Z0-Inf: Zeroth Order Approximation for Data Influence
作者: Narine Kokhlikyan, Kamalika Chaudhuri, Saeed Mahloujifar
分类: cs.LG
发布日期: 2025-10-13
💡 一句话要点
提出Z0-Inf,一种高效的零阶近似方法用于数据影响评估,适用于大型模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据影响评估 零阶近似 模型调试 数据选择 大型语言模型
📋 核心要点
- 现有数据影响评估方法在大模型上精度低或计算成本高昂,限制了其应用。
- Z0-Inf仅依赖损失值和模型检查点,无需梯度计算,降低了计算复杂度。
- 实验表明,Z0-Inf在自影响估计上精度更高,训练-测试影响估计上精度可比或更优。
📝 摘要(中文)
理解训练数据中的个体样本如何影响模型的预测行为,对于分析和改进现代机器学习系统至关重要。评估这种影响能够支持数据选择和模型调试等关键应用;特别是自影响,它量化了训练点对自身的影响,已广泛应用于数据质量评估和异常值检测。然而,由于精度低或计算成本过高,现有的数据影响测量方法对于大型模型通常不实用:大多数方法要么提供较差的近似,要么依赖于梯度和逆Hessian计算,这些计算仍然难以扩展。本文提出了一种高效的零阶近似方法,用于估计训练数据的影响,它仅需先前方法所需的时间和内存占用的一小部分。值得注意的是,我们的方法仅依赖于训练和测试数据上中间检查点的损失值以及检查点本身,使其具有广泛的适用性,即使在感兴趣的损失函数不可微时也是如此。除了计算效率之外,我们的方法在估计自影响方面实现了卓越的准确性,并在估计微调大型语言模型的训练-测试影响方面实现了可比或更高的准确性,从而能够对训练数据如何塑造模型行为进行可扩展和实际的分析。
🔬 方法详解
问题定义:论文旨在解决大规模模型中数据影响评估的难题。现有方法,如基于梯度或Hessian的方法,计算复杂度高,难以扩展到大型模型。此外,某些损失函数不可微,使得基于梯度的方法无法应用。因此,需要一种高效且通用的数据影响评估方法。
核心思路:论文的核心思路是使用零阶近似来估计数据影响。零阶方法不依赖于梯度信息,而是直接使用损失函数的值。通过在训练过程中保存模型的多个检查点,并计算这些检查点在训练和测试数据上的损失,可以近似估计每个训练样本对模型预测的影响。这种方法避免了复杂的梯度计算和逆Hessian计算,从而大大降低了计算复杂度。
技术框架:Z0-Inf的技术框架主要包括以下几个步骤:1. 在模型训练过程中,定期保存模型的检查点。2. 对于每个训练样本和测试样本,计算每个检查点在该样本上的损失值。3. 使用这些损失值和检查点信息,通过零阶近似方法估计每个训练样本对测试样本的影响。4. 可以进一步计算自影响,即训练样本对自身的影响。
关键创新:Z0-Inf的关键创新在于使用零阶近似来估计数据影响,避免了梯度计算和逆Hessian计算。这使得该方法能够应用于大型模型和不可微损失函数,具有更广泛的适用性。此外,Z0-Inf只需要保存模型的检查点和计算损失值,内存占用也大大降低。
关键设计:Z0-Inf的关键设计包括:1. 检查点保存频率:需要根据计算资源和精度要求进行权衡。保存频率越高,精度越高,但计算成本也越高。2. 零阶近似的具体公式:论文中使用了特定的零阶近似公式来估计数据影响,具体公式细节未知。3. 损失函数的选择:Z0-Inf可以与任何损失函数一起使用,包括不可微的损失函数。
🖼️ 关键图片
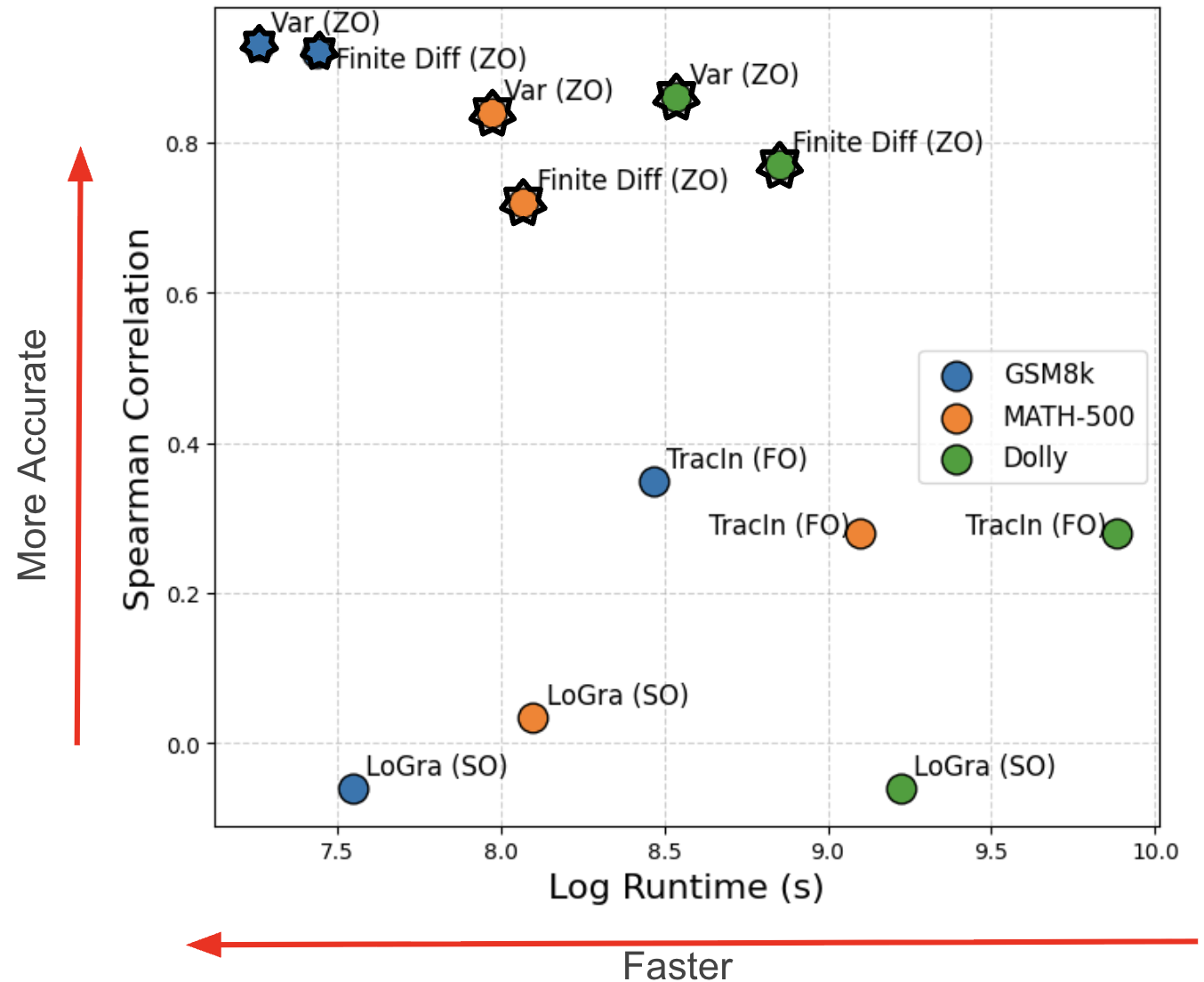
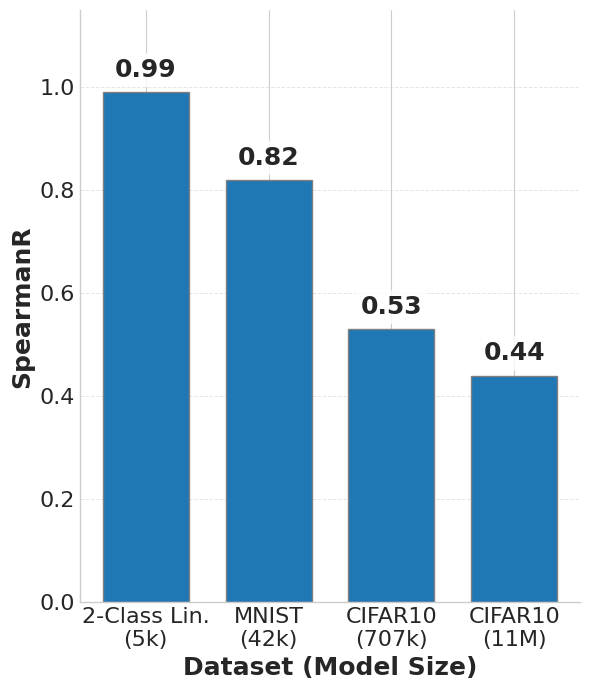
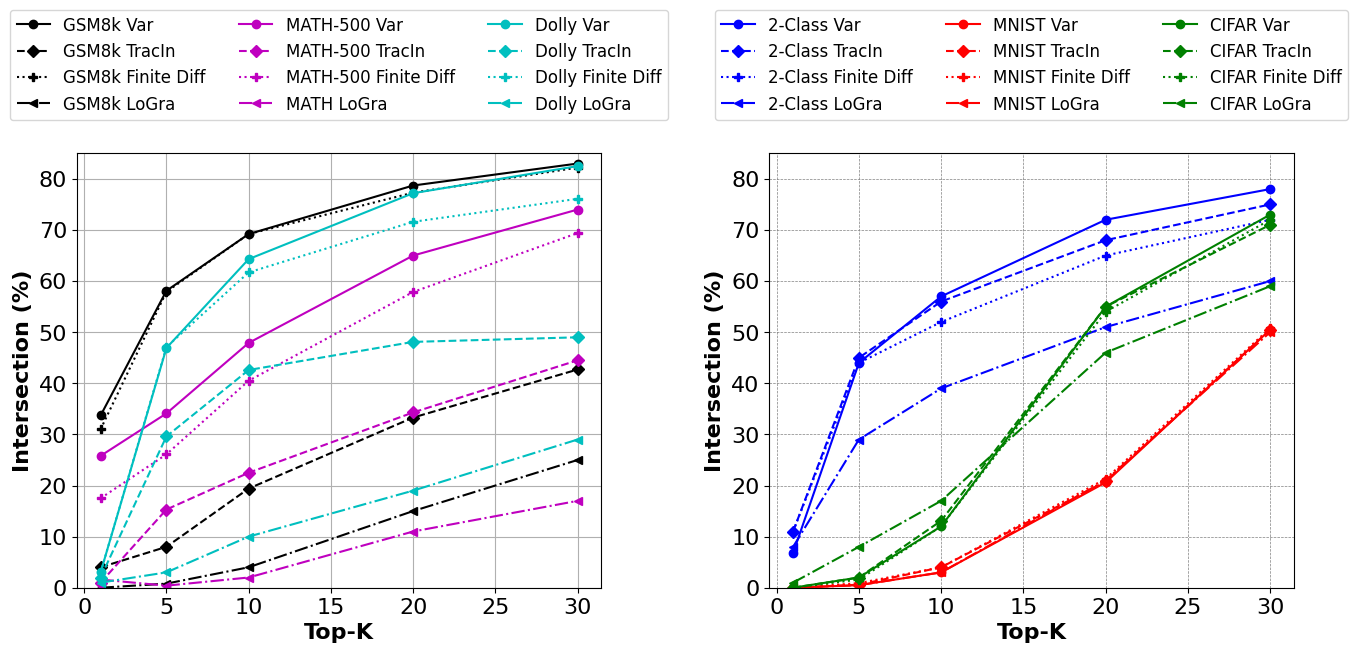
📊 实验亮点
Z0-Inf在估计自影响方面实现了比现有方法更高的准确性,并在估计训练-测试影响方面实现了可比或更高的准确性。该方法显著降低了计算时间和内存占用,使得对大型语言模型进行数据影响分析成为可能。具体性能数据未知,但论文强调了其在计算效率上的优势。
🎯 应用场景
Z0-Inf可应用于数据选择、模型调试、数据质量评估和异常值检测等领域。通过分析训练数据的影响,可以识别对模型性能贡献最大的数据,从而进行数据选择和清洗。此外,还可以通过分析自影响来检测异常值和错误标注的数据,提高数据质量。该方法尤其适用于大型语言模型等计算成本高的场景。
📄 摘要(原文)
A critical aspect of analyzing and improving modern machine learning systems lies in understanding how individual training examples influence a model's predictive behavior. Estimating this influence enables critical applications, including data selection and model debugging; in particular, self-influence, which quantifies the influence of a training point on itself, has found many uses in data quality assessment and outlier detection. Existing methods for measuring data influence, however, are often impractical for large models due to low accuracy or prohibitive computational costs: most approaches either provide poor approximations or rely on gradients and inverse-Hessian computations that remain challenging to scale. In this work, we introduce a highly efficient zeroth-order approximation for estimating the influence of training data that requires only a fraction of the time and memory footprint of prior methods. Notably, our method relies solely on loss values of intermediate checkpoints on the training and test data, along with the checkpoints themselves, making it broadly applicable even when the loss function of interest is non-differentiable. Beyond its computational efficiency, our approach achieves superior accuracy in estimating self-influence and comparable or improved accuracy in estimating train-test influence for fine-tuned large language models, enabling scalable and practical analysis of how training data shapes model behavior.