ENIGMA: The Geometry of Reasoning and Alignment in Large-Language Models
作者: Gareth Seneque, Lap-Hang Ho, Nafise Erfanian Saeedi, Jeffrey Molendijk, Ariel Kuperman, Tim Elson
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-13 (更新: 2025-10-16)
备注: 52 pages, 10 figures, author typo corrected, abstract typo corrected
💡 一句话要点
ENIGMA:通过信息几何优化LLM的推理、对齐和鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 信息几何 强化学习 对齐 鲁棒性 推理 最优传输
📋 核心要点
- 现有LLM训练在推理、对齐和鲁棒性方面存在挑战,缺乏统一的优化框架。
- ENIGMA将组织策略视为信息流形上的方向,通过信息几何方法联合优化推理、对齐和鲁棒性。
- 实验表明,ENIGMA在小型LLM上实现了更稳定的训练动态和改进的基准性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Entropic Mutual-Information Geometry Large-Language Model Alignment (ENIGMA) 的新型大语言模型(LLM)训练方法。该方法将组织策略/原则视为模型信息流形上的移动方向,从而联合提升推理、对齐和鲁棒性。ENIGMA的单循环训练器结合了Group-Relative Policy Optimisation (GRPO)(一种无需评论器的在线策略强化学习方法,仅使用Chain-of-Thought (CoT)格式的奖励)、Self-Supervised Alignment with Mutual Information (SAMI)风格的对称InfoNCE辅助损失,以及隐藏状态分布上的熵Sinkhorn最优传输正则化器,以约束几何漂移。此外,本文还引入了infoNCE指标,该指标在匹配负样本下专门用于标准MI下界,以衡量模型CoT对这些策略的编码强度。这些指标包括一个充分性指标(SI),该指标能够在训练之前选择和创建最大化下游性能的原则。在小型(1B)LLM上的实验表明,高SI原则预测了比GRPO消融更稳定的训练动态和改进的基准性能。对训练模型的几何信息分析验证了流形中理想的结构变化。这些结果支持了推理、对齐和鲁棒性是单一信息几何目标的投影这一假设,并且使用ENIGMA训练的模型在不使用奖励模型的情况下表现出有原则的推理,为可信的能力提供了一条途径。
🔬 方法详解
问题定义:现有的大语言模型训练方法通常将推理、对齐和鲁棒性作为独立的目标进行优化,缺乏一个统一的框架。这导致模型在不同任务上的表现不一致,难以保证模型行为符合预期,并且容易受到对抗攻击。现有方法在对齐方面依赖于人工设计的奖励模型,成本高昂且存在偏差风险。
核心思路:ENIGMA的核心思路是将组织或机构的策略和原则视为大语言模型信息流形上的移动方向。通过优化模型在信息流形上的几何结构,可以同时提升模型的推理能力、对齐程度和鲁棒性。这种方法将多个目标统一到一个信息几何框架下,避免了独立优化带来的问题。
技术框架:ENIGMA采用单循环训练器,主要包含三个组成部分:1) Group-Relative Policy Optimisation (GRPO):一种在线策略强化学习方法,使用Chain-of-Thought (CoT)格式的奖励信号,无需评论器。2) Self-Supervised Alignment with Mutual Information (SAMI)风格的对称InfoNCE辅助损失:用于增强模型对齐,通过最大化输入和输出之间的互信息来实现。3) 熵Sinkhorn最优传输正则化器:用于约束隐藏状态分布的几何漂移,保证训练过程的稳定性。
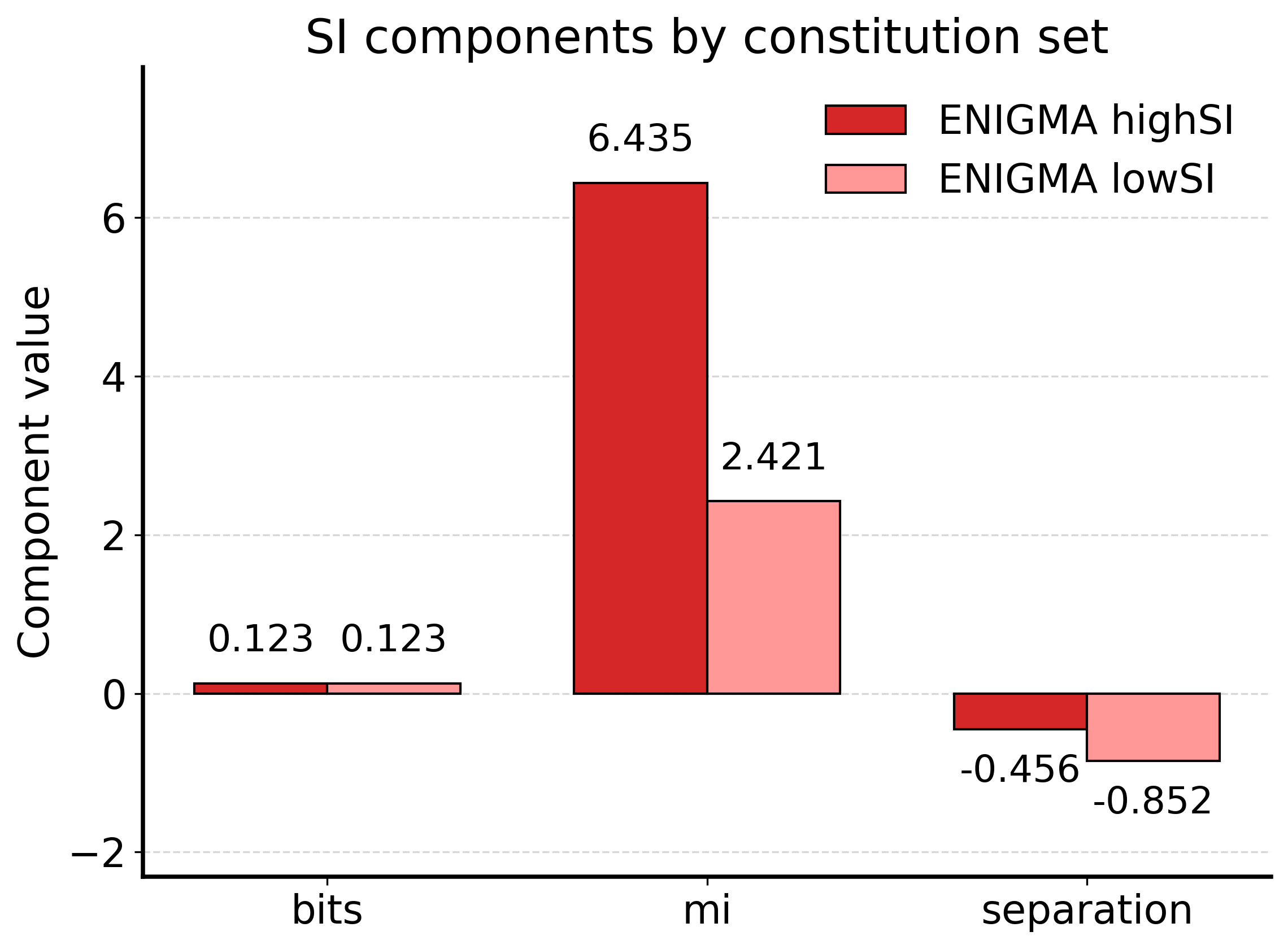
关键创新:ENIGMA的关键创新在于将推理、对齐和鲁棒性统一到一个信息几何框架下进行优化。通过将策略和原则映射到信息流形上的方向,ENIGMA能够引导模型学习符合预期行为的表示。此外,ENIGMA还引入了充分性指标(SI),用于在训练前选择和创建最大化下游性能的原则。
关键设计:ENIGMA使用Group-Relative Policy Optimisation (GRPO)作为主要的强化学习算法,该算法无需评论器,降低了训练的复杂性。SAMI风格的InfoNCE损失采用对称结构,能够更有效地学习输入和输出之间的互信息。熵Sinkhorn最优传输正则化器通过约束隐藏状态分布的几何结构,防止训练过程中出现不稳定的情况。充分性指标(SI)的计算基于infoNCE指标,用于评估不同原则对下游性能的影响。
🖼️ 关键图片
📊 实验亮点
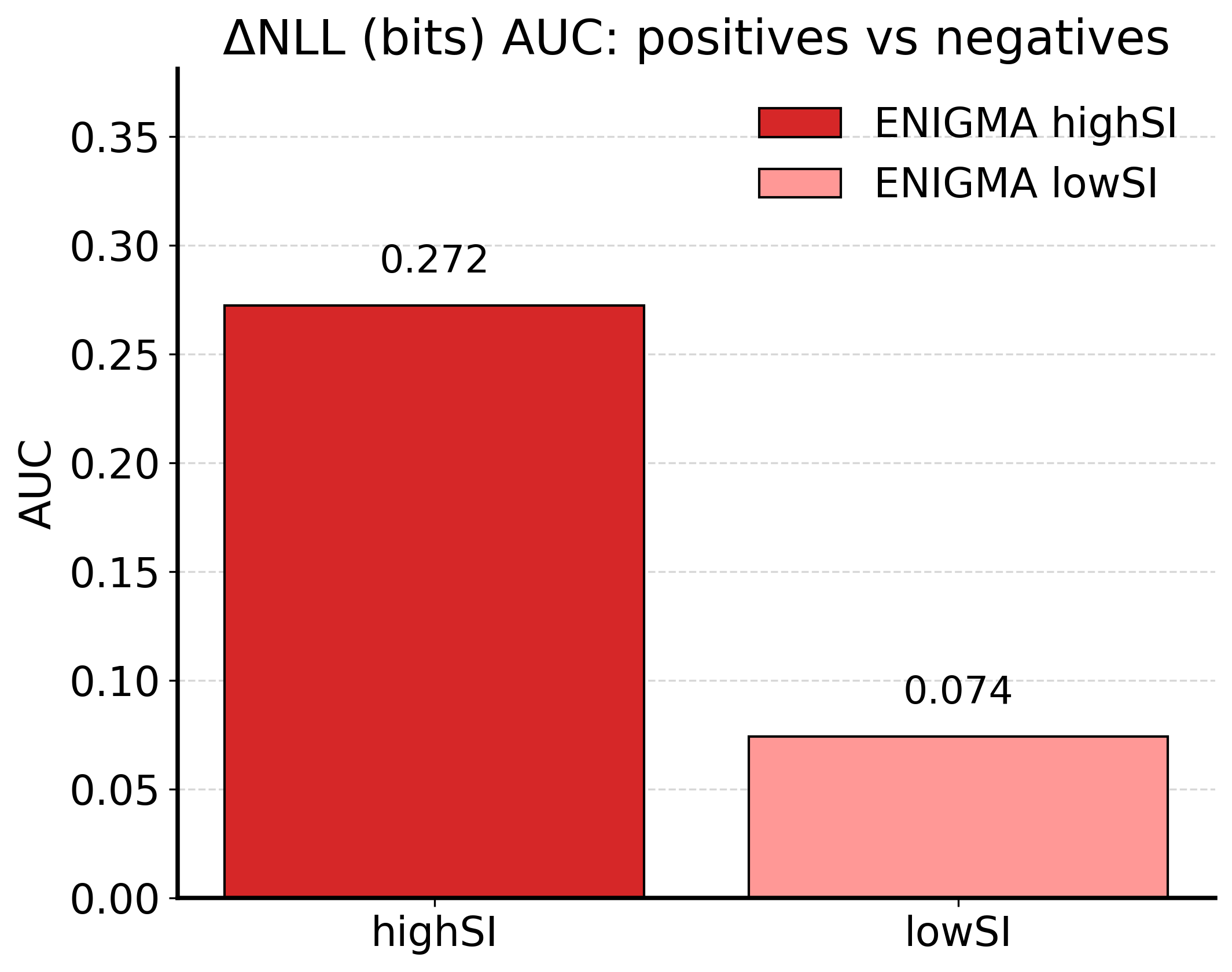
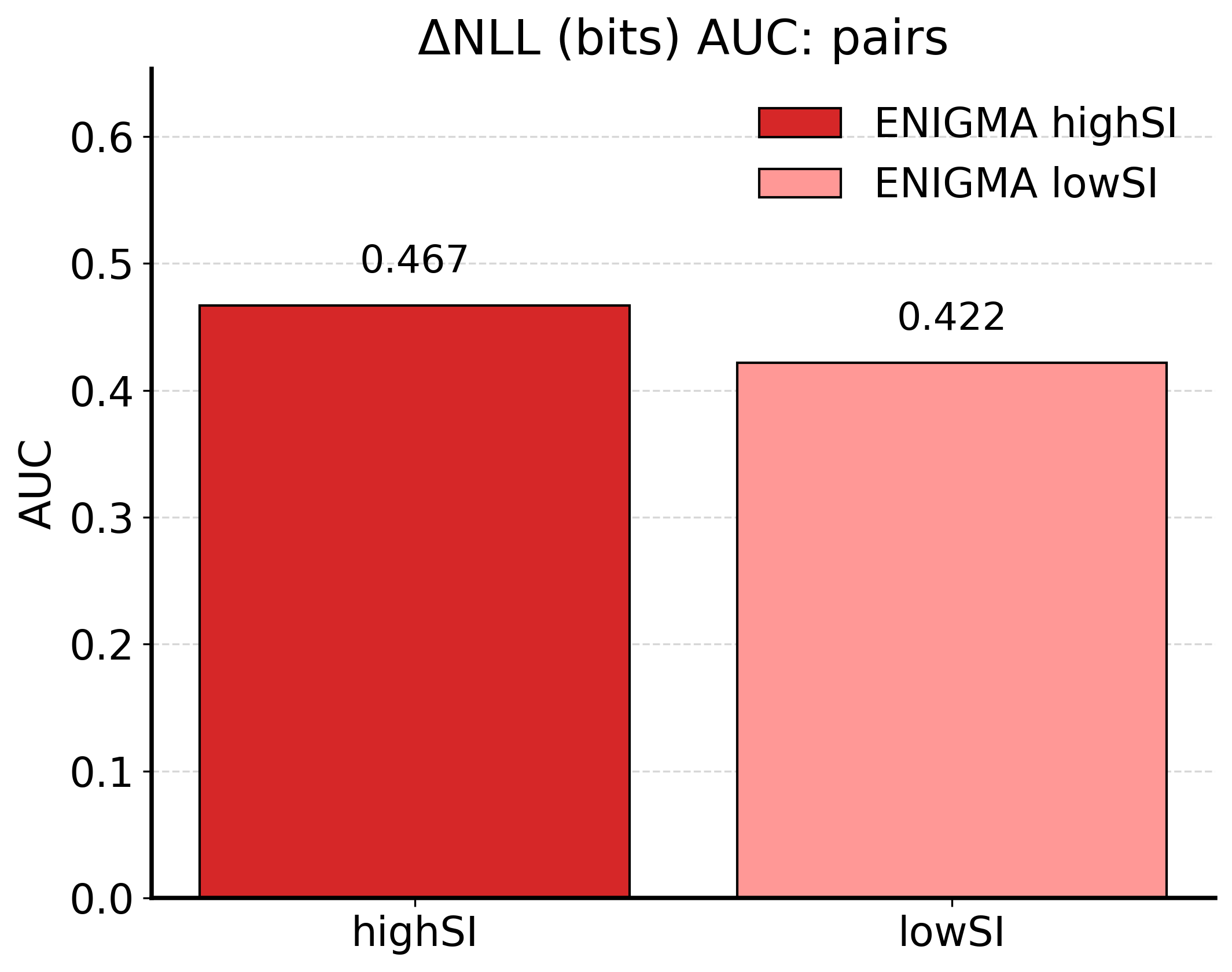
在小型(1B)LLM上的实验表明,使用高SI原则训练的模型比使用GRPO消融训练的模型表现出更稳定的训练动态和改进的基准性能。信息几何分析验证了训练模型流形中理想的结构变化,支持了推理、对齐和鲁棒性是单一信息几何目标的投影这一假设。
🎯 应用场景
ENIGMA方法可应用于各种需要可信赖的大语言模型的场景,例如:金融风控、医疗诊断、法律咨询等。通过优化模型的推理、对齐和鲁棒性,可以提高模型在这些领域的可靠性和安全性,减少潜在的风险。此外,ENIGMA还可以用于开发更安全、更负责任的人工智能系统。
📄 摘要(原文)
We present Entropic Mutual-Information Geometry Large-Language Model Alignment (ENIGMA), a novel approach to Large-Language Model (LLM) training that jointly improves reasoning, alignment and robustness by treating an organisation's policies/principles as directions to move on a model's information manifold. Our single-loop trainer combines Group-Relative Policy Optimisation (GRPO), an on-policy, critic-free RL method with Chain-of-Thought (CoT)-format only rewards; a Self-Supervised Alignment with Mutual Information (SAMI)-style symmetric InfoNCE auxiliary; and an entropic Sinkhorn optimal-transport regulariser on hidden-state distributions to bound geometry drift. We also introduce infoNCE metrics that specialise to a standard MI lower bound under matched negatives to measure how strongly a model's CoT encodes these policies. These metrics include a Sufficiency Index (SI) that enables the selection and creation of principles that maximise downstream performance prior to training. In our experiments using small (1B) LLMs, high-SI principles predict steadier training dynamics and improved benchmark performance over GRPO ablations. Our information-geometry analysis of trained models validates desirable structural change in the manifold. These results support our hypothesis that reasoning, alignment, and robustness are projections of a single information-geometric objective, and that models trained using ENIGMA demonstrate principled reasoning without the use of a reward model, offering a path to trusted capability