Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models
作者: Samuel Lippl, Thomas McGee, Kimberly Lopez, Ziwen Pan, Pierce Zhang, Salma Ziadi, Oliver Eberle, Ida Momennejad
分类: cs.LG, cs.AI
发布日期: 2025-10-13
💡 一句话要点
提出一种追踪和操控LLM推理过程的算法原语框架,揭示其组合几何特性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 算法原语 推理过程 可解释性 组合几何 函数向量 残差流
📋 核心要点
- 现有方法难以理解大型语言模型(LLM)在多步推理中潜在的计算机制和推理过程。
- 本文提出一种框架,通过追踪和操控算法原语,将推理轨迹与内部激活模式关联,揭示LLM推理的组合几何特性。
- 实验表明,算法原语可以跨任务和模型迁移,推理微调能够增强跨领域的算法泛化能力,并在Phi-4模型上验证了该框架的有效性。
📝 摘要(中文)
本文介绍了一种用于追踪和引导大型语言模型(LLM)推理过程的算法原语的框架。该方法将推理轨迹与内部激活模式联系起来,并通过将算法原语注入残差流并测量其对推理步骤和任务性能的影响来评估算法原语。研究考虑了四个基准:旅行商问题(TSP)、3SAT、AIME和图导航。通过聚类神经激活并标记其匹配的推理轨迹来操作原语。然后,应用函数向量方法来推导原语向量,作为推理的可重用组合构建块。原语向量可以通过加法、减法和标量运算进行组合,揭示激活空间中的几何逻辑。跨任务和跨模型评估(Phi-4、Phi-4-Reasoning、Llama-3-8B)显示了共享的和特定于任务的原语。值得注意的是,将Phi-4与其推理微调变体进行比较,突出了微调后的组合泛化:Phi-4-Reasoning表现出更系统地使用验证和路径生成原语。在Phi-4-Base中注入相关的原语向量会诱导与Phi-4-Reasoning相关的行为特征。总之,这些发现表明,LLM中的推理可能受到算法原语的组合几何的支持,原语可以跨任务和跨模型转移,并且推理微调可以加强跨领域的算法泛化。
🔬 方法详解
问题定义:大型语言模型(LLM)在解决复杂推理问题时,其内部的计算过程和推理机制仍然是一个黑盒。现有的方法难以有效地追踪和理解LLM如何利用其内部的知识和计算资源来完成多步推理任务。因此,如何揭示LLM推理过程中的基本算法单元,并理解它们之间的组合关系,是本文要解决的核心问题。
核心思路:本文的核心思路是将LLM的推理过程分解为一系列可追踪和可操控的算法原语。通过识别这些原语,并研究它们在激活空间中的几何表示,可以更好地理解LLM的推理机制。此外,通过注入和操控这些原语,可以控制LLM的推理行为,从而验证对推理过程的理解。
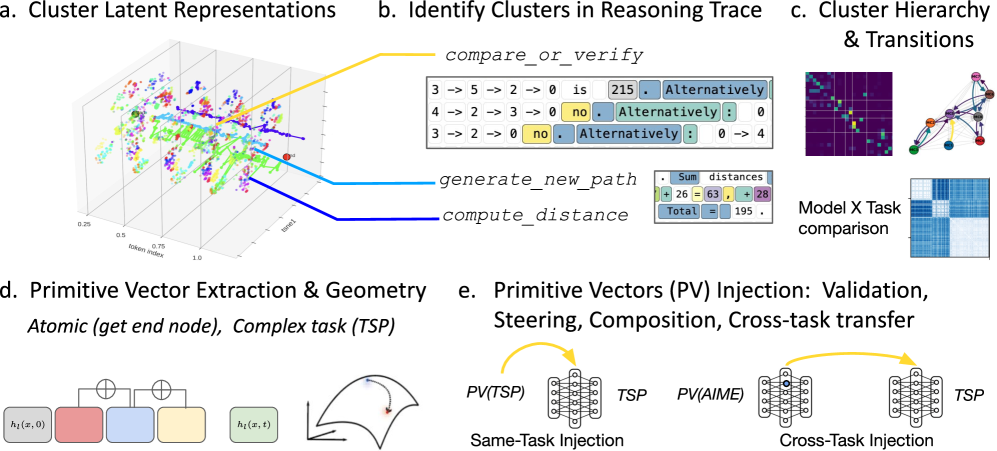
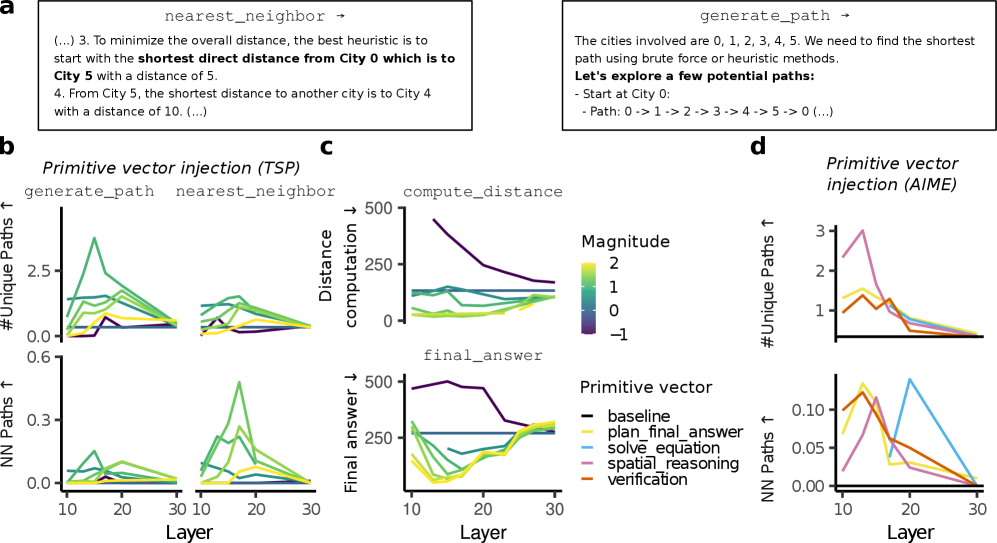
技术框架:该框架主要包含以下几个阶段:1) 推理轨迹追踪:记录LLM在执行推理任务时的中间步骤和状态。2) 激活模式聚类:对LLM内部的神经激活进行聚类,识别具有相似功能的神经元群体。3) 原语标记:将聚类后的激活模式与推理轨迹中的特定步骤或操作关联,从而标记出算法原语。4) 原语向量化:使用函数向量方法,将算法原语表示为激活空间中的向量。5) 原语组合:通过加法、减法和标量运算等方式组合原语向量,模拟LLM的推理过程。6) 原语注入:将原语向量注入到LLM的残差流中,观察其对推理步骤和任务性能的影响。
关键创新:该论文的关键创新在于提出了一种将LLM的推理过程分解为可追踪和可操控的算法原语的框架。与以往的研究不同,该方法不仅关注LLM的输入输出行为,更深入地挖掘了LLM内部的计算过程。通过将算法原语表示为激活空间中的向量,并研究它们之间的几何关系,揭示了LLM推理的组合几何特性。
关键设计:在激活模式聚类阶段,使用了K-means等聚类算法,并根据任务的特点选择了合适的聚类数量。在原语向量化阶段,使用了函数向量方法,将激活模式映射到激活空间中的向量。在原语注入阶段,需要仔细调整注入的强度和位置,以避免对LLM的正常功能造成干扰。此外,论文还设计了一系列实验,用于评估原语的有效性和泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架能够有效地识别和操控LLM的算法原语。跨任务和跨模型评估显示,算法原语具有一定的泛化能力。例如,在Phi-4模型上,注入验证和路径生成原语可以诱导与推理微调后的Phi-4-Reasoning模型相似的行为特征。此外,实验还表明,推理微调可以增强LLM的算法泛化能力。
🎯 应用场景
该研究成果可应用于提升LLM的可解释性和可控性,例如,通过操控算法原语来引导LLM进行特定类型的推理,或诊断LLM推理失败的原因。此外,该方法还可以用于开发更高效的LLM训练方法,例如,通过学习和组合算法原语来加速LLM的训练过程。该研究对于开发更安全、可靠和可信赖的人工智能系统具有重要意义。
📄 摘要(原文)
How do latent and inference time computations enable large language models (LLMs) to solve multi-step reasoning? We introduce a framework for tracing and steering algorithmic primitives that underlie model reasoning. Our approach links reasoning traces to internal activation patterns and evaluates algorithmic primitives by injecting them into residual streams and measuring their effect on reasoning steps and task performance. We consider four benchmarks: Traveling Salesperson Problem (TSP), 3SAT, AIME, and graph navigation. We operationalize primitives by clustering neural activations and labeling their matched reasoning traces. We then apply function vector methods to derive primitive vectors as reusable compositional building blocks of reasoning. Primitive vectors can be combined through addition, subtraction, and scalar operations, revealing a geometric logic in activation space. Cross-task and cross-model evaluations (Phi-4, Phi-4-Reasoning, Llama-3-8B) show both shared and task-specific primitives. Notably, comparing Phi-4 with its reasoning-finetuned variant highlights compositional generalization after finetuning: Phi-4-Reasoning exhibits more systematic use of verification and path-generation primitives. Injecting the associated primitive vectors in Phi-4-Base induces behavioral hallmarks associated with Phi-4-Reasoning. Together, these findings demonstrate that reasoning in LLMs may be supported by a compositional geometry of algorithmic primitives, that primitives transfer cross-task and cross-model, and that reasoning finetuning strengthens algorithmic generalization across domains.