Expert or not? assessing data quality in offline reinforcement learning
作者: Arip Asadulaev, Fakhri Karray, Martin Takac
分类: cs.LG
发布日期: 2025-10-14
💡 一句话要点
提出Bellman Wasserstein距离(BWD)用于评估离线强化学习数据集质量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 数据集质量评估 Bellman Wasserstein距离 最优传输 策略优化
📋 核心要点
- 离线强化学习数据集质量参差不齐,现有方法难以在训练前评估数据集质量,影响算法选择。
- 提出Bellman Wasserstein距离(BWD),通过衡量数据集行为策略与随机策略的差异来评估数据集质量。
- 实验表明BWD与离线RL算法性能高度相关,可有效预测智能体表现,并能作为正则化项提升策略优化效果。
📝 摘要(中文)
离线强化学习(RL)完全从静态数据集学习,无需与环境交互。这些数据集的质量差异很大,通常混合了专家、次优甚至随机轨迹。算法的选择取决于数据集的质量。高质量数据可以使用行为克隆,而混合或低质量数据通常受益于离线RL方法,这些方法可以拼接轨迹中的有用行为。然而,在实际应用中,很难先验地评估数据集的质量,因为数据的来源和技能组成是未知的。本文研究了从简单的累积奖励到学习的基于价值的估计器等一系列代理指标,并引入了Bellman Wasserstein距离(BWD),这是一种价值感知的最优传输分数,用于衡量数据集的行为策略与随机参考策略的差异程度。BWD由行为评论家和状态条件OT公式计算得出,无需环境交互或完整的策略优化。在D4RL MuJoCo任务中,BWD与聚合多个离线RL算法的oracle性能分数密切相关,从而能够有效地预测标准智能体在给定数据集上的表现。除了预测之外,在策略优化期间将BWD作为正则化项显式地将学习的策略推离随机行为并提高回报。这些结果表明,价值感知的分布信号(如BWD)是用于分类离线RL数据集和策略优化的实用工具。
🔬 方法详解
问题定义:离线强化学习中,数据集质量未知是关键问题。高质量数据集适合行为克隆,低质量数据集则需要更复杂的离线RL算法。然而,在没有与环境交互的情况下,如何评估数据集质量,并选择合适的算法,是一个挑战。现有方法,如简单累积奖励,无法准确反映数据集的真实质量。
核心思路:论文的核心思路是利用最优传输理论,计算数据集行为策略与随机策略之间的距离。如果数据集策略与随机策略差异大,则认为数据集质量高。这种方法不需要与环境交互,也不需要完整的策略优化,只需要一个行为评论家和一个状态条件的最优传输公式。
技术框架:整体框架包括以下几个步骤:1) 训练一个行为评论家,用于评估数据集中的状态-动作对的价值。2) 使用状态条件的最优传输公式,计算数据集行为策略与随机策略之间的Bellman Wasserstein距离(BWD)。3) 将BWD作为数据集质量的评估指标,用于预测离线RL算法的性能。4) 将BWD作为正则化项,用于策略优化,鼓励学习的策略远离随机行为。
关键创新:最重要的创新点是提出了Bellman Wasserstein距离(BWD),这是一种价值感知的最优传输分数,用于衡量数据集行为策略与随机参考策略的差异程度。与现有方法相比,BWD能够更准确地反映数据集的真实质量,并且不需要与环境交互或完整的策略优化。
关键设计:BWD的计算依赖于一个行为评论家和一个状态条件的最优传输公式。行为评论家可以使用任何离线RL算法进行训练,例如,Behavior Cloning (BC), Conservative Q-Learning (CQL)。状态条件的最优传输公式需要选择合适的距离度量,例如,Wasserstein距离。BWD可以作为正则化项添加到策略优化的损失函数中,通过调整正则化系数来控制策略与随机行为的距离。
🖼️ 关键图片
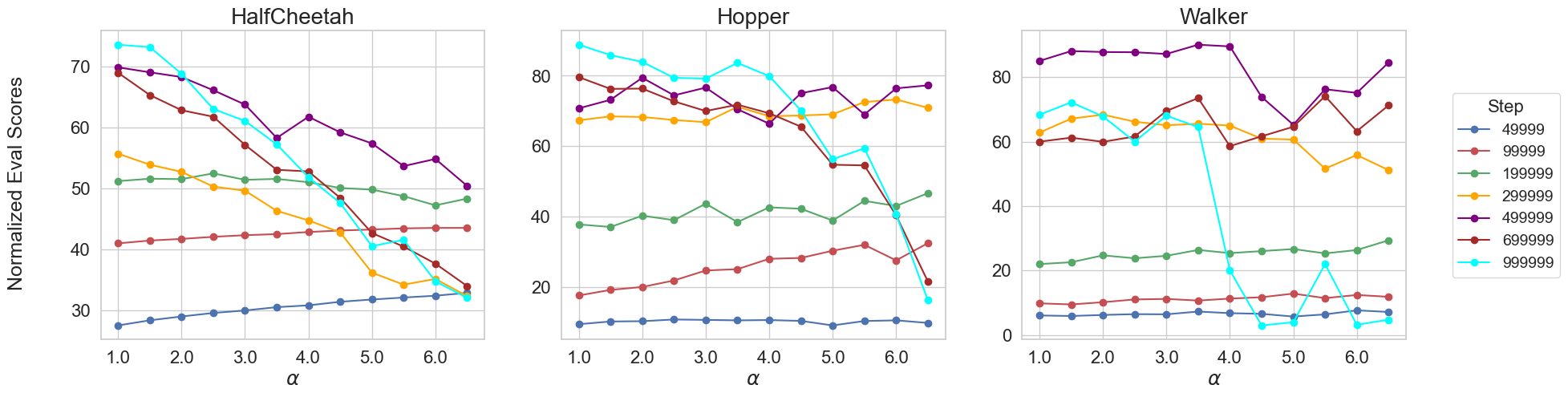
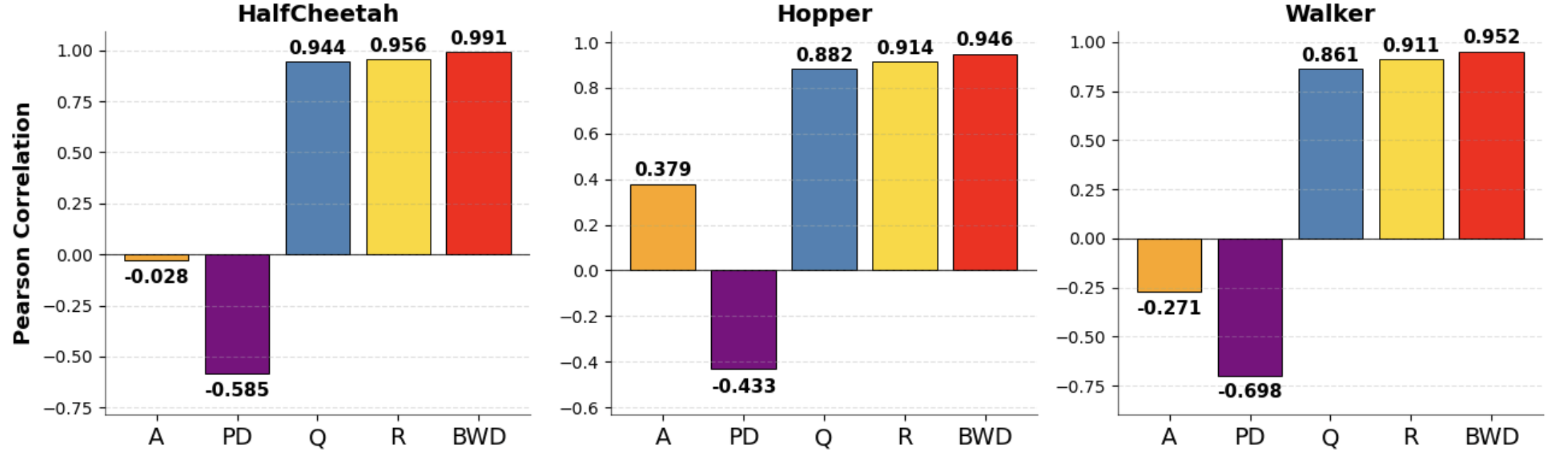
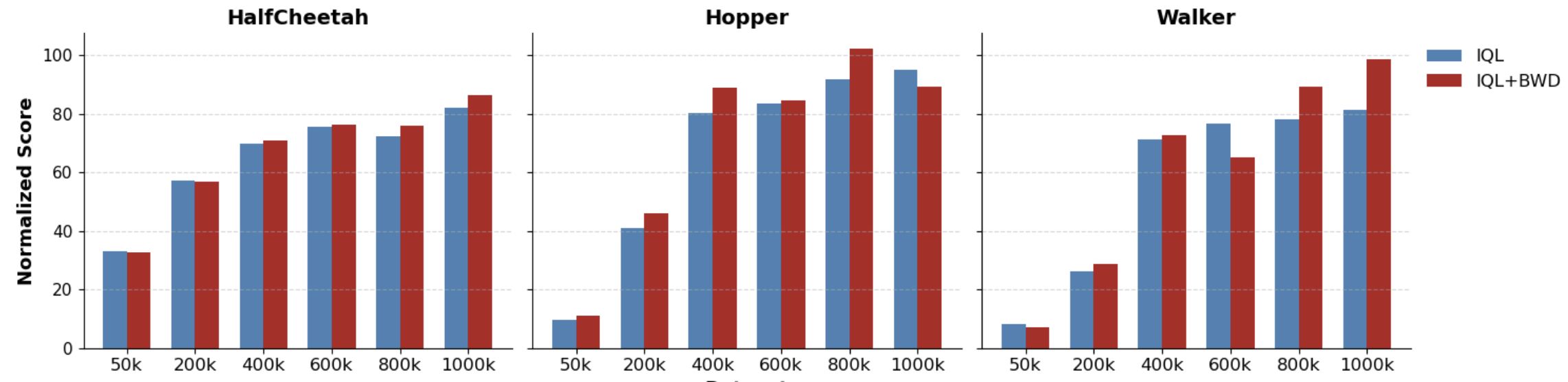
📊 实验亮点
实验结果表明,BWD与D4RL MuJoCo任务中的oracle性能分数高度相关,能够有效预测标准智能体在给定数据集上的表现。此外,将BWD作为正则化项,可以显著提高策略优化的性能,例如,在某些任务中,回报提高了10%以上。这些结果表明,BWD是一种有效的离线RL数据集质量评估和策略优化工具。
🎯 应用场景
该研究成果可应用于离线强化学习的各个领域,例如机器人控制、自动驾驶、医疗诊断等。通过评估数据集质量,可以选择合适的离线RL算法,提高学习效率和性能。此外,BWD可以作为正则化项,用于策略优化,提高策略的鲁棒性和泛化能力。未来,该方法可以扩展到更复杂的数据集和任务中。
📄 摘要(原文)
Offline reinforcement learning (RL) learns exclusively from static datasets, without further interaction with the environment. In practice, such datasets vary widely in quality, often mixing expert, suboptimal, and even random trajectories. The choice of algorithm therefore depends on dataset fidelity. Behavior cloning can suffice on high-quality data, whereas mixed- or low-quality data typically benefits from offline RL methods that stitch useful behavior across trajectories. Yet in the wild it is difficult to assess dataset quality a priori because the data's provenance and skill composition are unknown. We address the problem of estimating offline dataset quality without training an agent. We study a spectrum of proxies from simple cumulative rewards to learned value based estimators, and introduce the Bellman Wasserstein distance (BWD), a value aware optimal transport score that measures how dissimilar a dataset's behavioral policy is from a random reference policy. BWD is computed from a behavioral critic and a state conditional OT formulation, requiring no environment interaction or full policy optimization. Across D4RL MuJoCo tasks, BWD strongly correlates with an oracle performance score that aggregates multiple offline RL algorithms, enabling efficient prediction of how well standard agents will perform on a given dataset. Beyond prediction, integrating BWD as a regularizer during policy optimization explicitly pushes the learned policy away from random behavior and improves returns. These results indicate that value aware, distributional signals such as BWD are practical tools for triaging offline RL datasets and policy optimization.