Efficient In-Memory Acceleration of Sparse Block Diagonal LLMs
作者: João Paulo Cardoso de Lima, Marc Dietrich, Jeronimo Castrillon, Asif Ali Khan
分类: cs.AR, cs.LG
发布日期: 2025-10-13
备注: 8 pages, to appear in IEEE Cross-disciplinary Conference on Memory-Centric Computing (CCMCC)
💡 一句话要点
提出面向稀疏分块对角LLM的高效存内加速框架,提升资源受限系统性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 存内计算 稀疏LLM 分块对角矩阵 模型加速 资源受限系统
📋 核心要点
- 现有冯·诺依曼架构在LLM推理时面临内存瓶颈,尤其是在解码阶段,导致效率低下。
- 该论文提出一种自动化的框架,利用分块对角稀疏性,优化稀疏LLM在CIM加速器上的映射和调度。
- 实验结果表明,该方法将CIM阵列利用率提高超过50%,并显著减少内存占用和浮点运算量。
📝 摘要(中文)
结构化稀疏性使得在资源受限系统上部署大型语言模型(LLM)成为可能。稠密到稀疏微调等方法通过将模型大小减少超过6.7倍来实现显著的结构化稀疏性,同时保持可接受的精度,因此特别引人注目。尽管如此,LLM推理,尤其是本质上受内存限制的解码阶段,在传统的冯·诺依曼架构上仍然非常昂贵。存内计算(CIM)架构通过直接在内存中执行计算来缓解这个问题,并且当与稀疏LLM结合使用时,能够将整个模型存储和计算在内存中,消除片外总线上的数据移动并提高效率。然而,将稀疏矩阵直接映射到CIM阵列会导致阵列利用率低和计算效率降低。在本文中,我们提出了一个自动化的框架,具有新颖的映射和调度策略,以加速CIM加速器上的稀疏LLM推理。通过利用分块对角稀疏性,我们的方法将CIM阵列利用率提高了50%以上,并在内存占用和所需浮点运算数量方面减少了4倍以上。
🔬 方法详解
问题定义:论文旨在解决在资源受限的系统上部署大型语言模型时,由于内存带宽限制导致的推理效率低下的问题。现有的方法,如直接将稀疏矩阵映射到存内计算(CIM)阵列,会导致阵列利用率低,计算效率不高。
核心思路:论文的核心思路是利用LLM中的分块对角稀疏性,设计一种优化的映射和调度策略,从而提高CIM阵列的利用率,减少内存占用和计算量。通过更有效地利用CIM的并行计算能力,加速稀疏LLM的推理过程。
技术框架:该框架包含以下主要模块:1) 稀疏LLM模型;2) 分块对角稀疏性分析模块,用于识别和提取模型中的分块对角结构;3) 映射模块,将稀疏矩阵映射到CIM阵列上,优化数据布局;4) 调度模块,确定计算任务的执行顺序,最大化阵列利用率;5) CIM加速器,执行实际的计算任务。
关键创新:该论文的关键创新在于提出了一种针对分块对角稀疏LLM的优化映射和调度策略。与现有方法相比,该方法能够更有效地利用CIM阵列的并行计算能力,显著提高阵列利用率,并减少内存占用和计算量。这种方法特别适用于资源受限的边缘设备。
关键设计:论文的关键设计包括:1) 分块大小的选择,需要权衡计算效率和存储效率;2) 映射策略,需要考虑数据局部性和阵列利用率;3) 调度策略,需要避免数据冲突和资源竞争;4) 针对CIM架构的优化,例如数据重用和流水线设计。
🖼️ 关键图片
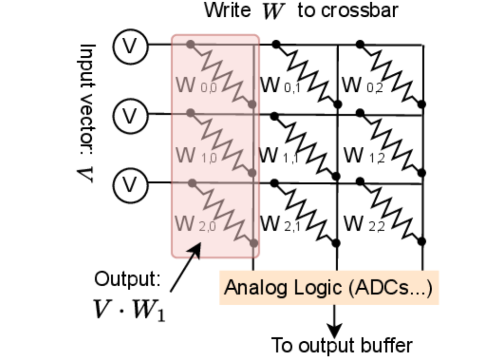


📊 实验亮点
实验结果表明,该方法将CIM阵列利用率提高了50%以上,并在内存占用和所需浮点运算数量方面减少了4倍以上。这些结果表明,该方法能够显著提高稀疏LLM在CIM加速器上的推理效率,为在资源受限的系统上部署大型语言模型提供了有效的解决方案。
🎯 应用场景
该研究成果可应用于边缘计算设备、移动设备等资源受限的场景,加速大型语言模型的推理,实现更高效的AI应用。例如,在智能手机上运行本地LLM,提供更快的响应速度和更好的用户体验。此外,该技术还可以应用于机器人、自动驾驶等领域,提升AI系统的实时性和能效。
📄 摘要(原文)
Structured sparsity enables deploying large language models (LLMs) on resource-constrained systems. Approaches like dense-to-sparse fine-tuning are particularly compelling, achieving remarkable structured sparsity by reducing the model size by over 6.7x, while still maintaining acceptable accuracy. Despite this reduction, LLM inference, especially the decode stage being inherently memory-bound, is extremely expensive on conventional Von-Neumann architectures. Compute-in-memory (CIM) architectures mitigate this by performing computations directly in memory, and when paired with sparse LLMs, enable storing and computing the entire model in memory, eliminating the data movement on the off-chip bus and improving efficiency. Nonetheless, naively mapping sparse matrices onto CIM arrays leads to poor array utilization and diminished computational efficiency. In this paper, we present an automated framework with novel mapping and scheduling strategies to accelerate sparse LLM inference on CIM accelerators. By exploiting block-diagonal sparsity, our approach improves CIM array utilization by over 50%, achieving more than 4x reduction in both memory footprint and the number of required floating-point operations.