Emergence of hybrid computational dynamics through reinforcement learning
作者: Roman A. Kononov, Nikita A. Pospelov, Konstantin V. Anokhin, Vladimir V. Nekorkin, Oleg V. Maslennikov
分类: cs.LG, cs.NE, nlin.AO, q-bio.NC
发布日期: 2025-10-13
备注: 22 pages, 11 figures
💡 一句话要点
强化学习驱动循环神经网络涌现混合计算动力学,提升决策任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 循环神经网络 计算动力学 吸引子 决策任务
📋 核心要点
- 现有方法难以理解学习算法如何影响神经网络涌现的计算策略,特别是强化学习与监督学习的差异。
- 本文提出强化学习能够驱动循环神经网络涌现混合吸引子架构,从而实现更灵活的证据整合和决策维持。
- 实验表明,强化学习训练的网络在任务复杂性增加时表现出更强的鲁棒性和性能提升,优于监督学习。
📝 摘要(中文)
理解学习算法如何塑造神经网络中涌现的计算策略是机器智能领域的一个根本性挑战。本文表明,在相同的决策任务上训练时,强化学习(RL)和监督学习(SL)驱动循环神经网络(RNN)走向根本不同的计算解决方案。通过系统的动力系统分析,我们揭示了RL自发地发现混合吸引子架构,将用于决策维持的稳定不动点吸引子与用于灵活证据整合的准周期吸引子相结合。这与SL几乎完全收敛到更简单的仅不动点解决方案形成鲜明对比。我们进一步表明,RL通过一种强大的隐式正则化形式来塑造功能平衡的神经群体——这种结构特征增强了鲁棒性,并且在SL训练的网络中发现的更异构的解决方案中明显缺失。这些复杂动力学在RL中的普遍性受到权重初始化的可控调节,并且与性能提升密切相关,尤其是在任务复杂性增加时。我们的结果确立了学习算法作为涌现计算的主要决定因素,揭示了基于奖励的优化如何自主地发现复杂的动力学机制,而这些机制对于直接基于梯度的优化来说不太容易获得。这些发现为神经计算提供了机制性见解,并为设计自适应AI系统提供了可操作的原则。
🔬 方法详解
问题定义:论文旨在解决如何理解不同学习范式(强化学习与监督学习)对循环神经网络(RNN)涌现计算动力学的影响。现有方法主要关注网络架构设计,而忽略了学习算法本身在决定网络动态行为中的作用。监督学习虽然易于实现,但在复杂决策任务中可能无法发现最优的计算策略,缺乏灵活性和鲁棒性。
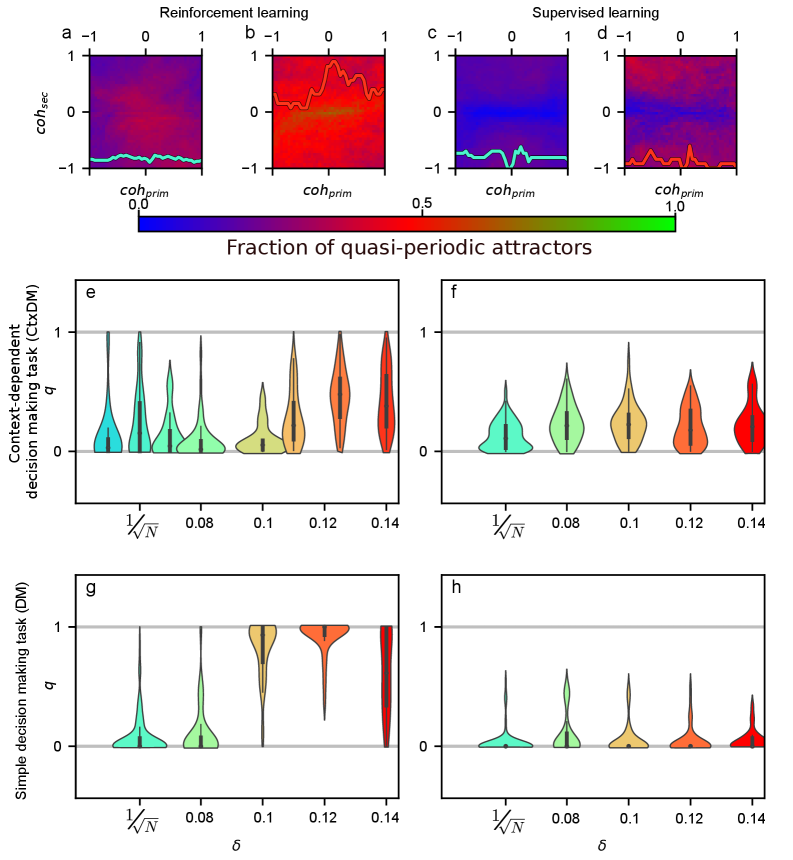
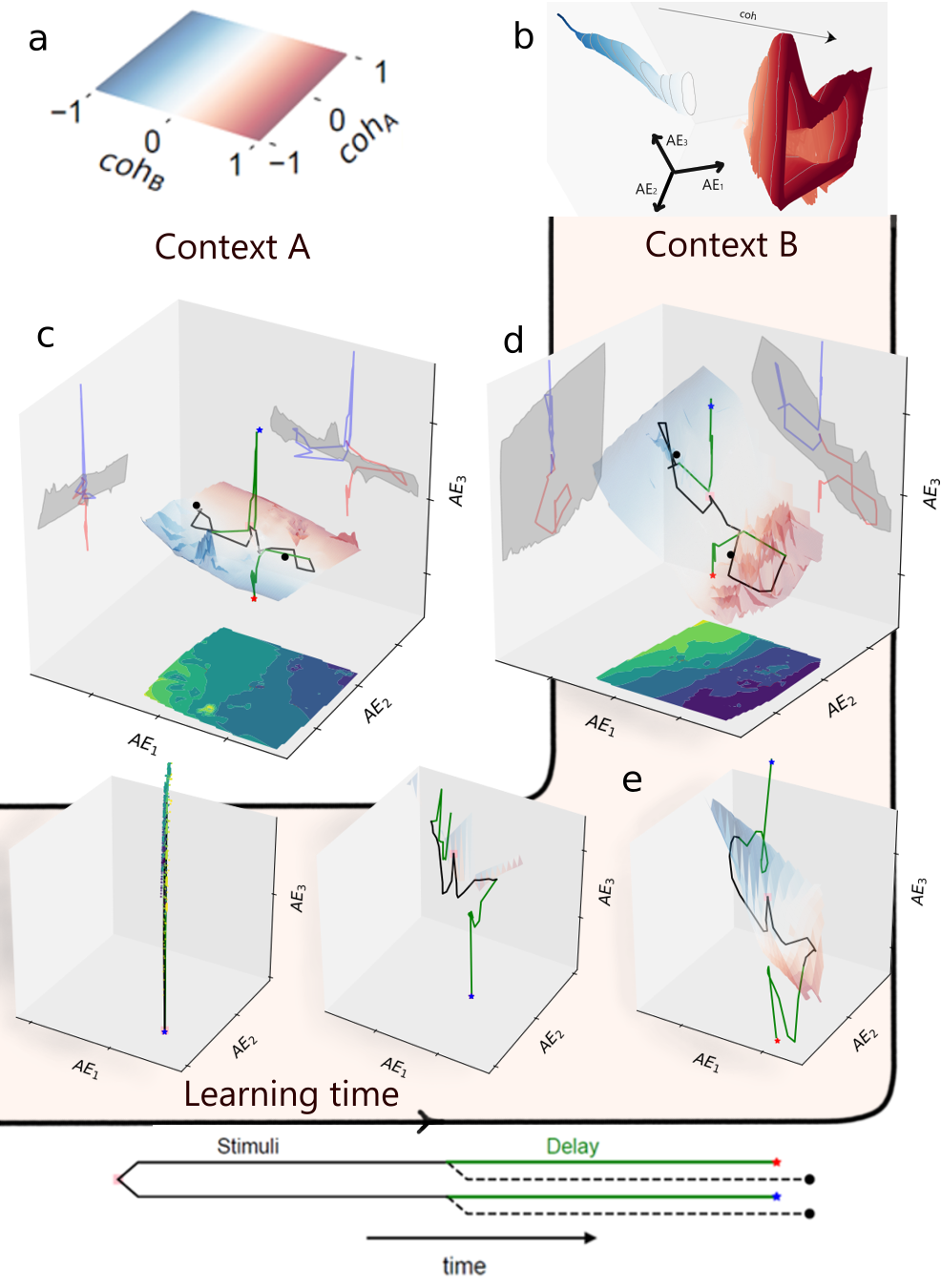
核心思路:论文的核心思路是比较强化学习(RL)和监督学习(SL)在训练相同RNN完成决策任务时,所产生的计算动力学的差异。作者假设RL能够通过奖励机制引导网络探索更复杂的动态行为,例如混合吸引子架构,从而实现更优的决策性能。这种混合架构结合了稳定不动点和准周期吸引子,分别用于决策维持和证据整合。
技术框架:论文的技术框架主要包括以下几个部分:1)设计一个决策任务,作为RNN的训练环境;2)使用RL和SL分别训练RNN;3)利用动力系统分析方法,例如相平面分析、特征值分析等,研究训练后RNN的计算动力学;4)分析神经元群体的结构特征,例如功能平衡性;5)评估不同训练方法下RNN的决策性能和鲁棒性。
关键创新:论文最重要的技术创新点在于揭示了强化学习作为一种隐式正则化器,能够引导RNN自发地发现混合吸引子架构,并塑造功能平衡的神经群体。这种混合架构和平衡性增强了网络的鲁棒性和决策性能,尤其是在复杂任务中。与监督学习相比,强化学习能够探索更广阔的解空间,发现更优的计算策略。
关键设计:论文的关键设计包括:1)使用标准的循环神经网络(RNN)模型;2)设计合适的奖励函数,引导RL智能体学习决策策略;3)采用动力系统分析工具,例如计算李雅普诺夫指数、绘制相平面图等,来分析RNN的计算动力学;4)通过权重初始化策略来控制RL训练的探索程度;5)使用性能指标(例如准确率、反应时间)来评估不同训练方法下RNN的决策能力。
🖼️ 关键图片

📊 实验亮点
研究发现,强化学习训练的RNN能够自发地涌现混合吸引子架构,显著提升了在复杂决策任务中的性能。与监督学习相比,强化学习训练的网络表现出更强的鲁棒性和更高的准确率,尤其是在任务难度增加时。此外,强化学习还能够塑造功能平衡的神经群体,进一步增强网络的稳定性和泛化能力。
🎯 应用场景
该研究成果可应用于设计更智能、更鲁棒的自适应AI系统,尤其是在需要灵活决策和持续学习的复杂环境中,例如机器人控制、金融交易、医疗诊断等。通过理解不同学习算法对网络动态行为的影响,可以更好地设计和优化AI系统,使其能够自主地发现和利用复杂的计算策略。
📄 摘要(原文)
Understanding how learning algorithms shape the computational strategies that emerge in neural networks remains a fundamental challenge in machine intelligence. While network architectures receive extensive attention, the role of the learning paradigm itself in determining emergent dynamics remains largely unexplored. Here we demonstrate that reinforcement learning (RL) and supervised learning (SL) drive recurrent neural networks (RNNs) toward fundamentally different computational solutions when trained on identical decision-making tasks. Through systematic dynamical systems analysis, we reveal that RL spontaneously discovers hybrid attractor architectures, combining stable fixed-point attractors for decision maintenance with quasi-periodic attractors for flexible evidence integration. This contrasts sharply with SL, which converges almost exclusively to simpler fixed-point-only solutions. We further show that RL sculpts functionally balanced neural populations through a powerful form of implicit regularization -- a structural signature that enhances robustness and is conspicuously absent in the more heterogeneous solutions found by SL-trained networks. The prevalence of these complex dynamics in RL is controllably modulated by weight initialization and correlates strongly with performance gains, particularly as task complexity increases. Our results establish the learning algorithm as a primary determinant of emergent computation, revealing how reward-based optimization autonomously discovers sophisticated dynamical mechanisms that are less accessible to direct gradient-based optimization. These findings provide both mechanistic insights into neural computation and actionable principles for designing adaptive AI systems.