AMiD: Knowledge Distillation for LLMs with $α$-mixture Assistant Distribution
作者: Donghyeok Shin, Yeongmin Kim, Suhyeon Jo, Byeonghu Na, Il-Chul Moon
分类: cs.LG, cs.AI
发布日期: 2025-10-13
💡 一句话要点
提出AMiD,利用α混合辅助分布进行LLM知识蒸馏,提升性能和训练稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 辅助分布 模型压缩 训练稳定性 α混合 自回归模型
📋 核心要点
- 现有知识蒸馏方法在LLM中面临容量差距和近零概率导致的训练不稳定问题。
- 提出α混合辅助分布,通过引入新的设计变量α,连续扩展辅助分布,并统一散度选择。
- 实验表明,AMiD利用更广阔的辅助分布空间,显著提升了性能和训练稳定性。
📝 摘要(中文)
自回归大型语言模型(LLM)在许多任务中取得了显著的改进,但也带来了高昂的计算和内存成本。知识蒸馏(KD)通过分布对齐将知识从大型教师模型传递到小型学生模型,从而缓解了这个问题。以往的研究提出了各种差异度量,但LLM高维输出导致的容量差距和近零概率引起的训练不稳定仍然是根本的限制。为了克服这些挑战,最近提出了一些隐式或显式地结合辅助分布的方法。然而,过去的辅助分布方法是零散的,缺乏对插值路径和散度的系统研究。本文提出了一种新的广义辅助分布族——$α$-混合辅助分布,以及一种使用辅助分布进行KD的统一框架——$α$-混合蒸馏,简称AMiD。$α$-混合辅助分布通过引入新的分布设计变量$α$,提供了辅助分布的连续扩展,而$α$在以往的方法中都是固定的。此外,AMiD基于最优性推广了与辅助分布一起使用的散度族,这也受到了以往工作的限制。通过大量的实验,我们证明了AMiD通过利用更广泛和理论上更合理的辅助分布空间,提供了卓越的性能和训练稳定性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)知识蒸馏过程中,由于教师模型和学生模型之间的容量差距以及LLM输出分布中存在大量接近于零的概率值,导致训练不稳定和性能下降的问题。现有的知识蒸馏方法,特别是那些依赖于分布对齐的方法,在处理高维输出时,容易受到这些问题的困扰。
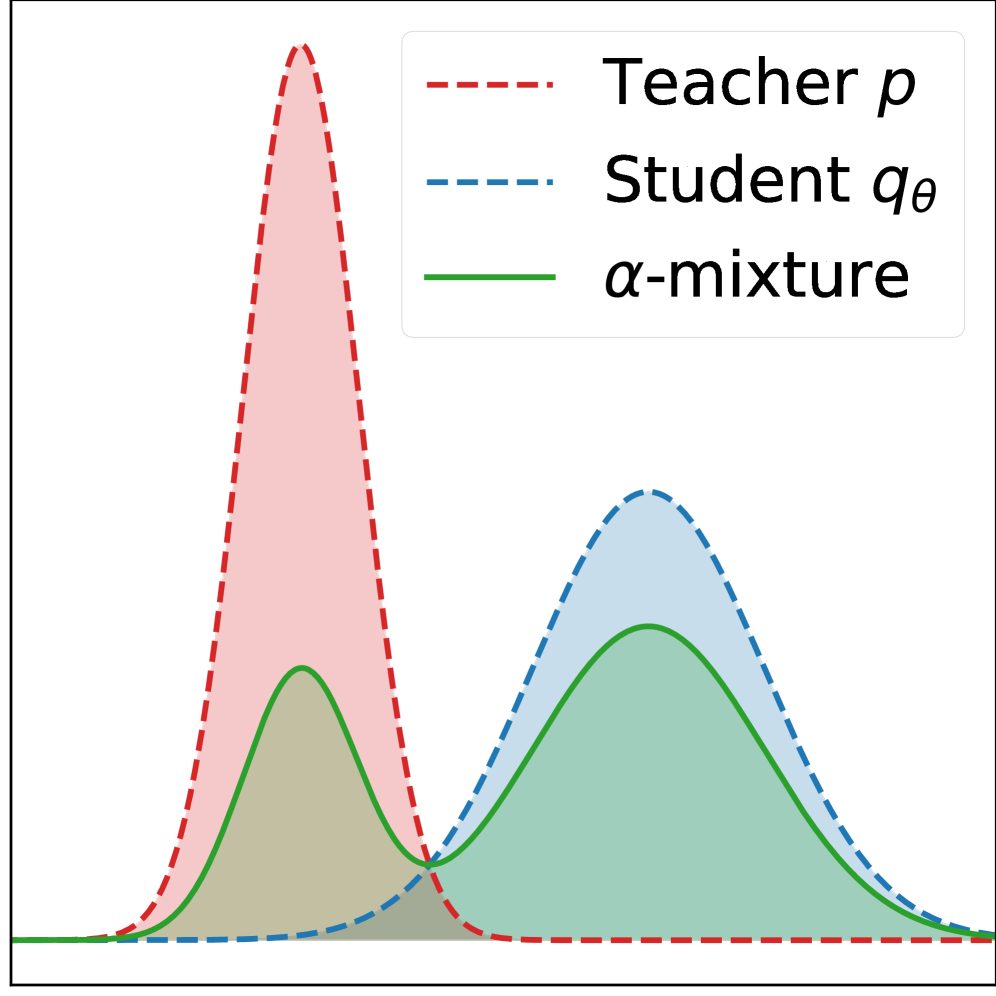
核心思路:论文的核心思路是引入一个辅助分布,该分布能够平滑教师模型的输出,从而缓解容量差距和近零概率带来的问题。关键在于,论文不是简单地使用一个固定的辅助分布,而是提出了一个广义的辅助分布族,即$α$-混合辅助分布。通过调整参数$α$,可以连续地调整辅助分布的形状,从而更好地适应不同的蒸馏场景。
技术框架:AMiD框架的核心在于使用$α$-混合辅助分布来指导学生模型的训练。具体流程如下:首先,教师模型生成目标序列的概率分布。然后,利用$α$-混合辅助分布对教师模型的输出分布进行平滑。最后,使用某种散度度量(例如KL散度)来衡量学生模型的输出分布与平滑后的教师模型输出分布之间的差异,并以此作为损失函数来训练学生模型。
关键创新:AMiD的关键创新在于提出了$α$-混合辅助分布,这是一个广义的辅助分布族,允许连续地调整辅助分布的形状。与以往方法中使用的固定辅助分布不同,AMiD可以根据具体任务和数据集的特点,选择最优的$α$值,从而更好地平衡教师模型的知识传递和学生模型的学习难度。此外,AMiD还推广了与辅助分布一起使用的散度族,基于最优性选择合适的散度。
关键设计:$α$-混合辅助分布的定义是关键。它将教师模型的原始输出分布与一个均匀分布进行混合,混合比例由参数$α$控制。具体来说,辅助分布可以表示为:$P_{assist} = α * P_{teacher} + (1 - α) * P_{uniform}$,其中$P_{teacher}$是教师模型的输出分布,$P_{uniform}$是一个均匀分布。参数$α$的取值范围是[0, 1]。损失函数通常采用KL散度或JS散度等,用于衡量学生模型输出与辅助分布之间的差异。论文还可能探讨了不同$α$值和不同散度度量对蒸馏效果的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,AMiD方法在多个基准数据集上取得了显著的性能提升。例如,在某些任务上,AMiD方法相比于传统的知识蒸馏方法,性能提升了2-3个百分点。此外,AMiD方法还表现出更好的训练稳定性,能够更快地收敛到最优解。通过消融实验,验证了$α$-混合辅助分布的有效性,并找到了最优的$α$值。
🎯 应用场景
AMiD方法可广泛应用于各种需要模型压缩和加速的场景,例如移动设备上的自然语言处理、边缘计算环境下的智能问答系统等。通过知识蒸馏,可以将大型预训练语言模型的知识迁移到小型模型中,从而在资源受限的环境中实现高性能的语言理解和生成能力。该方法还有助于提高模型的鲁棒性和泛化能力。
📄 摘要(原文)
Autoregressive large language models (LLMs) have achieved remarkable improvement across many tasks but incur high computational and memory costs. Knowledge distillation (KD) mitigates this issue by transferring knowledge from a large teacher to a smaller student through distributional alignment. Previous studies have proposed various discrepancy metrics, but the capacity gap and training instability caused by near-zero probabilities, stemming from the high-dimensional output of LLMs, remain fundamental limitations. To overcome these challenges, several approaches implicitly or explicitly incorporating assistant distribution have recently been proposed. However, the past proposals of assistant distributions have been a fragmented approach without a systematic investigation of the interpolation path and the divergence. This paper proposes $α$-mixture assistant distribution, a novel generalized family of assistant distributions, and $α$-mixture distillation, coined AMiD, a unified framework for KD using the assistant distribution. The $α$-mixture assistant distribution provides a continuous extension of the assistant distribution by introducing a new distribution design variable $α$, which has been fixed in all previous approaches. Furthermore, AMiD generalizes the family of divergences used with the assistant distributions based on optimality, which has also been restricted in previous works. Through extensive experiments, we demonstrate that AMiD offers superior performance and training stability by leveraging a broader and theoretically grounded assistant distribution space.