QeRL: Beyond Efficiency -- Quantization-enhanced Reinforcement Learning for LLMs
作者: Wei Huang, Yi Ge, Shuai Yang, Yicheng Xiao, Huizi Mao, Yujun Lin, Hanrong Ye, Sifei Liu, Ka Chun Cheung, Hongxu Yin, Yao Lu, Xiaojuan Qi, Song Han, Yukang Chen
分类: cs.LG, cs.CL, cs.CV
发布日期: 2025-10-13
备注: Code is available at https://github.com/NVlabs/QeRL
💡 一句话要点
QeRL:面向LLM的量化增强强化学习框架,提升效率并增强探索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 量化 低秩适应 策略探索 自适应量化噪声 模型优化
📋 核心要点
- 现有LLM强化学习训练资源消耗大,需要大量GPU内存和长时间rollout,限制了其应用。
- QeRL结合NVFP4量化和LoRA,降低内存开销并加速rollout,同时利用量化噪声增强探索。
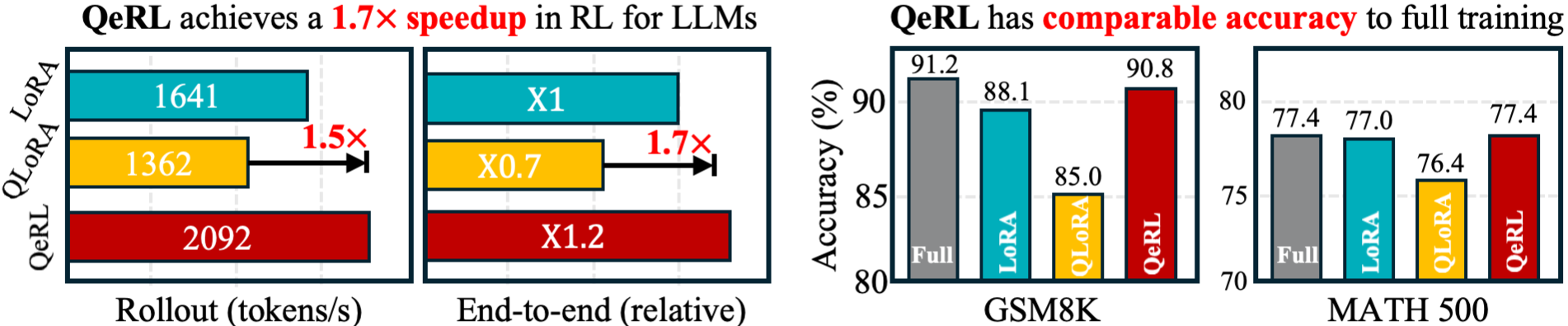
- 实验表明,QeRL加速rollout,首次实现32B LLM在单H100 GPU上训练,并在数学基准测试中表现优异。
📝 摘要(中文)
本文提出了QeRL,一个面向大型语言模型(LLMs)的量化增强强化学习框架。强化学习对于提升LLMs的推理能力至关重要,但其资源消耗巨大,需要大量的GPU内存和较长的rollout时间。QeRL通过结合NVFP4量化和低秩适应(LoRA)来解决这些问题,加速强化学习的rollout阶段并降低内存开销。研究发现,量化噪声增加了策略熵,从而增强了探索能力,使得在强化学习过程中能够发现更好的策略。为了进一步优化探索,QeRL引入了一种自适应量化噪声(AQN)机制,该机制在训练过程中动态调整噪声。实验表明,QeRL在rollout阶段提供了超过1.5倍的加速。此外,该框架首次实现了在单个H100 80GB GPU上对32B LLM进行强化学习训练,同时提供了整体的强化学习训练加速。在7B模型上,QeRL在GSM8K(90.8%)和MATH 500(77.4%)等数学基准测试中,实现了比16位LoRA和QLoRA更快的奖励增长和更高的最终准确率,同时与全参数微调的性能相匹配。这些结果表明,QeRL是LLMs中强化学习训练的一种高效且有效的框架。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)强化学习训练过程中资源消耗过高的问题,具体表现为GPU内存需求大和rollout阶段耗时过长。现有方法,如传统的强化学习和基于LoRA的强化学习,在处理大型LLM时面临着效率瓶颈,难以在有限的硬件资源上进行有效的训练。
核心思路:论文的核心思路是利用量化技术(NVFP4)和低秩适应(LoRA)的结合,在降低内存占用和加速计算的同时,通过引入量化噪声来增强策略探索。这种方法旨在在效率和性能之间找到平衡,使得大型LLM能够在资源受限的环境下进行有效的强化学习训练。
技术框架:QeRL框架主要包含以下几个阶段:首先,使用NVFP4量化LLM参数,显著降低内存占用。其次,采用LoRA技术,仅训练少量参数,进一步提高训练效率。在rollout阶段,利用量化后的模型进行策略评估和样本生成。最后,通过强化学习算法(如PPO)更新LoRA参数,优化LLM的策略。自适应量化噪声(AQN)机制在训练过程中动态调整量化噪声的强度,以平衡探索和利用。
关键创新:QeRL的关键创新在于将量化技术与强化学习相结合,并利用量化噪声来增强策略探索。与传统的量化方法不同,QeRL不仅关注量化带来的效率提升,还主动利用量化噪声来促进策略的多样性,从而避免陷入局部最优解。此外,AQN机制的引入使得量化噪声能够根据训练状态进行自适应调整,进一步优化了探索过程。
关键设计:QeRL的关键设计包括:1) 使用NVFP4量化,在保证模型性能的同时显著降低内存占用;2) 采用LoRA进行参数高效微调,减少计算量;3) 引入自适应量化噪声(AQN)机制,根据训练进度动态调整量化噪声的强度,具体实现方式未知;4) 使用标准的强化学习算法(如PPO)进行策略优化,损失函数和网络结构细节未知。
🖼️ 关键图片


📊 实验亮点
QeRL在rollout阶段实现了超过1.5倍的加速,并且首次在单个H100 80GB GPU上成功训练了一个32B的LLM。在7B模型上,QeRL在GSM8K上达到了90.8%的准确率,在MATH 500上达到了77.4%的准确率,与全参数微调的性能相匹配,同时优于16位LoRA和QLoRA。
🎯 应用场景
QeRL框架具有广泛的应用前景,可用于训练各种需要复杂推理能力的大型语言模型,例如对话系统、智能助手、代码生成模型等。该框架降低了训练LLM的硬件门槛,使得更多研究者和开发者能够在资源有限的环境下进行LLM的强化学习训练。此外,QeRL的探索增强机制也有助于发现更优的策略,提升LLM在各种任务中的性能。
📄 摘要(原文)
We propose QeRL, a Quantization-enhanced Reinforcement Learning framework for large language models (LLMs). While RL is essential for LLMs' reasoning capabilities, it is resource-intensive, requiring substantial GPU memory and long rollout durations. QeRL addresses these issues by combining NVFP4 quantization with Low-Rank Adaptation (LoRA), accelerating rollout phase of RL while reducing memory overhead. Beyond efficiency, our findings show that quantization noise increases policy entropy, enhancing exploration, and enabling the discovery of better strategies during RL. To further optimize exploration, QeRL introduces an Adaptive Quantization Noise (AQN) mechanism, which dynamically adjusts noise during training. Experiments demonstrate that QeRL delivers over 1.5 times speedup in the rollout phase. Moreover, this is the first framework to enable RL training of a 32B LLM on a single H100 80GB GPU, while delivering overall speedups for RL training. It also achieves faster reward growth and higher final accuracy than 16-bit LoRA and QLoRA, while matching the performance of full-parameter fine-tuning on mathematical benchmarks such as GSM8K (90.8%) and MATH 500 (77.4%) in the 7B model. These results establish QeRL as an efficient and effective framework for RL training in LLMs.