Leveraging LLMs for Semi-Automatic Corpus Filtration in Systematic Literature Reviews
作者: Lucas Joos, Daniel A. Keim, Maximilian T. Fischer
分类: cs.LG, cs.DL, cs.HC
发布日期: 2025-10-13
💡 一句话要点
利用大语言模型进行系统文献综述的半自动语料过滤
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 系统文献综述 大型语言模型 半自动过滤 人机协作 文本分类
📋 核心要点
- 系统文献综述耗时且易受人为偏差影响,传统关键词搜索返回大量无关文献。
- 提出基于LLM的半自动过滤流程,利用共识机制提高分类准确性,并提供交互式界面。
- 实验表明,该流程显著降低人工工作量,错误率低于人工标注,且开源模型即可满足需求。
📝 摘要(中文)
系统文献综述(SLR)对于分析研究领域的现状和指导未来研究方向至关重要。然而,为SLR检索和过滤文献语料库非常耗时,需要大量的人工工作,因为在数字图书馆中基于关键词的搜索通常会返回大量不相关的出版物。本文提出了一种利用多个大型语言模型(LLM)的流程,基于描述性提示对论文进行分类,并使用共识方案共同做出决定。整个过程由人工监督,并通过我们的开源可视化分析Web界面LLMSurver进行交互式控制,该界面支持对模型输出进行实时检查和修改。我们使用来自最近一项包含超过8,000篇候选论文的SLR的真实数据评估了我们的方法,对2024年中期和2025年秋季的最新开源和商业LLM进行了基准测试。结果表明,我们的流程显著减少了人工工作量,同时实现了比单个人工标注者更低的错误率。此外,现代开源模型足以胜任这项任务,使得该方法易于访问且具有成本效益。总的来说,我们的工作展示了负责任的人工智能协作如何加速和增强学术工作流程中的系统文献综述。
🔬 方法详解
问题定义:系统文献综述(SLR)是学术研究的重要组成部分,但其文献筛选过程高度依赖人工,耗时且容易出错。传统的关键词搜索方法会返回大量无关文献,增加了人工筛选的负担。现有方法缺乏高效、准确且可交互的工具来辅助文献筛选。
核心思路:利用大型语言模型(LLM)强大的文本理解和分类能力,设计一个半自动化的文献过滤流程。通过精心设计的提示(prompts),引导LLM对文献进行分类,并采用共识机制来提高分类的准确性和鲁棒性。同时,提供一个交互式界面,允许人工干预和修正模型输出,实现人机协同。
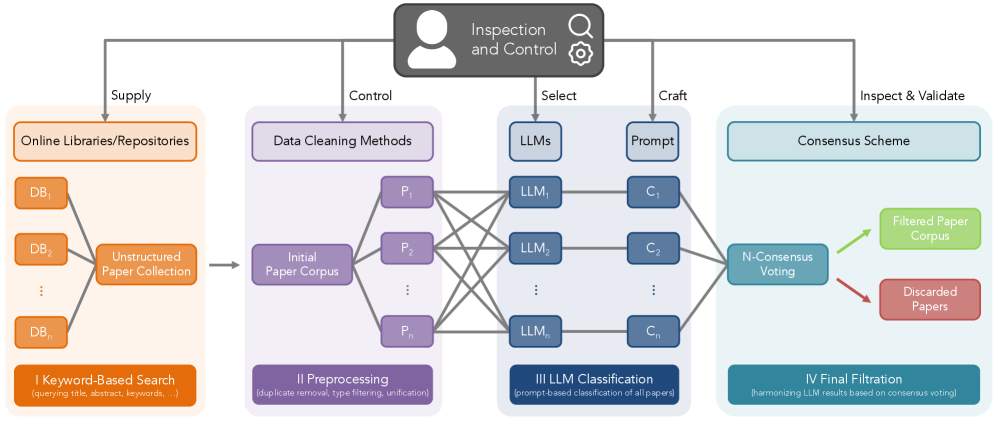
技术框架:该流程主要包含以下几个阶段:1) 文献检索:使用关键词在数字图书馆中检索候选文献。2) LLM分类:使用多个LLM,基于描述性提示对每篇文献进行相关性分类。3) 共识决策:采用共识方案,综合多个LLM的分类结果,做出最终决策。4) 人工监督:通过LLMSurver界面,人工检查和修改模型输出。5) 迭代优化:根据人工反馈,不断优化提示和模型参数。
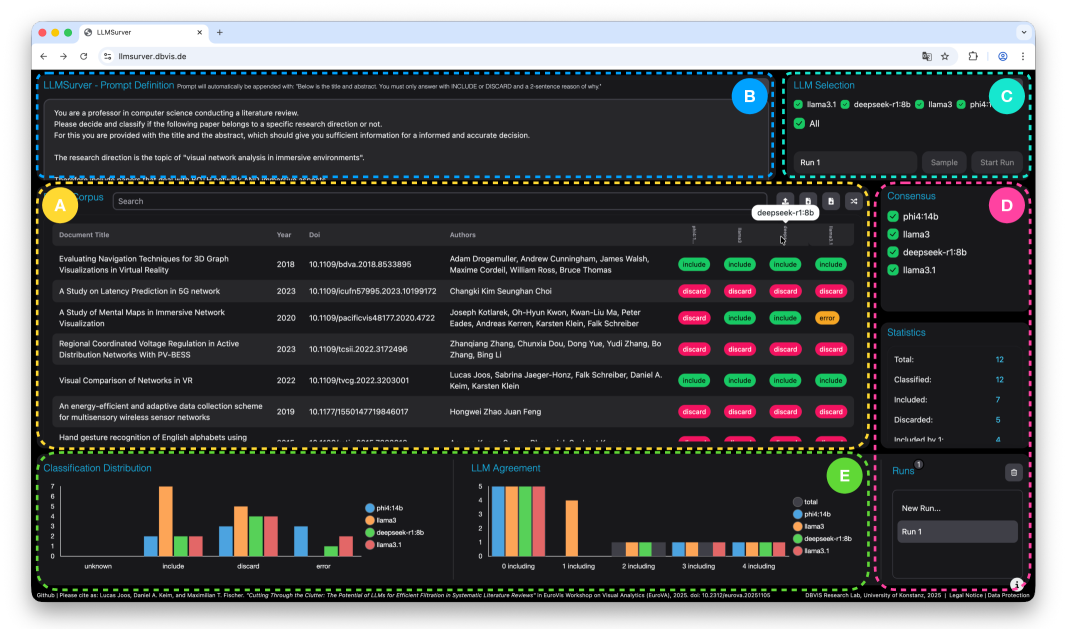
关键创新:该方法的核心创新在于:1) 提出了一个基于LLM的半自动化文献过滤流程,显著减少了人工工作量。2) 采用共识机制,提高了分类的准确性和鲁棒性。3) 开发了LLMSurver交互式界面,实现了人机协同,允许人工干预和修正模型输出。4) 证明了开源LLM足以胜任该任务,降低了成本。
关键设计:关键设计包括:1) 提示工程:设计清晰、明确的描述性提示,引导LLM进行准确的分类。2) 共识方案:选择合适的共识算法,例如多数投票或加权平均,综合多个LLM的分类结果。3) LLMSurver界面:提供实时检查和修改模型输出的功能,以及可视化分析工具,帮助用户快速识别和修正错误。
🖼️ 关键图片
📊 实验亮点
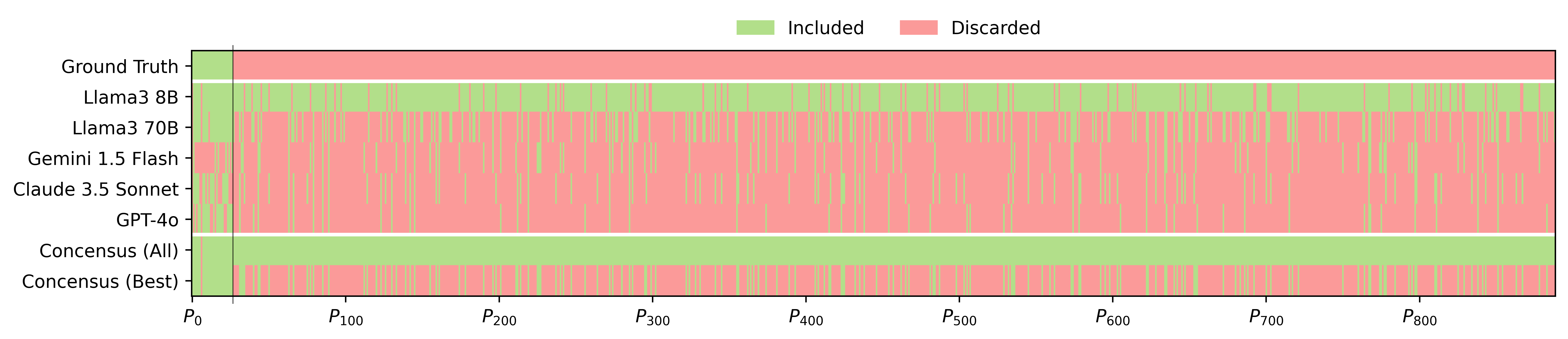
实验结果表明,该方法在包含超过8000篇候选论文的真实数据集上,显著降低了人工工作量,同时实现了比单个人工标注者更低的错误率。此外,实验还证明了现代开源LLM足以胜任该任务,无需依赖昂贵的商业模型,降低了使用成本。具体性能数据未知,但结论是该流程优于人工标注。
🎯 应用场景
该研究成果可广泛应用于各个学科领域的系统文献综述,加速科研进程,提高研究质量。通过降低人工成本和提高筛选效率,使研究人员能够更专注于文献的分析和综合,从而更好地把握研究领域的现状和发展趋势。此外,该方法还可应用于其他需要大规模文本分类的场景,例如专利分析、新闻过滤等。
📄 摘要(原文)
The creation of systematic literature reviews (SLR) is critical for analyzing the landscape of a research field and guiding future research directions. However, retrieving and filtering the literature corpus for an SLR is highly time-consuming and requires extensive manual effort, as keyword-based searches in digital libraries often return numerous irrelevant publications. In this work, we propose a pipeline leveraging multiple large language models (LLMs), classifying papers based on descriptive prompts and deciding jointly using a consensus scheme. The entire process is human-supervised and interactively controlled via our open-source visual analytics web interface, LLMSurver, which enables real-time inspection and modification of model outputs. We evaluate our approach using ground-truth data from a recent SLR comprising over 8,000 candidate papers, benchmarking both open and commercial state-of-the-art LLMs from mid-2024 and fall 2025. Results demonstrate that our pipeline significantly reduces manual effort while achieving lower error rates than single human annotators. Furthermore, modern open-source models prove sufficient for this task, making the method accessible and cost-effective. Overall, our work demonstrates how responsible human-AI collaboration can accelerate and enhance systematic literature reviews within academic workflows.