Protein as a Second Language for LLMs
作者: Xinhui Chen, Zuchao Li, Mengqi Gao, Yufeng Zhang, Chak Tou Leong, Haoyang Li, Jiaqi Chen
分类: cs.LG, cs.AI, q-bio.BM
发布日期: 2025-10-13
备注: Main paper: 9 pages, 6 figures. With references and appendix: 18 pages, 9 figures total. Submitted to ICLR 2026 (under review)
💡 一句话要点
提出蛋白质二语框架,利用LLM零样本理解蛋白质功能,超越特定领域模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 蛋白质功能预测 大型语言模型 零样本学习 上下文学习 蛋白质二语 生物信息学 提示工程
📋 核心要点
- 现有蛋白质功能预测方法依赖于任务特定的适配器或大规模监督微调,泛化性不足。
- 论文提出“蛋白质二语”框架,将蛋白质序列转化为LLM可理解的语言,通过上下文学习实现零样本预测。
- 实验表明,该方法在多个LLM上均有提升,甚至超越了微调的蛋白质专用模型,展现了LLM在蛋白质理解方面的潜力。
📝 摘要(中文)
本文提出了“蛋白质二语”框架,将氨基酸序列转化为一种新的符号语言中的句子,大型语言模型可以通过上下文范例来解释这种语言。该方法自适应地构建序列-问题-答案三元组,以零样本方式揭示功能线索,无需任何进一步的训练。为了支持这一过程,作者构建了一个包含79,926个蛋白质问答实例的双语语料库,涵盖属性预测、描述性理解和扩展推理。实验结果表明,该方法在各种开源LLM和GPT-4上都取得了持续的提升,ROUGE-L指标最高提升17.2%(平均+7%),甚至超过了微调的蛋白质特定语言模型。这些结果表明,通用LLM在蛋白质语言提示的引导下,可以胜过领域专用模型,为基础模型中的蛋白质理解提供了一种可扩展的途径。
🔬 方法详解
问题定义:蛋白质功能预测是生物学中的一个基本问题,旨在确定蛋白质序列的功能和属性。现有方法通常依赖于任务特定的适配器或大规模的监督微调,这限制了它们在新蛋白质序列上的泛化能力,并且需要大量的标注数据。因此,如何在无需大量训练数据的情况下,利用大型语言模型(LLM)理解和预测蛋白质功能是一个重要的挑战。
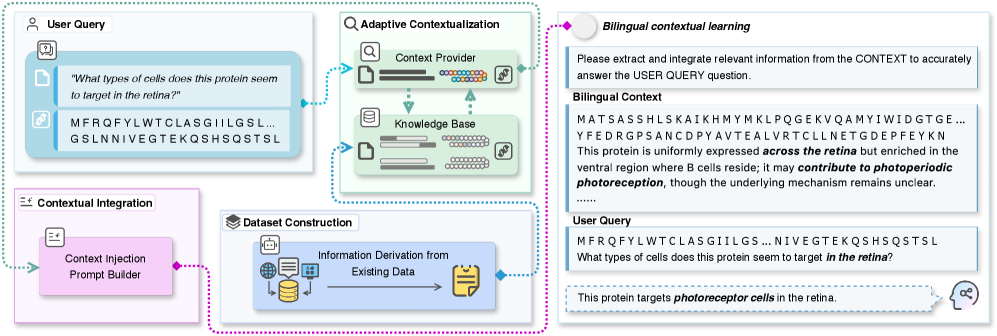
核心思路:论文的核心思路是将蛋白质序列视为一种新的语言,并利用LLM的上下文学习能力来理解和预测蛋白质功能。具体来说,作者将氨基酸序列转化为一种符号语言中的句子,并通过构建序列-问题-答案三元组来引导LLM理解蛋白质的功能线索。这种方法无需对LLM进行额外的训练,即可实现零样本的蛋白质功能预测。
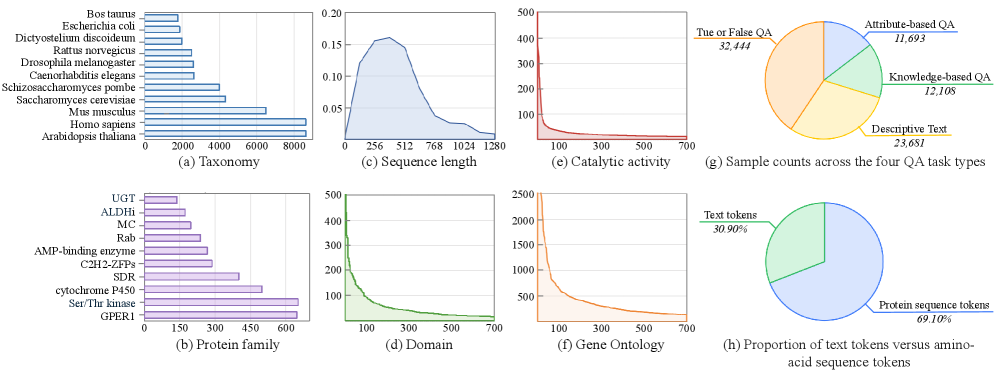
技术框架:该框架主要包含以下几个步骤:1) 将蛋白质序列转化为符号语言;2) 构建序列-问题-答案三元组,其中问题涉及蛋白质的功能或属性,答案是相应的解释或预测;3) 将三元组作为上下文输入到LLM中,利用LLM的生成能力来预测蛋白质的功能或属性。作者还构建了一个包含79,926个蛋白质问答实例的双语语料库,用于支持该框架的训练和评估。
关键创新:该论文的关键创新在于提出了“蛋白质二语”框架,将蛋白质序列转化为LLM可以理解的语言,并利用上下文学习实现零样本的蛋白质功能预测。与现有方法相比,该方法无需对LLM进行额外的训练,即可实现较好的预测性能,并且具有更好的泛化能力。此外,作者构建的蛋白质问答语料库也为蛋白质功能预测领域提供了新的资源。
关键设计:在构建序列-问题-答案三元组时,作者采用了自适应的方法,根据蛋白质序列的特征选择合适的问题类型。例如,对于具有特定结构域的蛋白质,可以提出关于该结构域功能的问题。此外,作者还设计了一系列的提示工程技巧,以提高LLM的预测性能。例如,可以使用多个示例来引导LLM理解蛋白质的功能线索,或者使用不同的问题模板来提高LLM的生成能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在各种开源LLM和GPT-4上都取得了显著的提升,ROUGE-L指标最高提升17.2%(平均+7%),甚至超过了微调的蛋白质特定语言模型。这表明,通用LLM在蛋白质语言提示的引导下,可以胜过领域专用模型,为基础模型中的蛋白质理解提供了一种可扩展的途径。
🎯 应用场景
该研究成果可应用于新蛋白质序列的功能预测、蛋白质工程、药物发现等领域。通过利用通用LLM的强大能力,可以加速蛋白质功能研究,降低实验成本,并为生物医药领域的发展提供新的思路。未来,该方法有望扩展到其他生物序列的分析,例如DNA和RNA序列。
📄 摘要(原文)
Deciphering the function of unseen protein sequences is a fundamental challenge with broad scientific impact, yet most existing methods depend on task-specific adapters or large-scale supervised fine-tuning. We introduce the "Protein-as-Second-Language" framework, which reformulates amino-acid sequences as sentences in a novel symbolic language that large language models can interpret through contextual exemplars. Our approach adaptively constructs sequence-question-answer triples that reveal functional cues in a zero-shot setting, without any further training. To support this process, we curate a bilingual corpus of 79,926 protein-QA instances spanning attribute prediction, descriptive understanding, and extended reasoning. Empirically, our method delivers consistent gains across diverse open-source LLMs and GPT-4, achieving up to 17.2% ROUGE-L improvement (average +7%) and even surpassing fine-tuned protein-specific language models. These results highlight that generic LLMs, when guided with protein-as-language cues, can outperform domain-specialized models, offering a scalable pathway for protein understanding in foundation models.