Traveling Salesman-Based Token Ordering Improves Stability in Homomorphically Encrypted Language Models
作者: Donghwan Rho, Sieun Seo, Hyewon Sung, Chohong Min, Ernest K. Ryu
分类: cs.LG, cs.CR
发布日期: 2025-10-14
备注: 34 pages
💡 一句话要点
提出基于旅行商问题的Token重排序方法,提升同态加密语言模型的稳定性
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 同态加密 语言模型 文本生成 旅行商问题 隐私保护 Token重排序
📋 核心要点
- 在同态加密的LLM中,文本生成面临挑战,特别是下一个token预测,现有方法关注不足。
- 提出基于旅行商问题(TSP)的token重排序策略,优化加密文本生成过程,并进行后处理。
- 实验表明,该方法能防止模型崩溃,提升生成文本的连贯性,并保障数据隐私。
📝 摘要(中文)
随着用户越来越多地使用私有信息与大型语言模型(LLM)交互,安全和加密通信变得至关重要。同态加密(HE)提供了一种原则性的解决方案,可以直接对加密数据进行计算。虽然之前的工作已经探索了在HE下运行LLM的各个方面,但文本生成,特别是下一个token预测的挑战,受到的关注有限,并且仍然是实际加密交互的关键障碍。在这项工作中,我们提出了一种基于TSP的token重排序策略,以解决加密文本生成的难题,以及一个进一步减少近似误差的后处理步骤。理论分析和实验结果表明,我们的方法可以防止崩溃,提高生成文本的连贯性,并在整个过程中保持数据隐私。总的来说,我们的贡献提高了实际和保护隐私的LLM推理的可行性。
🔬 方法详解
问题定义:论文旨在解决同态加密(HE)环境下,大型语言模型(LLM)进行文本生成时遇到的稳定性问题,尤其是在下一个token预测方面。现有的方法在加密状态下进行文本生成时,由于计算复杂性和噪声累积,容易导致模型崩溃,生成不连贯或无意义的文本。
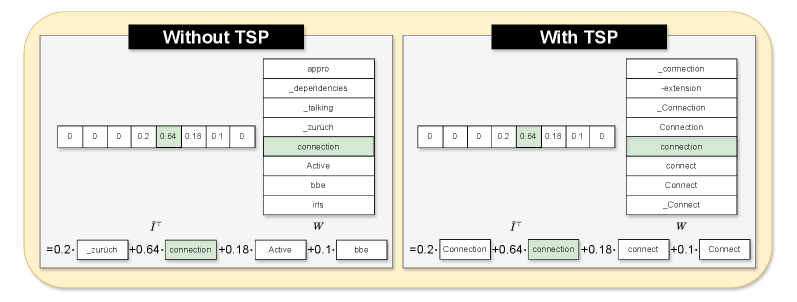
核心思路:论文的核心思路是利用旅行商问题(TSP)的优化方法,对token序列进行重排序,使得在同态加密计算过程中,相邻token之间的依赖关系更加紧密,从而减少噪声累积和计算误差。通过优化token的排列顺序,降低了加密计算的复杂度,提高了生成文本的质量和连贯性。
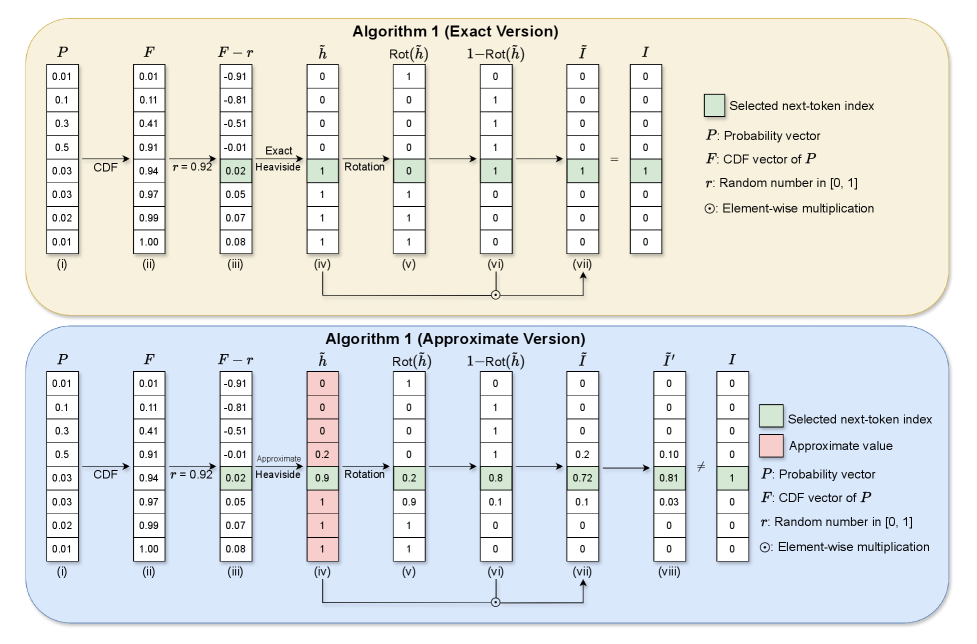
技术框架:整体框架包括三个主要阶段:1) Token嵌入与加密:将输入文本转换为token序列,并使用同态加密算法对token嵌入进行加密。2) TSP重排序:利用TSP算法对加密的token序列进行重排序,目标是最小化相邻token之间的距离(距离可以定义为某种语义相似度或依赖关系)。3) 加密计算与后处理:在加密状态下进行LLM的计算,生成下一个token的预测结果。然后,对预测结果进行后处理,以进一步减少近似误差,并解密得到最终的文本输出。
关键创新:最重要的技术创新点在于将TSP优化方法引入到同态加密的LLM文本生成过程中。与传统的逐个token生成方法相比,TSP重排序能够全局优化token序列,减少加密计算中的噪声累积,从而显著提高生成文本的质量和稳定性。此外,后处理步骤也进一步提升了模型的性能。
关键设计:TSP算法的具体实现需要定义token之间的距离度量。论文可能采用了基于语义相似度或依赖关系的度量方法。此外,TSP求解器的选择(例如,近似算法或精确算法)也会影响计算效率和优化效果。后处理步骤可能包括一些平滑滤波或校正技术,以减少近似误差。具体的同态加密方案选择也会影响整体性能,例如选择支持高效乘法运算的方案。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出的TSP-based token重排序策略的有效性。实验结果表明,该方法能够显著提高同态加密LLM生成文本的连贯性和稳定性,有效防止模型崩溃。具体的性能数据(例如,BLEU score或其他文本生成质量指标)以及与基线方法的对比结果(例如,未采用TSP重排序的同态加密LLM)将在论文中详细展示。
🎯 应用场景
该研究成果可应用于需要保护用户隐私的各种场景,例如:医疗健康领域,用户可以安全地与AI助手交互,获取个性化的健康建议;金融服务领域,用户可以安全地进行投资咨询和交易;以及其他任何涉及敏感数据处理的场景,例如法律咨询、教育辅导等。该技术有助于构建更加安全和可信赖的AI服务。
📄 摘要(原文)
As users increasingly interact with large language models (LLMs) using private information, secure and encrypted communication becomes essential. Homomorphic encryption (HE) provides a principled solution by enabling computation directly on encrypted data. Although prior work has explored aspects of running LLMs under HE, the challenge of text generation, particularly next-token prediction, has received limited attention and remains a key obstacle to practical encrypted interaction. In this work, we propose a TSP-based token reordering strategy to address the difficulties of encrypted text generation, together with a post-processing step that further reduces approximation error. Theoretical analysis and experimental results demonstrate that our method prevents collapse, improves coherence in generated text, and preserves data privacy throughout. Overall, our contributions advance the feasibility of practical and privacy-preserving LLM inference.