CARVQ: Corrective Adaptor with Group Residual Vector Quantization for LLM Embedding Compression
作者: Dayin Gou, Sanghyun Byun, Nilesh Malpeddi, Gabrielle De Micheli, Prathamesh Vaste, Jacob Song, Woo Seong Chung
分类: cs.LG
发布日期: 2025-10-14
备注: Accepted at EMNLP Findings 2025
💡 一句话要点
提出CARVQ:一种基于校正适配器和分组残差向量量化的LLM嵌入压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型压缩 向量量化 边缘计算 嵌入层压缩
📋 核心要点
- 现有LLM嵌入层参数量巨大,导致边缘设备部署时内存受限,需要高效的压缩方法。
- CARVQ通过校正适配器和分组残差向量量化,在不牺牲过多性能的前提下,实现极低的比特宽度压缩。
- 实验表明,CARVQ在多个LLM上,相比标量量化,能以更低比特宽度保持较好的困惑度和准确率。
📝 摘要(中文)
大型语言模型(LLM)通常依赖于大量的参数进行token嵌入,导致巨大的存储需求和内存占用。特别是,部署在边缘设备上的LLM受限于内存,通过压缩嵌入层来减少内存占用不仅可以释放内存带宽,还可以加速推理。为了解决这个问题,我们提出了一种新颖的后训练校正适配器CARVQ,它与分组残差向量量化相结合。CARVQ依赖于线性和非线性映射的组合,并模仿原始模型嵌入,以压缩到大约1.6比特,而无需专门的硬件来支持较低比特的存储。我们在预训练的LLM(如LLaMA-3.2-1B、LLaMA-3.2-3B、LLaMA-3.2-3B-Instruct、LLaMA-3.1-8B、Qwen2.5-7B、Qwen2.5-Math-7B和Phi-4)上测试了我们的方法,并在常见的生成、判别、数学和推理任务上进行了评估。结果表明,在大多数情况下,与标量量化相比,CARVQ可以在保持合理的困惑度和准确性的同时,实现更低的平均每参数比特宽度。我们的贡献包括一种与最先进的Transformer量化方法兼容的新型压缩技术,并且可以无缝集成到任何支持4比特内存的硬件中,以减少内存受限设备中模型的内存占用。这项工作展示了在边缘设备上高效部署LLM的关键一步。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在边缘设备上部署时,由于嵌入层参数量巨大而导致的内存瓶颈问题。现有方法,如标量量化,在极低比特宽度下会显著降低模型性能,无法在精度和压缩率之间取得平衡。
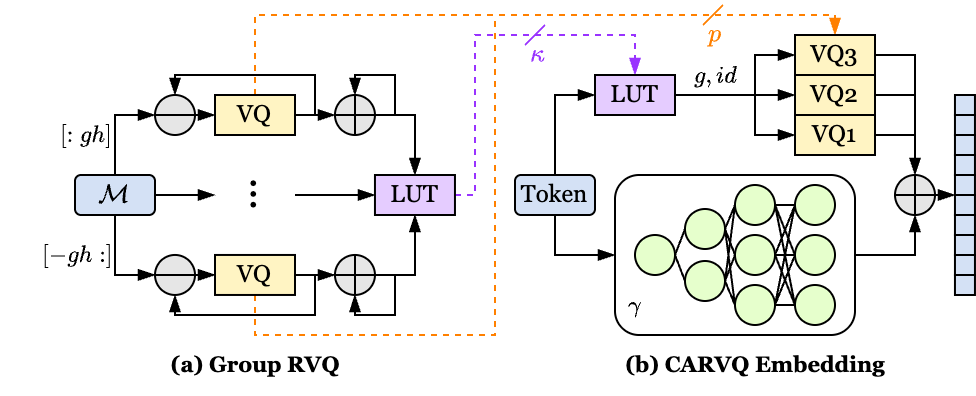
核心思路:论文的核心思路是利用校正适配器(Corrective Adaptor)学习原始嵌入和量化嵌入之间的残差,并通过分组残差向量量化(Group Residual Vector Quantization)对残差进行高效编码。这种方法旨在模仿原始模型的嵌入,从而在压缩的同时尽可能保留模型的表达能力。
技术框架:CARVQ方法主要包含以下几个阶段:1) 量化:首先对原始嵌入进行初步量化。2) 校正适配器训练:训练一个校正适配器,该适配器由线性和非线性映射组成,用于学习量化后的嵌入与原始嵌入之间的差异。3) 分组残差向量量化:将校正适配器的输出进行分组,并对每组残差向量进行向量量化,进一步压缩模型大小。4) 模型集成:将量化后的嵌入和校正适配器集成到原始模型中。
关键创新:CARVQ的关键创新在于校正适配器的设计和分组残差向量量化的应用。校正适配器能够学习并补偿量化带来的信息损失,而分组残差向量量化则进一步提高了压缩效率。与传统的标量量化相比,CARVQ能够更好地保留模型的性能。
关键设计:校正适配器由多个线性层和非线性激活函数组成,其结构可以根据具体模型和任务进行调整。分组残差向量量化将嵌入向量分成多个组,并对每个组独立进行向量量化。分组的大小和码本的大小是重要的超参数,需要根据实际情况进行调整。损失函数通常包括重构损失和正则化项,以保证校正适配器的有效性和模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CARVQ在多个LLM(包括LLaMA-3.2-1B、LLaMA-3.2-3B、Qwen2.5-7B和Phi-4)上实现了显著的压缩效果,达到了约1.6比特的平均比特宽度。在保持合理的困惑度和准确性的前提下,CARVQ优于传统的标量量化方法。例如,在某些任务上,CARVQ能够在几乎不损失性能的情况下,将模型大小压缩到原来的几分之一。
🎯 应用场景
CARVQ技术可广泛应用于边缘设备上LLM的部署,例如智能手机、物联网设备和机器人等。通过降低LLM的内存占用,CARVQ能够使这些设备运行更复杂的AI模型,从而提升用户体验,并为各种应用场景带来新的可能性,例如离线语音识别、本地化机器翻译和智能助手等。
📄 摘要(原文)
Large Language Models (LLMs) typically rely on a large number of parameters for token embedding, leading to substantial storage requirements and memory footprints. In particular, LLMs deployed on edge devices are memory-bound, and reducing the memory footprint by compressing the embedding layer not only frees up the memory bandwidth but also speeds up inference. To address this, we introduce CARVQ, a post-training novel Corrective Adaptor combined with group Residual Vector Quantization. CARVQ relies on the composition of both linear and non-linear maps and mimics the original model embedding to compress to approximately 1.6 bits without requiring specialized hardware to support lower-bit storage. We test our method on pre-trained LLMs such as LLaMA-3.2-1B, LLaMA-3.2-3B, LLaMA-3.2-3B-Instruct, LLaMA-3.1-8B, Qwen2.5-7B, Qwen2.5-Math-7B and Phi-4, evaluating on common generative, discriminative, math and reasoning tasks. We show that in most cases, CARVQ can achieve lower average bitwidth-per-parameter while maintaining reasonable perplexity and accuracy compared to scalar quantization. Our contributions include a novel compression technique that is compatible with state-of-the-art transformer quantization methods and can be seamlessly integrated into any hardware supporting 4-bit memory to reduce the model's memory footprint in memory-constrained devices. This work demonstrates a crucial step toward the efficient deployment of LLMs on edge devices.