Part II: ROLL Flash -- Accelerating RLVR and Agentic Training with Asynchrony
作者: Han Lu, Zichen Liu, Shaopan Xiong, Yancheng He, Wei Gao, Yanan Wu, Weixun Wang, Jiashun Liu, Yang Li, Haizhou Zhao, Ju Huang, Siran Yang, Xiaoyang Li, Yijia Luo, Zihe Liu, Ling Pan, Junchi Yan, Wei Wang, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng
分类: cs.LG, cs.AI
发布日期: 2025-10-13
💡 一句话要点
ROLL Flash:通过异步化加速RLVR和Agentic任务中的强化学习训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 异步训练 大型语言模型 资源利用率 并行计算
📋 核心要点
- 现有同步强化学习后训练系统存在资源利用率低和可扩展性受限的问题,难以满足大型语言模型的需求。
- ROLL Flash通过细粒度并行和rollout-train解耦,实现了完全异步的训练架构,提高了资源利用率。
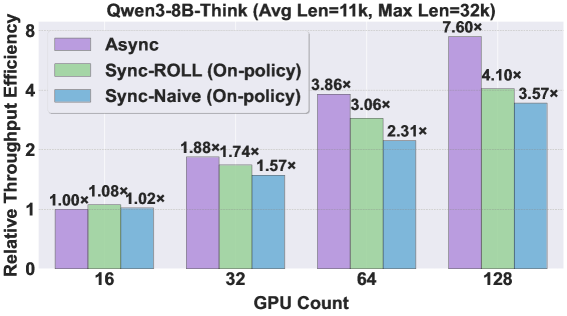
- 实验表明,ROLL Flash在RLVR和agentic任务上分别实现了高达2.24倍和2.72倍的加速,且性能与同步训练相当。
📝 摘要(中文)
同步强化学习(RL)后训练已成为增强大型语言模型(LLM)多样化能力的关键步骤。然而,许多旨在加速RL后训练的系统仍然面临资源利用率低和可扩展性有限的问题。我们提出了ROLL Flash,该系统扩展了ROLL,原生支持异步RL后训练。ROLL Flash建立在两个核心设计原则之上:细粒度并行性和rollout-train解耦。在这些原则的指导下,ROLL Flash提供了灵活的编程接口,支持完全异步的训练架构和高效的rollout机制,包括队列调度和环境级异步执行。通过全面的理论分析和广泛的实验,我们证明了ROLL Flash显著提高了资源利用率和可扩展性,优于同步RL后训练。在使用与同步基线相同的GPU预算下,ROLL Flash在RLVR任务上实现了高达2.24倍的加速,在agentic任务上实现了高达2.72倍的加速。此外,我们实现了几种流行的离策略算法,并验证了异步训练可以达到与同步训练相当的性能。
🔬 方法详解
问题定义:论文旨在解决同步强化学习后训练中资源利用率低和可扩展性受限的问题。现有的同步训练方法需要等待所有rollout完成才能进行训练,导致GPU等计算资源在rollout过程中出现空闲,降低了整体效率。尤其是在大规模模型和复杂环境中,这个问题更加突出。
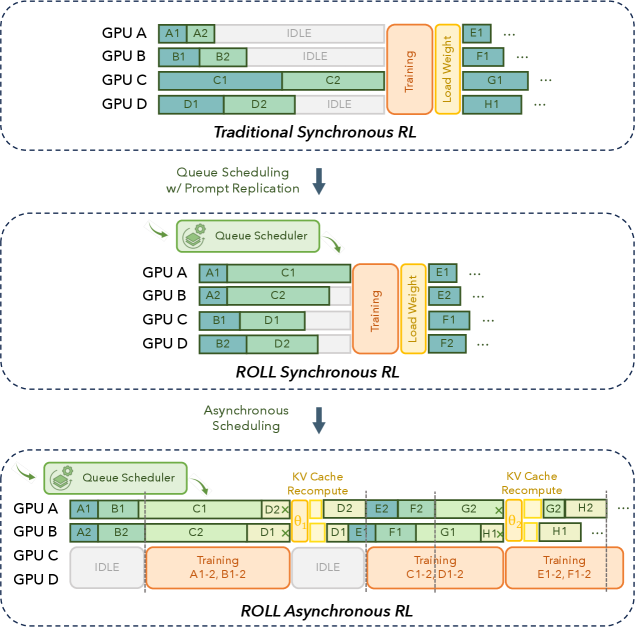
核心思路:ROLL Flash的核心思路是采用异步训练的方式,将rollout和训练过程解耦,并实现细粒度的并行。通过异步执行rollout和训练,可以充分利用计算资源,避免同步等待造成的浪费。同时,细粒度的并行允许更灵活的资源调度和任务分配,进一步提高效率。
技术框架:ROLL Flash的整体架构包含rollout模块和训练模块。Rollout模块负责与环境交互,生成训练数据。训练模块负责利用rollout数据更新模型参数。这两个模块通过队列进行通信,实现异步执行。具体流程如下:Rollout模块将生成的数据放入队列,训练模块从队列中获取数据进行训练。ROLL Flash还支持环境级别的异步执行,允许不同的环境并行运行,进一步提高rollout效率。
关键创新:ROLL Flash最重要的技术创新点在于其完全异步的训练架构和细粒度的并行机制。与传统的同步训练方法相比,ROLL Flash无需等待所有rollout完成即可开始训练,从而显著提高了资源利用率。此外,ROLL Flash还支持环境级别的异步执行,进一步提高了rollout效率。
关键设计:ROLL Flash的关键设计包括:1) 采用队列调度机制,实现rollout和训练模块之间的异步通信;2) 支持环境级别的异步执行,允许不同的环境并行运行;3) 提供灵活的编程接口,方便用户自定义rollout和训练过程;4) 针对不同的RL算法,优化了异步训练的策略,确保性能与同步训练相当。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ROLL Flash在使用与同步基线相同的GPU预算下,在RLVR任务上实现了高达2.24倍的加速,在agentic任务上实现了高达2.72倍的加速。此外,通过实现几种流行的离策略算法,验证了异步训练可以达到与同步训练相当的性能。这些结果充分证明了ROLL Flash在提高资源利用率和加速强化学习训练方面的有效性。
🎯 应用场景
ROLL Flash可应用于各种需要强化学习后训练的场景,例如机器人控制、游戏AI、自然语言处理等。通过提高训练效率和资源利用率,ROLL Flash可以加速大型语言模型的开发和部署,并降低训练成本。未来,ROLL Flash有望成为强化学习后训练的标准工具,推动人工智能技术的进步。
📄 摘要(原文)
Synchronous Reinforcement Learning (RL) post-training has emerged as a crucial step for enhancing Large Language Models (LLMs) with diverse capabilities. However, many systems designed to accelerate RL post-training still suffer from low resource utilization and limited scalability. We present ROLL Flash, a system that extends ROLL with native support for asynchronous RL post-training. ROLL Flash is built upon two core design principles: fine-grained parallelism and rollout-train decoupling. Guided by these principles, ROLL Flash provides flexible programming interfaces that enable a fully asynchronous training architecture and support efficient rollout mechanisms, including queue scheduling and environment-level asynchronous execution. Through comprehensive theoretical analysis and extensive experiments, we demonstrate that ROLL Flash significantly improves resource utilization and scalability over synchronous RL post-training. ROLL Flash achieves up to 2.24x speedup on RLVR tasks and 2.72x on agentic tasks, using the same GPU budget as synchronous baselines. Furthermore, we implement several popular off-policy algorithms and verify that asynchronous training can achieve performance on par with synchronous training.