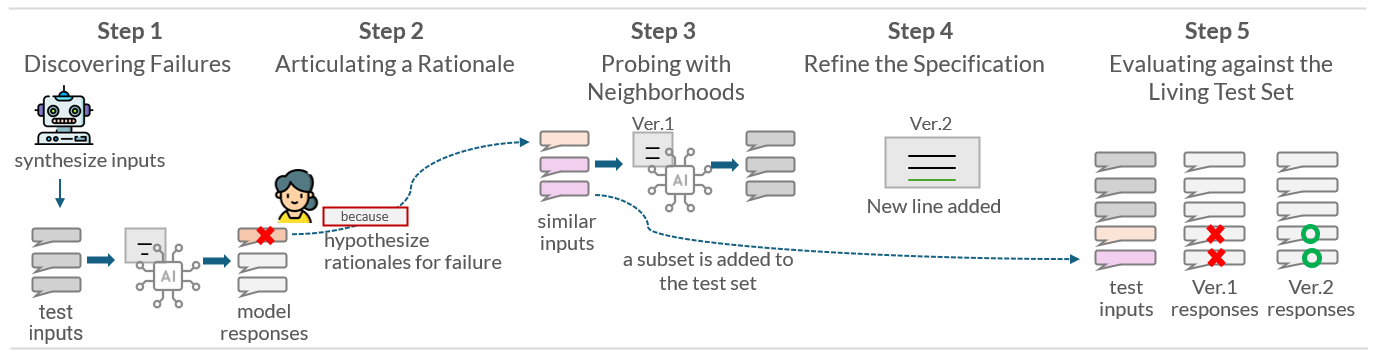
技术框架:该系统包含一个交互式工作流程,引导用户进行以下步骤:1) 发现边缘案例:用户探索LLM在特定场景下的行为,识别不符合预期的情况。2) 阐明理由:用户为期望的行为提供明确的理由,解释为什么LLM应该以某种方式响应。3) 修订指令:用户根据发现的边缘案例和阐明的理由,修改LLM的提示指令。4) 评估:用户使用不断增长的测试集评估修订后的指令,检查是否解决了边缘案例,并确保没有引入新的问题。这个过程迭代进行,直到LLM的行为满足要求。
关键创新:该论文的关键创新在于提出了数据-模型协同进化的范式,打破了传统机器学习中数据和模型分离的局面。通过将测试数据集和模型指令置于一个共同的进化循环中,可以更有效地利用人工反馈来改进LLM的行为。与传统的微调方法相比,该方法更加灵活和高效,能够快速适应新的数据和策略。
关键设计:该系统的关键设计包括:1) 结构化的工作流程,引导用户系统地进行指令修订。2) 用于存储和管理测试数据集的机制,确保测试集的覆盖范围和质量。3) 用于评估指令修订效果的指标,帮助用户量化改进程度。论文未明确提及具体的参数设置、损失函数或网络结构,因为该方法主要关注提示工程和数据管理,而非模型本身的修改。
🖼️ 关键图片

📊 实验亮点
用户研究表明,该工作流程能有效帮助参与者系统地改进LLM的指令,并更具体地指定模糊的策略。通过迭代地发现边缘案例和修订指令,参与者能够显著提高LLM在特定领域的性能,并减少不符合预期行为的发生。具体的性能数据和对比基线在论文中未明确量化,但用户研究的结果表明该方法具有显著的实际效果。
🎯 应用场景
该研究成果可应用于各种需要将领域特定策略融入LLM的应用场景,例如:金融风控、医疗诊断、法律咨询等。通过数据-模型协同进化,可以使LLM更好地理解和执行特定领域的规则和约束,提高应用的可靠性和安全性。未来,该方法有望推广到更广泛的AI系统开发中,促进人机协作和负责任的AI发展。
📄 摘要(原文)
A long-standing challenge in machine learning has been the rigid separation between data work and model refinement, enforced by slow fine-tuning cycles. The rise of Large Language Models (LLMs) overcomes this historical barrier, allowing applications developers to instantly govern model behavior by editing prompt instructions. This shift enables a new paradigm: data-model co-evolution, where a living test set and a model's instructions evolve in tandem. We operationalize this paradigm in an interactive system designed to address the critical challenge of encoding subtle, domain-specific policies into prompt instructions. The system's structured workflow guides people to discover edge cases, articulate rationales for desired behavior, and iteratively evaluate instruction revisions against a growing test set. A user study shows our workflow helps participants refine instructions systematically and specify ambiguous policies more concretely. This work points toward more robust and responsible LLM applications through human-in-the-loop development aligned with local preferences and policies.