On Foundation Models for Temporal Point Processes to Accelerate Scientific Discovery
作者: David Berghaus, Patrick Seifner, Kostadin Cvejoski, Ramses J. Sanchez
分类: cs.LG
发布日期: 2025-10-14 (更新: 2026-01-20)
💡 一句话要点
提出时间点过程基础模型,加速医学、地震学等领域科学发现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间点过程 基础模型 预训练 事件序列分析 科学发现
📋 核心要点
- 传统事件序列分析需为每个数据集构建和训练模型,耗时且成本高昂。
- 本文提出时间点过程基础模型,通过预训练学习事件数据的通用模式。
- 该模型无需重新训练即可分析新数据,并能快速微调以提高精度。
📝 摘要(中文)
许多科学领域,如医学和地震学,依赖于分析随时间推移的事件序列来理解复杂系统。传统上,机器学习模型必须针对每个新数据集从头开始构建和训练,这是一个缓慢且昂贵的过程。本文介绍了一种新方法:一个强大的模型,可以学习上下文中事件数据的潜在模式。该“基础模型”在数百万个模拟事件序列上进行训练,使其对事件如何展开具有通用理解。因此,该模型可以通过查看数据集中的几个示例来立即分析新的科学数据,而无需重新训练。它也可以快速进行微调,以获得更高的准确性。这种方法使复杂的事件分析更易于访问,并加速了科学发现的步伐。
🔬 方法详解
问题定义:论文旨在解决科学领域中事件序列分析的效率问题。现有方法需要针对每个新的数据集从头开始训练模型,这导致了高昂的时间和计算成本,阻碍了科学发现的速度。现有方法缺乏泛化能力,无法利用不同数据集之间的共性知识。
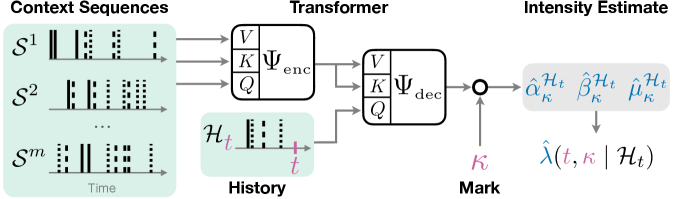
核心思路:论文的核心思路是训练一个通用的“基础模型”,使其能够学习时间点过程的内在模式。通过在大规模模拟数据上进行预训练,该模型能够获得对事件序列的通用理解,从而可以快速适应新的数据集,而无需从头开始训练。这种方法类似于自然语言处理中的预训练语言模型。
技术框架:该论文没有详细描述具体的模型架构,但可以推断其框架如下:1. 数据生成阶段:生成大规模的模拟事件序列数据,用于预训练。2. 预训练阶段:使用模拟数据训练基础模型,目标是学习时间点过程的通用表示。3. 适应阶段:对于新的科学数据集,使用少量样本对基础模型进行微调或直接应用,以进行事件序列分析。
关键创新:该论文的关键创新在于将“基础模型”的概念引入到时间点过程分析领域。与传统的针对特定数据集训练模型的方法不同,该方法旨在构建一个通用的、可迁移的模型,从而大大提高了事件序列分析的效率和可访问性。
关键设计:论文没有提供具体的模型细节,例如网络结构、损失函数等。这些细节是未知的。未来的研究可以探索不同的模型架构和训练策略,以进一步提高基础模型的性能。关键的设计可能包括:用于生成模拟数据的概率模型、用于捕捉时间依赖性的网络结构(例如,循环神经网络或Transformer)、以及用于优化模型参数的损失函数。
🖼️ 关键图片
📊 实验亮点
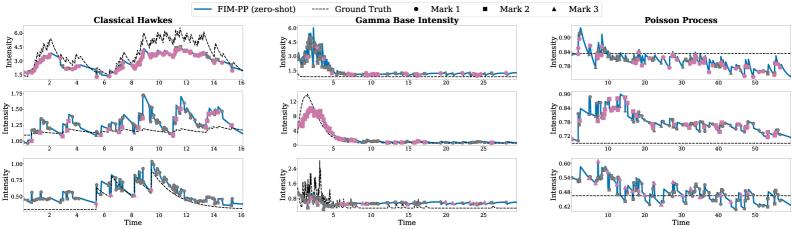
论文的主要亮点在于提出了时间点过程的基础模型,并通过在大量模拟数据上的预训练,使其具备了快速适应新数据集的能力。虽然论文没有提供具体的实验数据,但其核心思想具有重要的理论和实践意义,为未来的研究方向提供了新的思路。该方法有望显著提升事件序列分析的效率和可扩展性。
🎯 应用场景
该研究成果可广泛应用于医学、地震学、金融学等领域,加速对复杂事件序列的分析和理解。例如,在医学领域,可以用于预测疾病爆发、评估治疗效果;在地震学领域,可以用于预测地震发生、分析地震活动规律。该研究的实际价值在于降低了事件序列分析的门槛,使更多科研人员能够利用机器学习技术进行科学研究。
📄 摘要(原文)
Many scientific fields, from medicine to seismology, rely on analyzing sequences of events over time to understand complex systems. Traditionally, machine learning models must be built and trained from scratch for each new dataset, which is a slow and costly process. We introduce a new approach: a single, powerful model that learns the underlying patterns of event data in context. We trained this "foundation model" on millions of simulated event sequences, teaching it a general-purpose understanding of how events can unfold. As a result, our model can analyze new scientific data instantly, without retraining, simply by looking at a few examples from the dataset. It can also be quickly fine-tuned for even higher accuracy. This approach makes sophisticated event analysis more accessible and accelerates the pace of scientific discovery.