Rethinking the Role of Dynamic Sparse Training for Scalable Deep Reinforcement Learning
作者: Guozheng Ma, Lu Li, Zilin Wang, Haoyu Wang, Shengchao Hu, Leszek Rutkowski, Dacheng Tao
分类: cs.LG
发布日期: 2025-10-14
💡 一句话要点
提出模块化动态稀疏训练框架MST,提升深度强化学习模型的可扩展性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 动态稀疏训练 模型可扩展性 模块特定训练 神经网络优化
📋 核心要点
- 深度强化学习中,增大模型规模反而可能导致性能下降,这是由于优化过程中的可塑性损失等问题。
- 论文提出模块特定训练(MST)框架,针对编码器、评论器和演员等不同模块采用不同的动态稀疏训练策略。
- 实验表明,MST框架能够有效提升深度强化学习模型的可扩展性,且无需修改底层算法。
📝 摘要(中文)
扩展神经网络在机器学习领域取得了突破性进展,但在深度强化学习(DRL)中,由于独特优化病理(如可塑性损失),更大的模型通常会降低性能。虽然最近的研究表明,在训练期间动态调整网络拓扑可以缓解这些问题,但现有研究存在三个关键限制:(1)对所有模块应用统一的动态训练策略,而忽略了编码器、评论器和演员遵循不同的学习范式;(2)侧重于基本架构的评估,而没有阐明动态训练与架构改进之间的相对重要性和相互作用;(3)缺乏对不同动态方法(包括稀疏到稀疏、密集到稀疏和稀疏到密集)的系统比较。通过对模块和架构的全面研究,我们发现动态稀疏训练策略提供了模块特定的优势,补充了架构改进所建立的主要可扩展性基础。最后,我们将这些见解提炼为模块特定训练(MST),这是一个实用的框架,可以进一步利用架构改进的优势,并在各种RL算法中展示出显著的可扩展性提升,而无需算法修改。
🔬 方法详解
问题定义:深度强化学习中,简单地增大模型规模并不能带来性能提升,反而可能由于可塑性损失等优化问题导致性能下降。现有的动态稀疏训练方法通常采用统一的策略,忽略了不同模块(如编码器、评论器和演员)的学习特性差异,并且缺乏对动态训练与架构改进之间关系的深入研究。
核心思路:论文的核心思路是针对深度强化学习模型中的不同模块,采用模块特定的动态稀疏训练策略。通过分析不同模块的学习特性,为每个模块选择最合适的稀疏化方法(如稀疏到稀疏、密集到稀疏、稀疏到密集),从而最大化动态稀疏训练的收益。
技术框架:论文提出的模块特定训练(MST)框架主要包含以下几个步骤:首先,对深度强化学习模型进行模块划分,例如划分为编码器、评论器和演员等模块。然后,针对每个模块,选择合适的动态稀疏训练策略。最后,将这些模块特定的训练策略集成到现有的深度强化学习算法中进行训练。
关键创新:论文的关键创新在于提出了模块特定的动态稀疏训练策略。与现有的统一动态稀疏训练方法不同,MST框架能够根据不同模块的学习特性,选择最合适的稀疏化方法,从而更有效地提升模型的性能和可扩展性。
关键设计:论文的关键设计包括:(1)针对不同模块选择不同的稀疏化方法,例如,对于编码器,可能采用稀疏到稀疏的训练策略,以保持其特征提取能力;对于评论器,可能采用密集到稀疏的训练策略,以提高其泛化能力;(2)设计合适的稀疏度调整策略,例如,可以根据训练的进度动态调整稀疏度,以平衡模型的性能和计算效率;(3)将MST框架与现有的深度强化学习算法无缝集成,无需修改底层算法。
🖼️ 关键图片

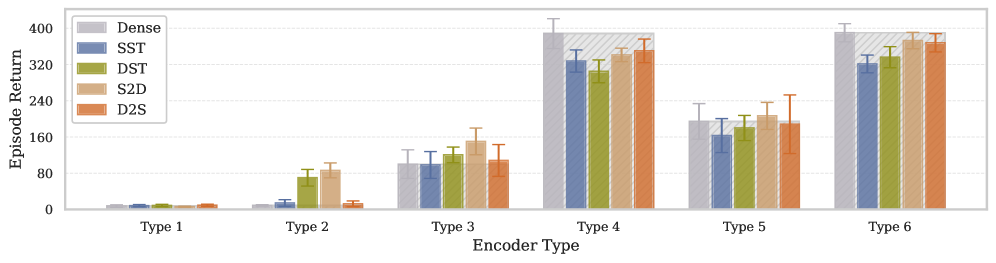

📊 实验亮点
论文通过实验验证了MST框架的有效性。实验结果表明,MST框架能够显著提升深度强化学习模型的可扩展性,并在各种RL算法中取得了性能提升,而无需修改底层算法。具体的性能提升数据在论文中给出,与基线方法相比,MST框架在多个benchmark上均取得了显著的性能提升。
🎯 应用场景
该研究成果可应用于各种需要大规模深度强化学习模型的场景,例如机器人控制、游戏AI、自动驾驶等。通过提升模型的可扩展性,可以训练出更强大的智能体,解决更复杂的实际问题。未来,该方法有望推动深度强化学习在更多领域的应用。
📄 摘要(原文)
Scaling neural networks has driven breakthrough advances in machine learning, yet this paradigm fails in deep reinforcement learning (DRL), where larger models often degrade performance due to unique optimization pathologies such as plasticity loss. While recent works show that dynamically adapting network topology during training can mitigate these issues, existing studies have three critical limitations: (1) applying uniform dynamic training strategies across all modules despite encoder, critic, and actor following distinct learning paradigms, (2) focusing evaluation on basic architectures without clarifying the relative importance and interaction between dynamic training and architectural improvements, and (3) lacking systematic comparison between different dynamic approaches including sparse-to-sparse, dense-to-sparse, and sparse-to-dense. Through comprehensive investigation across modules and architectures, we reveal that dynamic sparse training strategies provide module-specific benefits that complement the primary scalability foundation established by architectural improvements. We finally distill these insights into Module-Specific Training (MST), a practical framework that further exploits the benefits of architectural improvements and demonstrates substantial scalability gains across diverse RL algorithms without algorithmic modifications.