ReLook: Vision-Grounded RL with a Multimodal LLM Critic for Agentic Web Coding
作者: Yuhang Li, Chenchen Zhang, Ruilin Lv, Ao Liu, Ken Deng, Yuanxing Zhang, Jiaheng Liu, Wiggin Zhou, Bo Zhou
分类: cs.LG, cs.CL
发布日期: 2025-10-13
💡 一句话要点
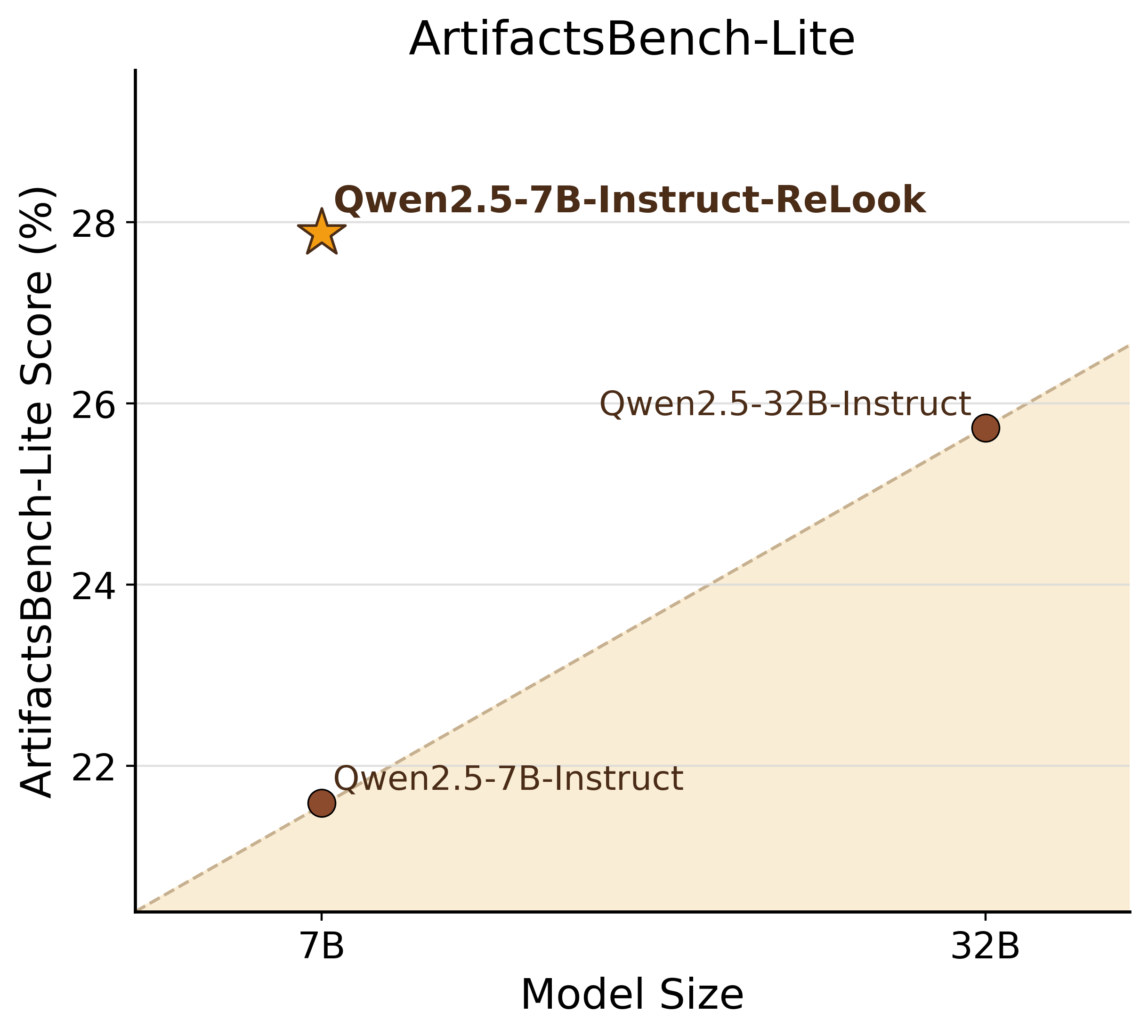
ReLook:利用多模态LLM进行视觉引导的强化学习,用于Agentic Web Coding
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 强化学习 视觉引导 前端代码生成 Agentic Web Coding
📋 核心要点
- 大型语言模型(LLM)擅长算法代码生成,但在前端开发方面表现不佳,因为前端的正确性取决于渲染的像素和交互。
- ReLook框架利用多模态LLM(MLLM)作为视觉评论员和反馈来源,通过强化学习训练agent,实现代码的生成、诊断和改进的闭环。
- 实验表明,ReLook在视觉引导的前端代码生成任务中,显著优于现有基线方法,验证了agent感知、视觉奖励和训练-推理解耦的有效性。
📝 摘要(中文)
本文提出ReLook,一个agentic的、视觉引导的强化学习框架,它使agent能够通过调用多模态LLM(MLLM)作为工具来闭环一个鲁棒的生成-诊断-改进循环。在训练期间,agent将MLLM用作视觉评论员(使用屏幕截图对代码进行评分)和可操作的、视觉引导的反馈来源;对无效渲染采用严格的零奖励规则,以确保可渲染性并防止奖励利用。为了防止行为崩溃,引入了强制优化,这是一种严格的接受规则,只允许改进的修订,从而产生单调更好的轨迹。在推理时,解耦评论员并运行轻量级的、无评论员的自编辑循环,使延迟与基本解码相当,同时保留大部分增益。在三个广泛使用的基准测试中,ReLook在视觉引导的前端代码生成方面始终优于强大的基线,突出了agent感知、视觉奖励和训练-推理解耦的优势。
🔬 方法详解
问题定义:现有的大型语言模型在算法代码生成方面表现出色,但在前端开发中面临挑战。前端代码的正确性依赖于渲染后的视觉效果和用户交互,而LLM难以直接评估这些因素。因此,如何使agent能够生成符合视觉要求的、可交互的前端代码是一个关键问题。现有方法缺乏有效的视觉反馈机制,容易产生无法渲染或用户体验差的代码。
核心思路:ReLook的核心思路是利用多模态LLM(MLLM)作为视觉评论员,为agent提供视觉反馈和指导。通过将屏幕截图作为输入,MLLM可以评估代码的渲染效果,并提供可操作的改进建议。此外,ReLook采用强化学习框架,通过视觉奖励来引导agent学习生成高质量的前端代码。
技术框架:ReLook框架包含以下主要模块:1) 代码生成器:负责生成前端代码;2) 渲染引擎:将生成的代码渲染成网页;3) 多模态LLM评论员:接收屏幕截图和代码,评估渲染效果并提供反馈;4) 强化学习agent:根据MLLM的反馈和奖励,调整代码生成策略。训练过程中,agent通过与环境交互,不断优化代码生成能力。推理阶段,采用轻量级的自编辑循环,在保证性能的同时,尽可能保留训练阶段的增益。
关键创新:ReLook的关键创新在于将多模态LLM引入到强化学习循环中,作为视觉评论员。这种方法使得agent能够获得更直接、更有效的视觉反馈,从而更好地学习生成符合视觉要求的前端代码。此外,ReLook还提出了强制优化策略,确保agent的行为单调改进,避免行为崩溃。训练-推理解耦的设计,保证了推理阶段的效率。
关键设计:ReLook采用严格的零奖励规则,对无效渲染的代码给予零奖励,防止agent通过生成无法渲染的代码来获取虚假奖励。强制优化策略只接受改进的修订,确保agent的行为单调改进。在推理阶段,解耦评论员,采用轻量级的自编辑循环,以降低延迟。具体参数设置和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
ReLook在三个广泛使用的基准测试中,始终优于强大的基线方法,证明了其在视觉引导的前端代码生成方面的有效性。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。但总体而言,实验结果突出了agent感知、视觉奖励和训练-推理解耦的优势。
🎯 应用场景
ReLook框架可应用于自动化前端开发、网页设计、用户界面生成等领域。它可以帮助开发者快速生成高质量的前端代码,提高开发效率,降低开发成本。未来,ReLook有望应用于更广泛的视觉引导的代码生成任务,例如游戏开发、虚拟现实等。
📄 摘要(原文)
While Large Language Models (LLMs) excel at algorithmic code generation, they struggle with front-end development, where correctness is judged on rendered pixels and interaction. We present ReLook, an agentic, vision-grounded reinforcement learning framework that empowers an agent to close a robust generate--diagnose--refine loop by invoking a multimodal LLM (MLLM) as a tool. During training, the agent uses the MLLM-in-the-loop both as a visual critic--scoring code with screenshots--and as a source of actionable, vision-grounded feedback; a strict zero-reward rule for invalid renders anchors renderability and prevents reward hacking. To prevent behavioral collapse, we introduce Forced Optimization, a strict acceptance rule that admits only improving revisions, yielding monotonically better trajectories. At inference, we decouple the critic and run a lightweight, critic-free self-edit cycle, keeping latency comparable to base decoding while retaining most of the gains. Across three widely used benchmarks, ReLook consistently outperforms strong baselines in vision-grounded front-end code generation, highlighting the benefits of agentic perception, visual rewards, and training-inference decoupling.