Laminar: A Scalable Asynchronous RL Post-Training Framework
作者: Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, Haibin Lin, Xin Liu, Chuan Wu
分类: cs.LG, cs.AI, cs.DC
发布日期: 2025-10-14
💡 一句话要点
Laminar:一种可扩展的异步RL后训练框架,解决GPU利用率低的问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大规模语言模型 后训练 异步训练 分布式系统 GPU利用率 长尾问题
📋 核心要点
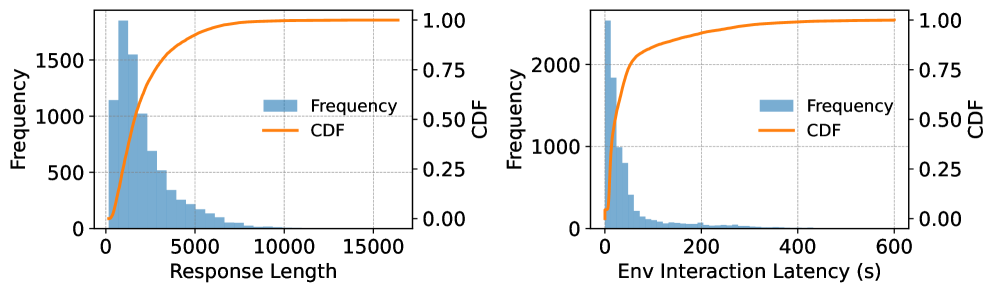
- 现有RL框架在LLM后训练中面临GPU利用率低的挑战,原因是轨迹生成存在严重的长尾分布。
- Laminar通过完全解耦的架构,实现轨迹级别的异步,允许rollout独立生成和消耗轨迹,打破全局同步的限制。
- 实验表明,Laminar在1024-GPU集群上实现了高达5.48倍的训练吞吐量加速,并缩短了模型收敛时间。
📝 摘要(中文)
针对大型语言模型(LLMs)的强化学习(RL)后训练目前正在扩展到大型集群,并长时间运行以提高模型的推理性能。然而,现有RL框架的可扩展性受到限制,因为RL轨迹生成中极端的长尾倾斜导致严重的GPU利用率不足。现有的异步RL系统试图缓解这个问题,但它们依赖于actor和所有rollout之间的全局权重同步,这创建了一个刚性的模型更新计划。这种全局同步不适合RL训练中轨迹生成延迟的高度倾斜和不断变化的分布,从而降低了训练效率。我们的关键见解是,高效扩展需要通过轨迹级别的异步来打破这种锁定,从而独立地生成和消耗每个轨迹。我们提出了Laminar,这是一个构建在完全解耦架构上的可扩展且健壮的RL后训练系统。首先,我们用充当分布式参数服务的一层relay worker取代全局更新。这实现了异步和细粒度的权重同步,允许rollout随时提取最新的权重,而不会使actor的训练循环停滞。其次,一种动态重新打包机制将长尾轨迹整合到一些专用的rollout上,从而最大限度地提高生成吞吐量。完全解耦的设计还可以隔离故障,确保长时间运行作业的鲁棒性。我们在一个1024-GPU集群上的评估表明,Laminar实现了比最先进的系统高达5.48倍的训练吞吐量加速,同时减少了模型收敛时间。
🔬 方法详解
问题定义:现有强化学习框架在大型语言模型(LLM)的后训练阶段,由于强化学习轨迹生成过程中的长尾效应,导致GPU资源利用率严重不足。全局同步机制使得训练效率低下,无法充分利用计算资源。现有异步RL系统虽然尝试缓解这个问题,但其全局权重同步策略限制了训练效率,无法适应轨迹生成延迟的高度倾斜和动态变化。
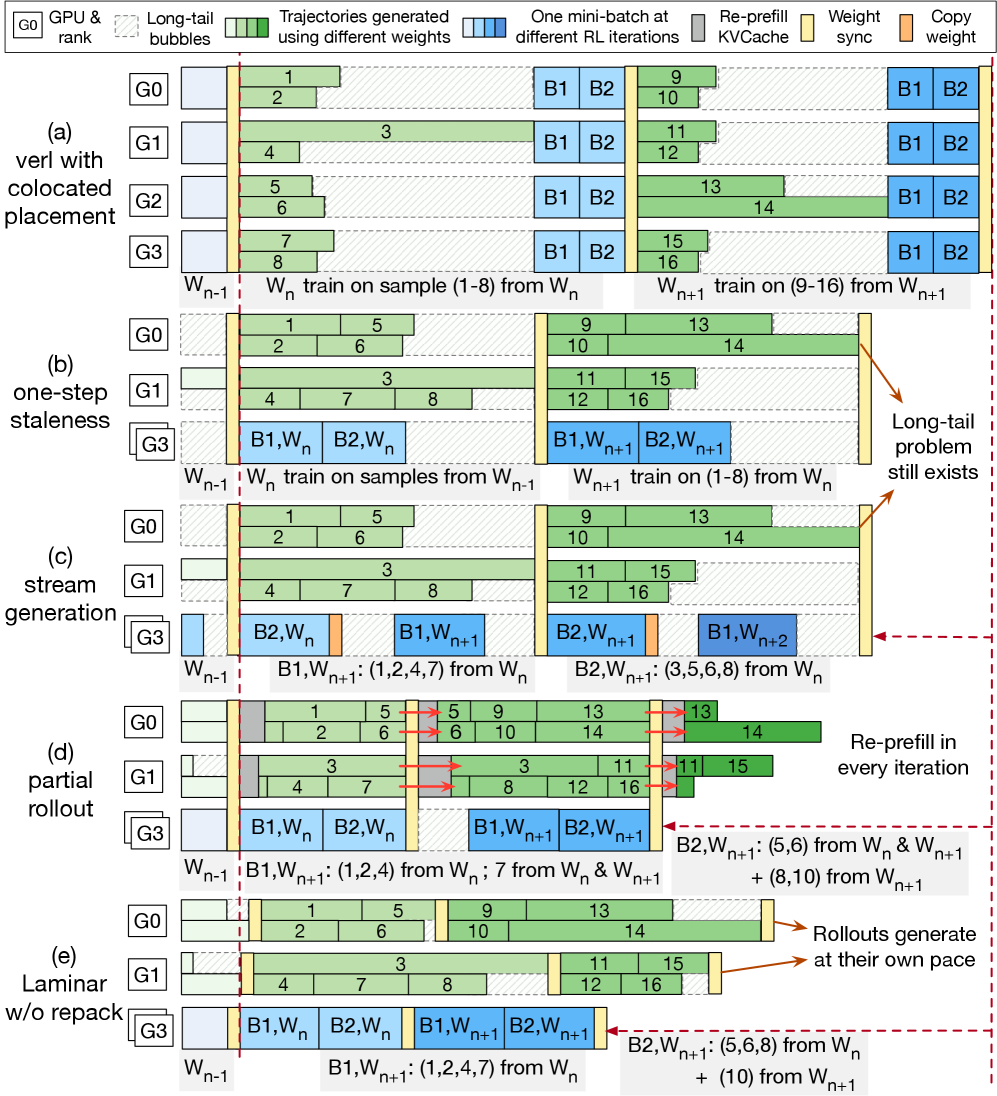
核心思路:Laminar的核心思路是通过完全解耦的架构,实现轨迹级别的异步处理。这意味着每个轨迹的生成和消耗都是独立进行的,从而打破了全局同步的限制。通过这种方式,Laminar能够更好地适应轨迹生成延迟的动态变化,提高GPU利用率和训练效率。
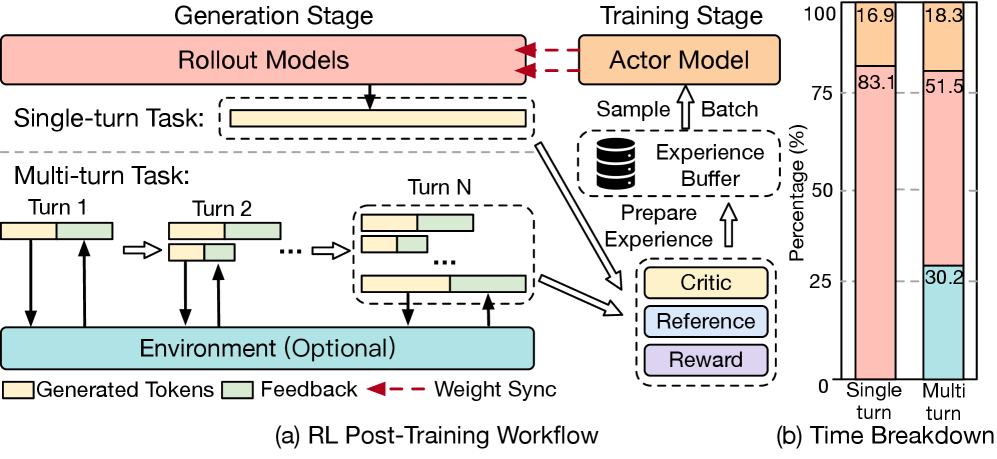
技术框架:Laminar采用完全解耦的架构,主要包含以下几个模块:Actor(负责模型训练)、Relay Workers(作为分布式参数服务,负责权重同步)和Rollouts(负责轨迹生成)。Actor不再直接与Rollouts进行全局同步,而是通过Relay Workers进行异步的细粒度权重同步。动态重新打包机制将长尾轨迹整合到专用Rollouts上,提高生成吞吐量。
关键创新:Laminar的关键创新在于其完全解耦的异步架构,以及轨迹级别的异步处理。与现有方法依赖全局同步不同,Laminar允许Rollouts随时从Relay Workers拉取最新的权重,而不会阻塞Actor的训练循环。这种异步机制能够更好地适应轨迹生成延迟的动态变化,提高训练效率。
关键设计:Laminar的关键设计包括:1) 使用Relay Workers作为分布式参数服务,实现细粒度的异步权重同步;2) 动态重新打包机制,将长尾轨迹整合到专用Rollouts上,提高生成吞吐量;3) 完全解耦的架构,隔离故障,提高系统的鲁棒性。具体的参数设置、损失函数和网络结构等细节未在摘要中明确提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
Laminar在1024-GPU集群上的实验结果表明,其训练吞吐量比最先进的系统提高了高达5.48倍,同时减少了模型收敛时间。这表明Laminar在提高训练效率和降低训练成本方面具有显著优势。
🎯 应用场景
Laminar适用于大规模语言模型的强化学习后训练,可以提高模型推理性能。该框架能够有效利用大规模GPU集群资源,加速模型训练过程,降低训练成本。未来,Laminar有望应用于各种需要大规模强化学习训练的场景,例如机器人控制、游戏AI等。
📄 摘要(原文)
Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.