Efficient Restarts in Non-Stationary Model-Free Reinforcement Learning
作者: Hiroshi Nonaka, Simon Ambrozak, Sofia R. Miskala-Dinc, Amedeo Ercole, Aviva Prins
分类: cs.LG
发布日期: 2025-10-13
备注: This paper contains 19 pages and 3 figures. To be presented at the 2nd Workshop on Aligning Reinforcement Learning Experimentalists and Theorists (ARLET 2025) at NeurIPS 2025
💡 一句话要点
针对非平稳强化学习,提出高效重启策略以提升动态后悔值
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 非平稳强化学习 重启策略 动态后悔值 自适应学习 部分重启 环境变化 无模型学习
📋 核心要点
- 现有RestartQ-UCB算法存在完全遗忘和计划重启的问题,导致在非平稳环境中学习效率低下。
- 论文提出部分、自适应和选择性重启策略,旨在保留有用信息并根据环境变化动态调整重启时机。
- 实验表明,新方法在多个环境中显著降低了动态后悔值,性能优于RestartQ-UCB算法。
📝 摘要(中文)
本文针对非平稳无模型强化学习,提出了三种高效的重启范式。我们指出了Mao et al. (2022)的RestartQ-UCB算法在重启设计上的两个核心问题:(1) 完全遗忘,即在重启后丢失所有关于环境的信息;(2) 计划重启,即重启仅在预定义的时间发生,而忽略了策略与当前环境动态的不兼容性。我们引入了三种方法,分别称为部分重启、自适应重启和选择性重启,以改进RestartQ-UCB和RANDOMIZEDQ (Wang et al., 2025)算法。实验结果表明,在多个不同的环境中,我们的方法实现了接近最优的经验性能,相对于RestartQ-UCB,动态后悔值最多降低了91%。
🔬 方法详解
问题定义:论文旨在解决非平稳无模型强化学习中,由于环境动态变化导致的策略失效问题。现有RestartQ-UCB算法采用完全遗忘和预设重启时间的方式,无法有效适应环境变化,导致学习效率低下,动态后悔值较高。其痛点在于无法在重启时保留有用的历史信息,并且重启时机与环境变化脱节。
核心思路:论文的核心思路是改进重启策略,使其能够保留部分有用的历史信息,并根据环境变化自适应地调整重启时机。通过部分重启保留重要信息,自适应重启根据环境变化触发,选择性重启则根据策略表现决定是否重启,从而更有效地适应非平稳环境。
技术框架:整体框架基于现有的RestartQ-UCB和RANDOMIZEDQ算法,主要改进在于重启模块。具体来说,论文提出了三种重启策略: 1. 部分重启:保留部分Q值或策略参数,避免完全遗忘。 2. 自适应重启:根据环境变化指标(如预测误差)动态触发重启。 3. 选择性重启:根据策略性能(如奖励变化)决定是否重启。 这些策略可以单独或组合使用,以适应不同的非平稳环境。
关键创新:最重要的技术创新点在于提出了三种不同的重启策略,这些策略能够克服现有重启算法的局限性,更有效地适应非平稳环境。与完全遗忘的重启策略相比,部分重启能够保留有用的历史信息;与预设重启时间相比,自适应和选择性重启能够根据环境变化动态调整重启时机。
关键设计:具体的技术细节包括: 1. 部分重启:可以通过保留top-k的Q值,或者使用正则化方法约束新旧Q值之间的差异来实现。 2. 自适应重启:可以使用预测误差的滑动平均值作为环境变化指标,当该指标超过阈值时触发重启。 3. 选择性重启:可以使用奖励的滑动平均值作为策略性能指标,当该指标下降到一定程度时触发重启。 这些策略的具体参数(如k值、阈值等)需要根据具体环境进行调整。
🖼️ 关键图片

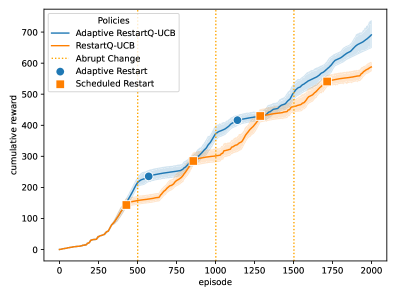
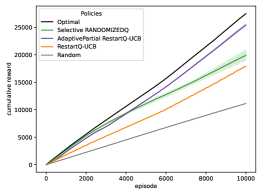
📊 实验亮点
实验结果表明,提出的部分重启、自适应重启和选择性重启策略在多个非平稳环境中均取得了显著的性能提升。相对于RestartQ-UCB算法,动态后悔值最多降低了91%。此外,实验还验证了不同重启策略的组合使用可以进一步提高性能,表明了该方法的灵活性和适应性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、金融交易等需要在非平稳环境中进行决策的领域。例如,在机器人导航中,环境可能因天气、光照等因素发生变化,采用自适应重启策略可以使机器人更快地适应新的环境,提高导航效率。在金融交易中,市场环境瞬息万变,采用选择性重启策略可以帮助交易系统及时调整策略,降低交易风险。
📄 摘要(原文)
In this work, we propose three efficient restart paradigms for model-free non-stationary reinforcement learning (RL). We identify two core issues with the restart design of Mao et al. (2022)'s RestartQ-UCB algorithm: (1) complete forgetting, where all the information learned about an environment is lost after a restart, and (2) scheduled restarts, in which restarts occur only at predefined timings, regardless of the incompatibility of the policy with the current environment dynamics. We introduce three approaches, which we call partial, adaptive, and selective restarts to modify the algorithms RestartQ-UCB and RANDOMIZEDQ (Wang et al., 2025). We find near-optimal empirical performance in multiple different environments, decreasing dynamic regret by up to $91$% relative to RestartQ-UCB.