Offline Reinforcement Learning with Generative Trajectory Policies
作者: Xinsong Feng, Leshu Tang, Chenan Wang, Haipeng Chen
分类: cs.LG, cs.AI
发布日期: 2025-10-13
备注: Preprint. Under review at ICLR 2026
💡 一句话要点
提出生成轨迹策略(GTP),提升离线强化学习中生成模型的性能与效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 生成模型 轨迹策略 常微分方程 D4RL基准
📋 核心要点
- 现有离线强化学习中生成模型策略存在速度与性能的权衡问题,扩散模型慢但性能好,一致性模型快但性能差。
- 论文提出生成轨迹策略(GTP),将多种生成模型统一到常微分方程(ODE)框架下,学习整个解映射。
- 实验表明,GTP在D4RL基准测试中显著优于现有生成策略,并在AntMaze等困难任务上取得优异成绩。
📝 摘要(中文)
生成模型已成为离线强化学习(RL)中一类强大的策略,能够捕捉复杂的多模态行为。然而,现有方法面临着严峻的权衡:像扩散策略这样缓慢的迭代模型计算成本高昂,而像一致性策略这样快速的单步模型通常性能下降。本文证明了弥合这一差距是可能的。我们认为,超越个体方法局限性的关键在于一个统一的视角,即将现代生成模型(包括扩散模型、Flow Matching和一致性模型)视为学习由常微分方程(ODE)控制的连续时间生成轨迹的特定实例。这种原则性的基础为RL中的生成策略提供了一个更清晰的设计空间,并允许我们提出生成轨迹策略(GTP),这是一种新的、更通用的策略范式,可以学习底层ODE的整个解映射。为了使这种范式在离线RL中实用,我们进一步引入了两个关键的、具有理论基础的调整。实验结果表明,GTP在D4RL基准测试中实现了最先进的性能——它显著优于之前的生成策略,在几个臭名昭著的AntMaze任务中取得了完美的成绩。
🔬 方法详解
问题定义:现有离线强化学习方法,特别是基于生成模型的策略,在计算效率和性能之间存在权衡。扩散模型能够捕捉复杂的多模态行为,但由于其迭代特性,计算成本很高。另一方面,一致性模型等单步生成模型虽然速度快,但性能往往不如扩散模型。因此,需要一种既能保持高性能,又能提高计算效率的生成策略。
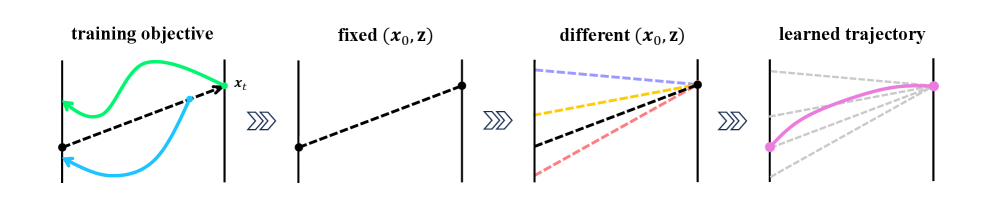
核心思路:论文的核心思路是将各种生成模型(如扩散模型、Flow Matching和一致性模型)统一到一个连续时间框架下,即常微分方程(ODE)。通过学习ODE的整个解映射,可以更全面地理解和控制生成过程,从而设计出更有效的生成策略。这种统一视角允许利用不同生成模型的优点,同时避免其缺点。
技术框架:GTP(Generative Trajectory Policies)的整体框架包括以下几个主要阶段:1) 将离线数据集用于训练一个生成模型,该模型学习一个由ODE控制的连续时间轨迹生成过程。2) 通过学习ODE的整个解映射,GTP能够预测给定初始状态的未来轨迹。3) 利用学习到的轨迹生成策略,在离线数据上进行策略评估和改进。4) 为了提高离线RL的实用性,论文还引入了两个关键的理论调整,具体细节未知。
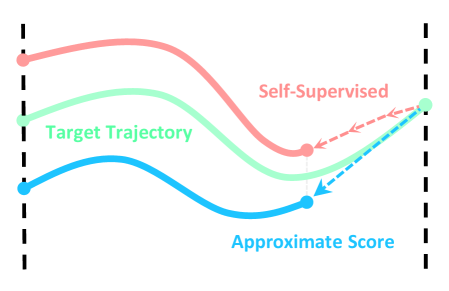
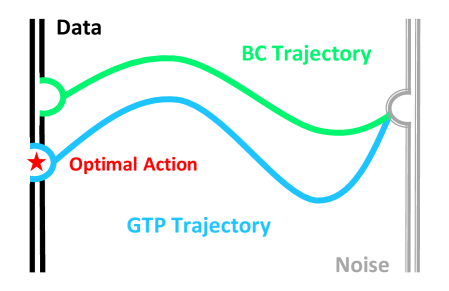
关键创新:论文的关键创新在于提出了一个统一的生成策略框架,将多种生成模型视为ODE的特定实例。与现有方法相比,GTP不是简单地使用现成的生成模型,而是学习整个轨迹生成过程的解映射,从而能够更灵活地控制生成策略的行为。这种方法能够更好地平衡计算效率和性能,并为离线RL中的生成策略设计提供了一个更清晰的设计空间。
关键设计:论文中关于关键设计的具体细节描述较少,主要强调了学习ODE的整个解映射。关于具体的参数设置、损失函数、网络结构等技术细节,摘要中没有明确说明,具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
GTP在D4RL基准测试中取得了最先进的性能,显著优于之前的生成策略。特别是在AntMaze等困难任务上,GTP取得了完美的成绩,表明其具有强大的学习复杂行为的能力。具体的性能提升幅度以及对比的基线模型在摘要中没有详细说明,具体数据未知。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。通过离线数据学习高效的生成策略,可以降低试错成本,加速智能体的训练过程。例如,在机器人控制中,可以利用历史数据训练GTP,使机器人能够更好地适应复杂环境,完成各种任务。此外,该方法还可以用于生成逼真的游戏场景和角色行为,提升游戏体验。
📄 摘要(原文)
Generative models have emerged as a powerful class of policies for offline reinforcement learning (RL) due to their ability to capture complex, multi-modal behaviors. However, existing methods face a stark trade-off: slow, iterative models like diffusion policies are computationally expensive, while fast, single-step models like consistency policies often suffer from degraded performance. In this paper, we demonstrate that it is possible to bridge this gap. The key to moving beyond the limitations of individual methods, we argue, lies in a unifying perspective that views modern generative models, including diffusion, flow matching, and consistency models, as specific instances of learning a continuous-time generative trajectory governed by an Ordinary Differential Equation (ODE). This principled foundation provides a clearer design space for generative policies in RL and allows us to propose Generative Trajectory Policies (GTPs), a new and more general policy paradigm that learns the entire solution map of the underlying ODE. To make this paradigm practical for offline RL, we further introduce two key theoretically principled adaptations. Empirical results demonstrate that GTP achieves state-of-the-art performance on D4RL benchmarks - it significantly outperforms prior generative policies, achieving perfect scores on several notoriously hard AntMaze tasks.