Medical Interpretability and Knowledge Maps of Large Language Models
作者: Razvan Marinescu, Victoria-Elisabeth Gruber, Diego Fajardo
分类: cs.LG, cs.AI
发布日期: 2025-10-13
备注: 29 pages, 34 figures, 5 tables
💡 一句话要点
研究大型语言模型在医学领域的知识表征与处理方式,揭示模型内部知识图谱。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学可解释性 知识图谱 模型分析 层消融
📋 核心要点
- 大型语言模型在医学领域应用广泛,但其内部知识表示和处理机制仍是黑盒,缺乏可解释性。
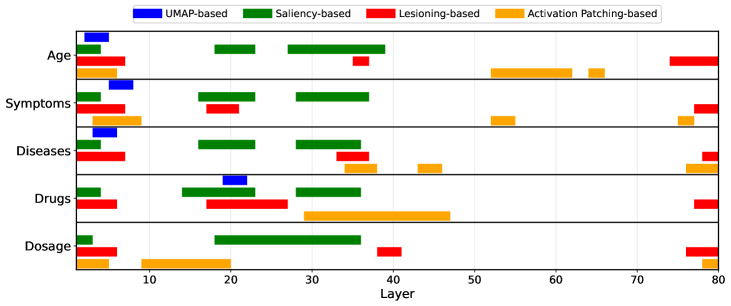
- 通过多种可解释性技术,构建LLM的医学知识图谱,揭示模型内部关于年龄、症状、疾病和药物的知识存储位置。
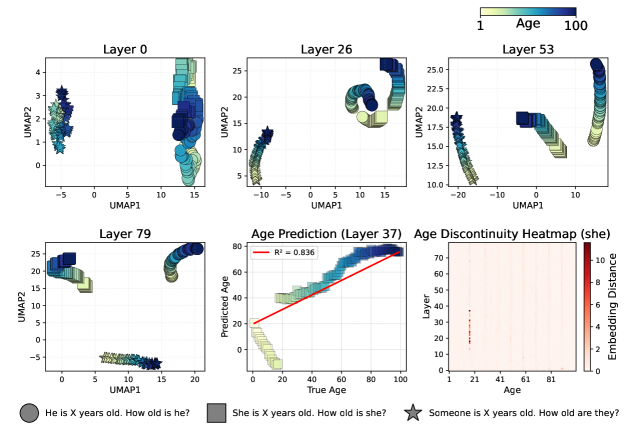
- 实验发现Llama3.3-70B的大部分医学知识在前一半层处理,并观察到年龄编码的非线性、疾病进展的循环性等现象。
📝 摘要(中文)
本文针对大型语言模型(LLM)在医学领域的内部可解释性进行了系统性研究。通过四种不同的可解释性技术,研究了LLM如何表示和处理医学知识:(1)中间激活的UMAP投影,(2)基于梯度的模型权重显著性分析,(3)层消融/移除,以及(4)激活修补。我们展示了五个LLM的知识图谱,这些图谱以粗略的分辨率显示了模型中存储的关于患者年龄、医疗症状、疾病和药物的知识的位置。特别是对于Llama3.3-70B,我们发现大多数医学知识都在模型的前半部分层中处理。此外,我们发现了一些有趣的现象:(i)年龄通常以非线性且有时是不连续的方式在模型的中间层进行编码,(ii)疾病进展表示在模型的某些层中是非单调的和循环的,(iii)在Llama3.3-70B中,药物按医学专业而非作用机制更好地聚类,尤其对于Llama3.3-70B,以及(iv)Gemma3-27B和MedGemma-27B的激活在中间层崩溃,但在最终层恢复。这些结果可以通过建议在模型的哪些层应用这些技术来指导未来对LLM进行微调、取消学习或消除医学任务偏差的研究。
🔬 方法详解
问题定义:现有的大型语言模型在医学领域的应用缺乏可解释性,难以理解模型如何存储和处理医学知识。这限制了模型在医疗领域的可靠性和安全性,也阻碍了针对性地优化和改进模型。
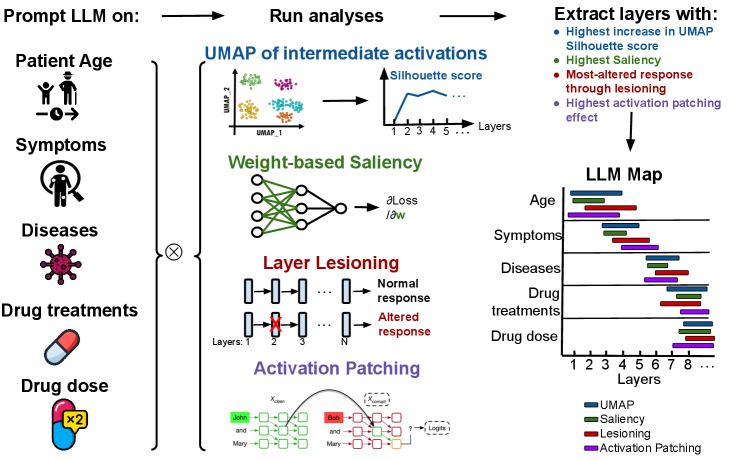
核心思路:通过多种可解释性技术,对LLM的内部状态进行分析,构建知识图谱,从而揭示模型中医学知识的存储位置和处理方式。核心在于将复杂的模型内部状态可视化和量化,以便理解。
技术框架:该研究采用四种可解释性技术: 1. UMAP投影:将中间激活层的向量降维可视化,观察不同概念的聚类情况。 2. 梯度显著性分析:计算模型权重对特定输入的敏感度,确定关键权重。 3. 层消融/移除:移除部分层,观察模型性能变化,评估层的重要性。 4. 激活修补:替换部分激活,观察模型输出变化,分析激活的影响。
关键创新:该研究的创新在于系统性地将多种可解释性技术应用于医学领域的LLM,并构建了知识图谱,揭示了模型内部知识表示的复杂性和非线性。此外,还发现了特定模型(如Llama3.3-70B)中医学知识处理的层级特性。
关键设计:研究中使用的LLM包括Llama3.3-70B、Gemma3-27B、MedGemma-27B等。针对不同的医学概念(年龄、症状、疾病、药物),设计了特定的输入和分析方法。例如,在药物分析中,比较了按医学专业和作用机制聚类的效果。
🖼️ 关键图片
📊 实验亮点
研究发现Llama3.3-70B的大部分医学知识在前一半层处理。年龄编码在中间层呈现非线性甚至不连续的特性。疾病进展表示在某些层中是非单调和循环的。Llama3.3-70B中,药物按医学专业比按作用机制更好地聚类。Gemma3-27B和MedGemma-27B的激活在中间层崩溃,但在最终层恢复。
🎯 应用场景
该研究成果可应用于指导医学LLM的微调、知识编辑和去偏见。通过了解模型内部知识的存储位置,可以更有针对性地进行模型优化,提高模型在医疗领域的可靠性和安全性。此外,该研究也有助于开发更透明、可信赖的医疗AI系统。
📄 摘要(原文)
We present a systematic study of medical-domain interpretability in Large Language Models (LLMs). We study how the LLMs both represent and process medical knowledge through four different interpretability techniques: (1) UMAP projections of intermediate activations, (2) gradient-based saliency with respect to the model weights, (3) layer lesioning/removal and (4) activation patching. We present knowledge maps of five LLMs which show, at a coarse-resolution, where knowledge about patient's ages, medical symptoms, diseases and drugs is stored in the models. In particular for Llama3.3-70B, we find that most medical knowledge is processed in the first half of the model's layers. In addition, we find several interesting phenomena: (i) age is often encoded in a non-linear and sometimes discontinuous manner at intermediate layers in the models, (ii) the disease progression representation is non-monotonic and circular at certain layers of the model, (iii) in Llama3.3-70B, drugs cluster better by medical specialty rather than mechanism of action, especially for Llama3.3-70B and (iv) Gemma3-27B and MedGemma-27B have activations that collapse at intermediate layers but recover by the final layers. These results can guide future research on fine-tuning, un-learning or de-biasing LLMs for medical tasks by suggesting at which layers in the model these techniques should be applied.