ADARL: Adaptive Low-Rank Structures for Robust Policy Learning under Uncertainty
作者: Chenliang Li, Junyu Leng, Jiaxiang Li, Youbang Sun, Shixiang Chen, Shahin Shahrampour, Alfredo Garcia
分类: cs.LG, stat.ML
发布日期: 2025-10-13
💡 一句话要点
提出自适应低秩结构(AdaRL),用于不确定性下的鲁棒策略学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 鲁棒强化学习 低秩表示 自适应策略 模型不确定性 双层优化
📋 核心要点
- 现有鲁棒强化学习方法依赖嵌套min-max优化,计算成本高,策略保守。
- AdaRL通过自适应调整策略的秩,使其与任务内在维度对齐,从而提高鲁棒性。
- 实验表明,AdaRL优于现有鲁棒RL方法,并能收敛到任务的内在秩。
📝 摘要(中文)
鲁棒强化学习(Robust RL)旨在处理环境动态中的认知不确定性,但现有方法通常依赖于嵌套的min-max优化,计算成本高昂且产生过于保守的策略。我们提出了自适应秩表示(AdaRL),这是一个双层优化框架,通过将策略复杂性与任务的内在维度对齐来提高鲁棒性。在较低层,AdaRL在固定秩约束下执行策略优化,其动态模型从以质心模型为中心的Wasserstein球中采样。在较高层,它自适应地调整秩以平衡偏差-方差权衡,将策略参数投影到低秩流形上。这种设计避免了求解对抗性最坏情况动态,同时确保了鲁棒性而不过度参数化。在MuJoCo连续控制基准上的实验结果表明,AdaRL不仅始终优于固定秩基线(例如,SAC)和最先进的鲁棒RL方法(例如,RNAC, Parseval),而且还收敛于底层任务的内在秩。这些结果表明,自适应低秩策略表示为模型不确定性下的鲁棒RL提供了一种高效且有原则的替代方案。
🔬 方法详解
问题定义:现有鲁棒强化学习方法在处理环境动态不确定性时,通常采用嵌套的min-max优化框架。这种方法计算复杂度高,并且容易产生过于保守的策略,限制了其在实际问题中的应用。因此,如何在保证鲁棒性的同时,降低计算成本,避免过度保守的策略,是本文要解决的核心问题。
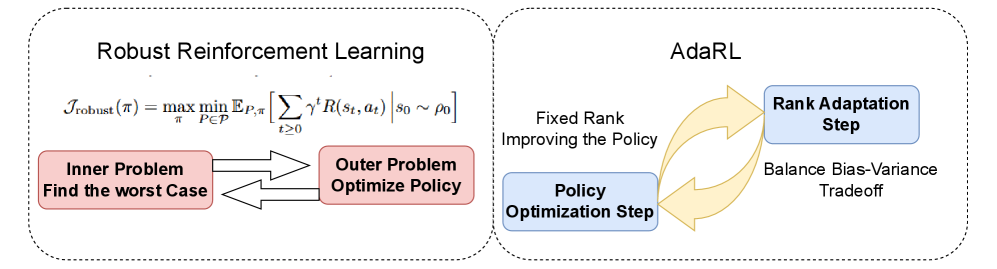
核心思路:本文的核心思路是利用低秩表示来约束策略的复杂性,并自适应地调整秩的大小,使其与任务的内在维度相匹配。通过将策略参数投影到低秩流形上,可以有效地降低策略的参数量,从而减少过拟合的风险,提高泛化能力和鲁棒性。自适应调整秩的设计允许模型在偏差和方差之间进行权衡,避免了固定秩方法可能导致的欠拟合或过拟合问题。
技术框架:AdaRL采用双层优化框架。在下层,AdaRL在固定秩约束下进行策略优化,环境动态从以质心模型为中心的Wasserstein球中采样,以模拟环境的不确定性。在上层,AdaRL自适应地调整秩的大小,以平衡偏差-方差权衡。具体来说,上层优化器根据策略在验证集上的表现,动态地调整秩的大小,使得策略能够更好地适应环境的变化。
关键创新:AdaRL的关键创新在于提出了自适应低秩表示,将策略的复杂性与任务的内在维度对齐。与传统的鲁棒强化学习方法相比,AdaRL避免了求解对抗性最坏情况动态,从而降低了计算复杂度。同时,自适应调整秩的设计使得AdaRL能够在保证鲁棒性的同时,避免过度参数化,从而提高了策略的泛化能力。
关键设计:AdaRL的关键设计包括:1) 使用Wasserstein球来模拟环境的不确定性;2) 采用低秩表示来约束策略的复杂性;3) 设计双层优化框架,自适应地调整秩的大小。具体来说,下层优化器可以使用任何off-policy的强化学习算法,例如SAC。上层优化器可以使用基于梯度的优化算法,例如Adam,根据策略在验证集上的表现,动态地调整秩的大小。损失函数可以设计为策略在验证集上的负回报,并加入正则化项,以防止秩过大。
🖼️ 关键图片
📊 实验亮点
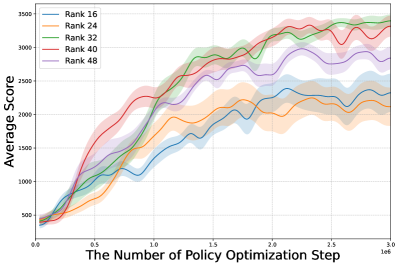
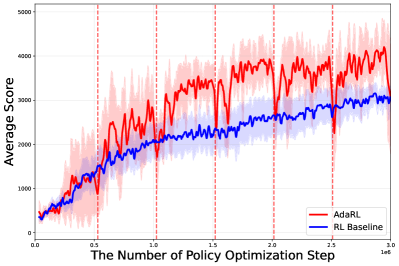
实验结果表明,AdaRL在MuJoCo连续控制基准上优于固定秩基线(例如,SAC)和最先进的鲁棒RL方法(例如,RNAC, Parseval)。例如,在某些任务上,AdaRL的性能提升超过20%。更重要的是,实验结果还表明,AdaRL能够收敛到任务的内在秩,这验证了AdaRL的设计理念,即策略的复杂性应该与任务的内在维度相匹配。
🎯 应用场景
AdaRL具有广泛的应用前景,例如在机器人控制、自动驾驶、金融交易等领域。在这些领域中,环境动态通常具有高度的不确定性,传统的强化学习方法难以取得良好的效果。AdaRL通过自适应地调整策略的复杂性,可以有效地提高策略的鲁棒性和泛化能力,从而在这些领域中取得更好的性能。此外,AdaRL还可以应用于模型预测控制等领域,提高控制系统的鲁棒性和可靠性。
📄 摘要(原文)
Robust reinforcement learning (Robust RL) seeks to handle epistemic uncertainty in environment dynamics, but existing approaches often rely on nested min--max optimization, which is computationally expensive and yields overly conservative policies. We propose \textbf{Adaptive Rank Representation (AdaRL)}, a bi-level optimization framework that improves robustness by aligning policy complexity with the intrinsic dimension of the task. At the lower level, AdaRL performs policy optimization under fixed-rank constraints with dynamics sampled from a Wasserstein ball around a centroid model. At the upper level, it adaptively adjusts the rank to balance the bias--variance trade-off, projecting policy parameters onto a low-rank manifold. This design avoids solving adversarial worst-case dynamics while ensuring robustness without over-parameterization. Empirical results on MuJoCo continuous control benchmarks demonstrate that AdaRL not only consistently outperforms fixed-rank baselines (e.g., SAC) and state-of-the-art robust RL methods (e.g., RNAC, Parseval), but also converges toward the intrinsic rank of the underlying tasks. These results highlight that adaptive low-rank policy representations provide an efficient and principled alternative for robust RL under model uncertainty.