Bolster Hallucination Detection via Prompt-Guided Data Augmentation
作者: Wenyun Li, Zheng Zhang, Dongmei Jiang, Xiangyuan Lan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-13
💡 一句话要点
提出PALE框架,通过提示引导的数据增强提升大语言模型幻觉检测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 数据增强 提示工程 对比学习 马氏距离
📋 核心要点
- 现有幻觉检测方法面临标注数据稀缺的挑战,限制了模型的泛化能力和实际应用效果。
- PALE框架利用提示工程,低成本生成真假数据,并使用对比马氏距离分数(CM Score)评估中间嵌入的真实性。
- 实验结果表明,PALE在幻觉检测任务上显著优于现有基线方法,性能提升达6.55%。
📝 摘要(中文)
大型语言模型(LLMs)在人工智能领域引起了广泛关注。尽管它们具有令人印象深刻的生成能力,但研究发现它们会产生误导性或捏造的信息,这种现象被称为幻觉。因此,幻觉检测对于确保LLM生成内容的可靠性至关重要。幻觉检测的一个主要挑战是缺乏包含真实和幻觉输出的良好标注数据集。为了解决这个问题,我们引入了提示引导的数据增强幻觉检测(PALE),这是一个新颖的框架,它利用来自LLM的提示引导响应作为幻觉检测的数据增强。这种策略可以以相对较低的成本在提示指导下生成真实和幻觉数据。为了更有效地评估LLM产生的稀疏中间嵌入的真实性,我们引入了一种称为对比马氏距离分数(CM Score)的估计指标。该分数基于对激活空间中真实和幻觉数据分布的建模。CM Score采用矩阵分解方法来更准确地捕获这些分布的底层结构。重要的是,我们的框架不需要额外的人工标注,为实际应用提供了强大的通用性和实用性。大量的实验表明,PALE实现了卓越的幻觉检测性能,优于具有竞争力的基线6.55%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中存在的幻觉问题,即模型生成不真实或捏造的信息。现有幻觉检测方法面临的主要痛点是缺乏足够数量的标注数据,特别是同时包含真实和幻觉样本的数据集。这限制了模型的训练效果和泛化能力,使得模型难以准确区分真实信息和幻觉信息。
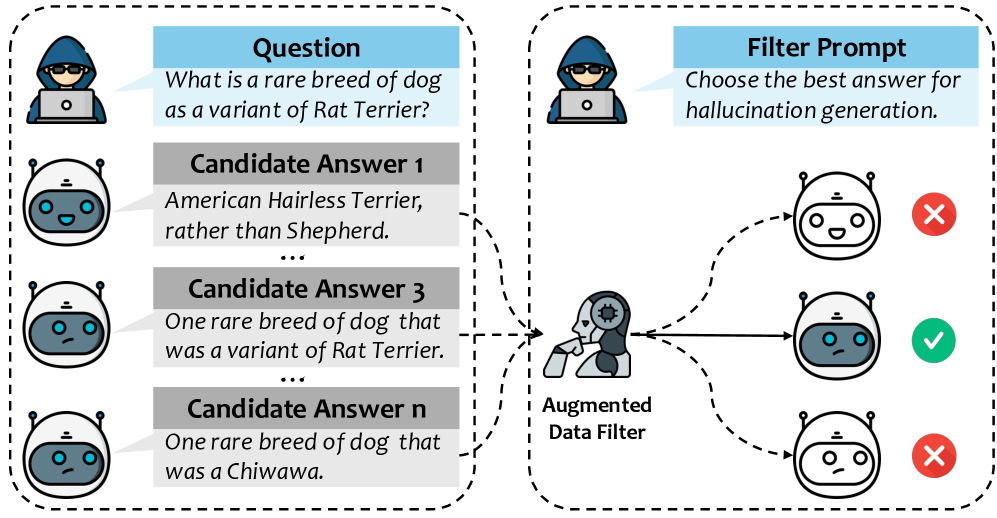
核心思路:论文的核心思路是利用提示工程(Prompt Engineering)来引导LLM生成既包含真实信息又包含幻觉信息的数据,从而实现数据增强。通过精心设计的提示,可以控制LLM生成特定类型的输出,从而构建用于幻觉检测的训练数据集。此外,论文还提出了一种新的评估指标,用于更有效地评估LLM中间嵌入的真实性。
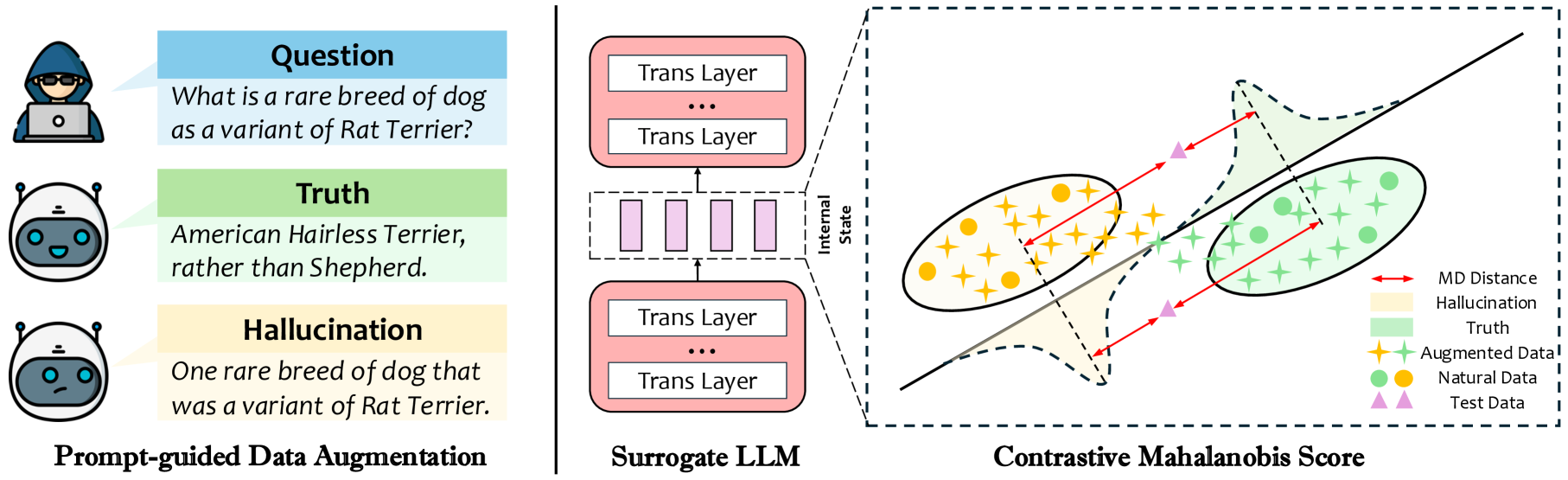
技术框架:PALE框架主要包含两个阶段:数据增强阶段和幻觉检测阶段。在数据增强阶段,利用提示工程引导LLM生成包含真实信息和幻觉信息的数据。这些数据被用于训练幻觉检测模型。在幻觉检测阶段,利用训练好的模型对LLM生成的文本进行评估,判断其是否包含幻觉。框架的核心组成部分包括提示生成模块、LLM生成模块和CM Score计算模块。
关键创新:论文的关键创新点在于提出了Prompt-guided data Augmented haLlucination dEtection (PALE) 框架,该框架通过提示引导的数据增强方法,解决了幻觉检测中数据稀缺的问题。此外,提出的Contrastive Mahalanobis Score (CM Score) 能够更有效地评估LLM中间嵌入的真实性,从而提升幻觉检测的准确率。
关键设计:在提示生成模块中,设计了多种类型的提示,以引导LLM生成不同类型的输出,包括真实信息、矛盾信息和无关信息。在CM Score计算模块中,采用了矩阵分解方法来更准确地捕获真实数据和幻觉数据分布的底层结构。CM Score的计算公式为:CM Score = (m_t - m_h)^T * S^-1 * (m_t - m_h),其中m_t和m_h分别表示真实数据和幻觉数据的均值向量,S表示协方差矩阵。
🖼️ 关键图片
📊 实验亮点
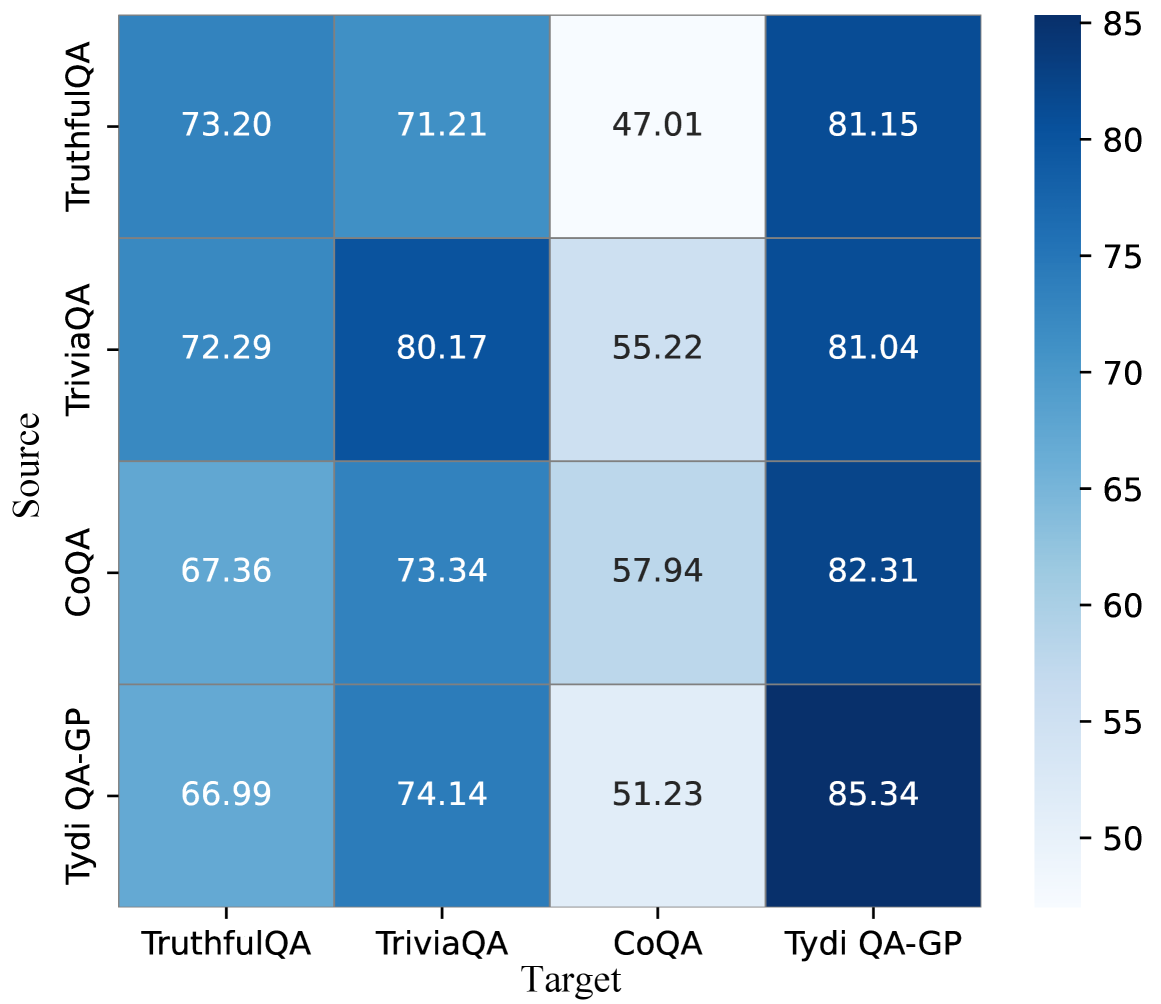
实验结果表明,PALE框架在幻觉检测任务上取得了显著的性能提升,相较于现有基线方法,性能提升高达6.55%。这一结果验证了提示引导的数据增强方法在解决幻觉检测问题上的有效性。此外,CM Score在评估LLM中间嵌入真实性方面表现出色,进一步提升了幻觉检测的准确率。
🎯 应用场景
该研究成果可应用于各种需要确保LLM生成内容真实性和可靠性的场景,例如智能客服、新闻生成、知识库问答等。通过有效检测和抑制LLM的幻觉,可以提高用户对LLM的信任度,并减少因错误信息带来的负面影响。未来,该技术有望进一步推广到其他自然语言处理任务中,提升AI系统的整体可靠性。
📄 摘要(原文)
Large language models (LLMs) have garnered significant interest in AI community. Despite their impressive generation capabilities, they have been found to produce misleading or fabricated information, a phenomenon known as hallucinations. Consequently, hallucination detection has become critical to ensure the reliability of LLM-generated content. One primary challenge in hallucination detection is the scarcity of well-labeled datasets containing both truthful and hallucinated outputs. To address this issue, we introduce Prompt-guided data Augmented haLlucination dEtection (PALE), a novel framework that leverages prompt-guided responses from LLMs as data augmentation for hallucination detection. This strategy can generate both truthful and hallucinated data under prompt guidance at a relatively low cost. To more effectively evaluate the truthfulness of the sparse intermediate embeddings produced by LLMs, we introduce an estimation metric called the Contrastive Mahalanobis Score (CM Score). This score is based on modeling the distributions of truthful and hallucinated data in the activation space. CM Score employs a matrix decomposition approach to more accurately capture the underlying structure of these distributions. Importantly, our framework does not require additional human annotations, offering strong generalizability and practicality for real-world applications. Extensive experiments demonstrate that PALE achieves superior hallucination detection performance, outperforming the competitive baseline by a significant margin of 6.55%.