Refining Hybrid Genetic Search for CVRP via Reinforcement Learning-Finetuned LLM
作者: Rongjie Zhu, Cong Zhang, Zhiguang Cao
分类: cs.LG
发布日期: 2025-10-13
💡 一句话要点
提出RFTHGS框架,通过强化学习微调小型LLM,为CVRP的HGS求解器生成高性能交叉算子。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 车辆路径问题 强化学习 大型语言模型 混合遗传搜索 组合优化
📋 核心要点
- 现有VRP方法过度依赖大型通用LLM,计算成本高昂,且缺乏针对性优化。
- RFTHGS通过强化学习微调小型LLM,使其生成针对特定求解器(HGS)的高性能交叉算子。
- 实验表明,RFTHGS生成的算子性能显著超越专家设计和现有神经组合优化方法,并具备良好的泛化性。
📝 摘要(中文)
本文挑战了当前车辆路径问题(VRP)中依赖大型通用语言模型(LLM)作为自动启发式设计器的范式。研究表明,一个经过精心微调的小型专用LLM能够生成超越专家手工设计的启发式组件,应用于高级求解器中。为此,我们提出了RFTHGS,一个新颖的强化学习(RL)框架,用于微调小型LLM,使其为混合遗传搜索(HGS)求解器生成高性能的交叉算子,并应用于带容量约束的VRP(CVRP)。我们的方法采用多层、基于课程的奖励函数,逐步引导LLM掌握生成首先可编译、然后可执行、最终性能优于人类专家设计的算子。此外,我们还采用了算子缓存机制,以抑制抄袭并促进训练期间的多样性。综合实验表明,我们微调后的LLM生成的交叉算子在HGS中显著优于专家设计的算子。这种性能优势具有一致性,可以从小型实例推广到具有多达1000个节点的超大规模问题。此外,RFTHGS的性能超过了领先的神经组合优化基线、基于提示的方法以及商业LLM,如GPT-4o和GPT-4o-mini。
🔬 方法详解
问题定义:论文旨在解决带容量约束的车辆路径问题(CVRP),并提升现有混合遗传搜索(HGS)求解器的性能。现有方法主要依赖人工设计的启发式算子,或者直接使用大型通用LLM,前者设计成本高昂,后者计算资源消耗大且效果不佳。因此,如何自动生成高性能且资源友好的启发式算子是本研究要解决的核心问题。
核心思路:论文的核心思路是利用强化学习(RL)微调一个小型LLM,使其能够生成高质量的交叉算子。通过强化学习,LLM可以学习到如何生成能够提升HGS求解器性能的算子代码。这种方法避免了人工设计的繁琐,也降低了对大型通用LLM的依赖。
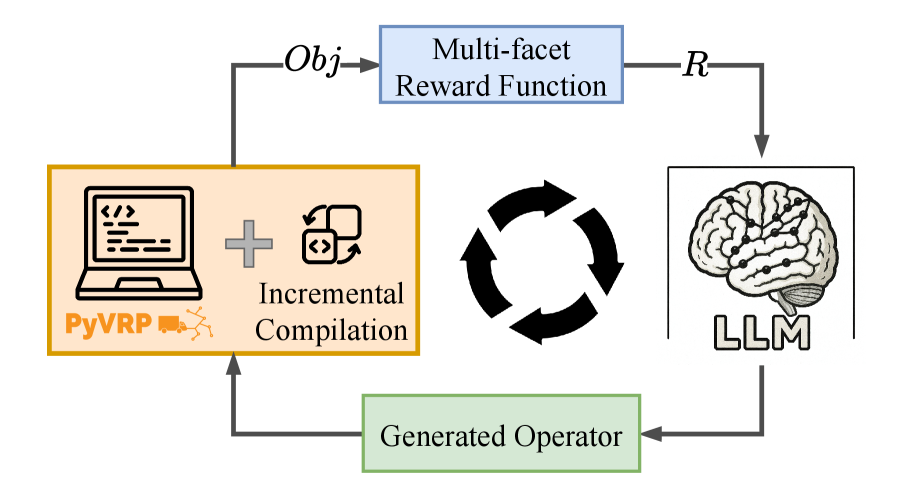
技术框架:RFTHGS框架主要包含以下几个模块:1) LLM算子生成器:使用小型LLM生成交叉算子代码;2) 强化学习环境:HGS求解器作为RL环境,执行LLM生成的算子并返回奖励;3) 奖励函数:设计多层级的奖励函数,引导LLM生成可编译、可执行且高性能的算子;4) 算子缓存:缓存已生成的算子,避免重复生成,并鼓励生成多样化的算子。整个流程是LLM生成算子,HGS执行算子并返回奖励,RL算法根据奖励更新LLM的参数,循环迭代直至LLM生成高性能算子。
关键创新:该论文的关键创新在于:1) 提出了一种基于强化学习微调小型LLM的方法,用于自动生成VRP求解器中的启发式算子;2) 设计了一种多层级的奖励函数,能够有效引导LLM生成高质量的算子;3) 引入了算子缓存机制,提高了训练效率并促进了算子的多样性。
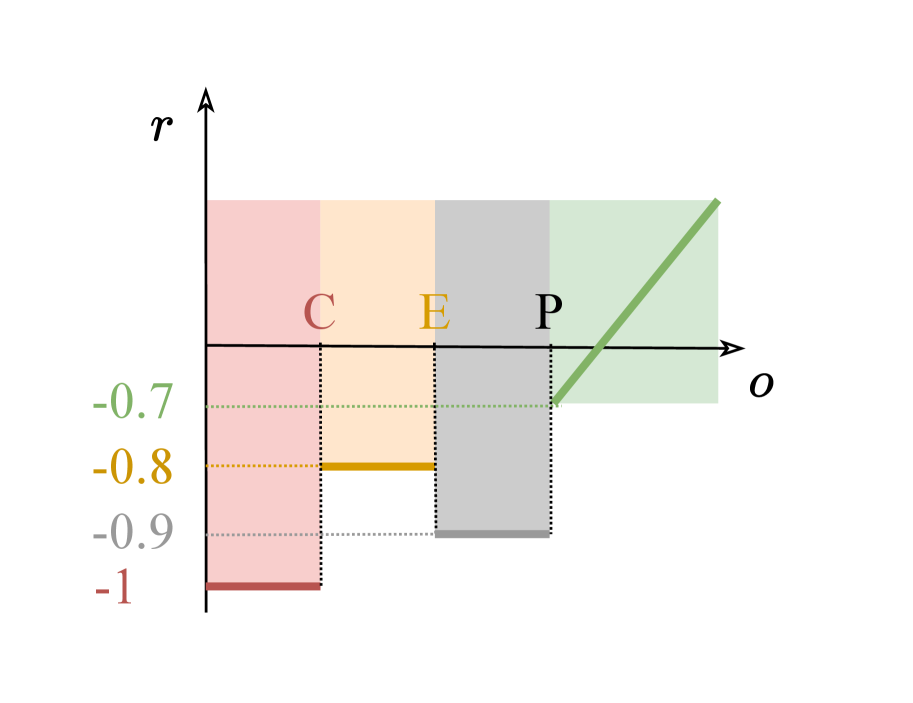
关键设计:奖励函数的设计是关键。论文采用多层级奖励,首先奖励LLM生成可编译的代码,然后奖励生成可执行的代码,最后奖励生成能够提升HGS性能的代码。这种课程学习的方式有助于LLM逐步掌握生成高质量算子的能力。算子缓存机制通过记录已生成的算子,并对重复生成的算子施加惩罚,从而鼓励LLM探索新的算子设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RFTHGS生成的交叉算子在CVRP问题上显著优于专家设计的算子,并且在不同规模的问题上都表现出一致的性能优势。具体而言,RFTHGS不仅超越了人工设计的启发式算法,还优于神经组合优化基线以及GPT-4o和GPT-4o-mini等大型商业LLM。
🎯 应用场景
该研究成果可应用于物流配送、交通运输、供应链管理等领域,通过自动生成高效的车辆路径规划策略,降低运输成本,提高运营效率。未来,该方法可以推广到其他组合优化问题,例如旅行商问题、调度问题等,具有广阔的应用前景。
📄 摘要(原文)
While large language models (LLMs) are increasingly used as automated heuristic designers for vehicle routing problems (VRPs), current state-of-the-art methods predominantly rely on prompting massive, general-purpose models like GPT-4. This work challenges that paradigm by demonstrating that a smaller, specialized LLM, when meticulously fine-tuned, can generate components that surpass expert-crafted heuristics within advanced solvers. We propose RFTHGS, a novel Reinforcement learning (RL) framework for Fine-Tuning a small LLM to generate high-performance crossover operators for the Hybrid Genetic Search (HGS) solver, applied to the Capacitated VRP (CVRP). Our method employs a multi-tiered, curriculum-based reward function that progressively guides the LLM to master generating first compilable, then executable, and finally, superior-performing operators that exceed human expert designs. This is coupled with an operator caching mechanism that discourages plagiarism and promotes diversity during training. Comprehensive experiments show that our fine-tuned LLM produces crossover operators which significantly outperform the expert-designed ones in HGS. The performance advantage remains consistent, generalizing from small-scale instances to large-scale problems with up to 1000 nodes. Furthermore, RFTHGS exceeds the performance of leading neuro-combinatorial baselines, prompt-based methods, and commercial LLMs such as GPT-4o and GPT-4o-mini.