Reinforcement Fine-Tuning of Flow-Matching Policies for Vision-Language-Action Models
作者: Mingyang Lyu, Yinqian Sun, Erliang Lin, Huangrui Li, Ruolin Chen, Feifei Zhao, Yi Zeng
分类: cs.LG, cs.RO
发布日期: 2025-10-11
💡 一句话要点
提出流政策优化算法以提升视觉-语言-动作模型的强化学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作 强化学习 流匹配 在线微调 策略优化 多模态学习 机器人控制
📋 核心要点
- 现有的视觉-语言-动作模型在强化学习中面临重要性采样计算复杂性的问题,限制了其性能提升。
- 本文提出的流政策优化算法通过重新构造重要性采样,利用条件流匹配目标的变化来提高学习效率。
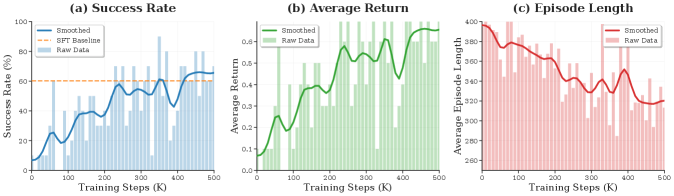
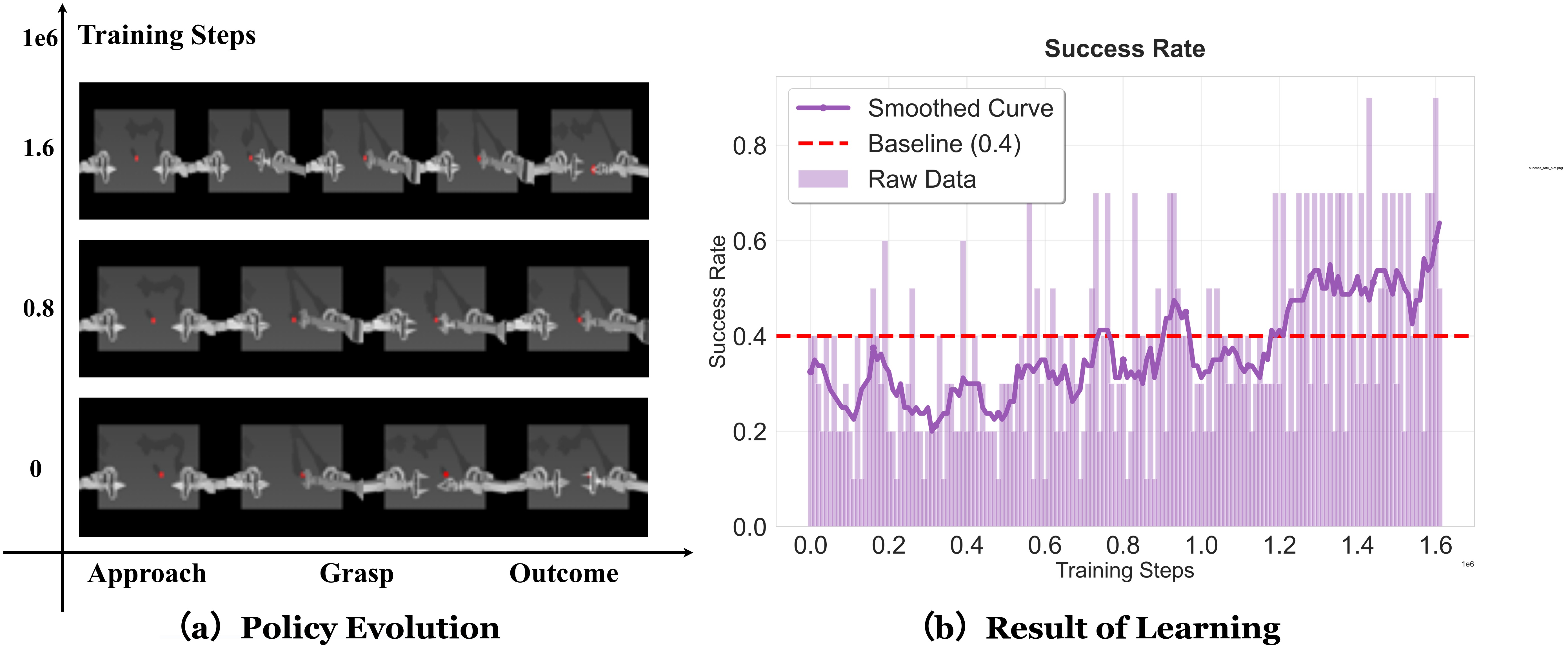
- 在LIBERO基准和ALOHA仿真任务中,FPO在稀疏奖励下相较于多种基线方法表现出一致的性能提升。
📝 摘要(中文)
视觉-语言-动作(VLA)模型如OpenVLA、Octo和$π_0$通过大规模示例展示了强大的泛化能力,但其性能仍受限于监督数据的质量和覆盖范围。强化学习(RL)为通过在线交互改进和微调VLA提供了有希望的路径。然而,传统的策略梯度方法在基于流匹配的模型中由于重要性采样过程的不可计算性而变得计算上不可行。为此,本文提出了流政策优化(FPO)算法,通过利用条件流匹配目标的每个样本变化重新构造重要性采样。此外,FPO通过集成结构感知的信用分配、剪切的替代目标、多步潜在探索和Q集成机制,实现了$π_0$模型的稳定和可扩展的在线强化微调。
🔬 方法详解
问题定义:本文旨在解决基于流匹配的视觉-语言-动作模型在强化学习中面临的计算复杂性问题,尤其是重要性采样的不可计算性限制了模型的在线微调能力。
核心思路:提出流政策优化(FPO)算法,通过利用每个样本在条件流匹配目标下的变化来重新构造重要性采样,从而提高策略更新的效率和稳定性。
技术框架:FPO的整体架构包括多个模块:结构感知的信用分配用于提高梯度效率,剪切的替代目标用于稳定优化,多步潜在探索鼓励多样化的策略更新,以及Q集成机制提供稳健的价值估计。
关键创新:FPO的核心创新在于其重新构造的重要性采样方法和集成的多种机制,使得在线强化学习过程中的策略更新更加高效和稳定。这与传统的策略梯度方法形成了鲜明对比。
关键设计:FPO在设计上采用了剪切的替代目标以防止梯度爆炸,利用多步潜在探索来增强策略的多样性,并通过Q集成机制来提高价值估计的鲁棒性。
🖼️ 关键图片

📊 实验亮点
在LIBERO基准和ALOHA仿真任务中,FPO相较于监督、偏好对齐、扩散基础、自动回归在线强化学习和$π_0$-FAST等基线方法,均表现出一致的性能提升,尤其在稀疏奖励环境下,展现了稳定的学习效果。
🎯 应用场景
该研究的潜在应用领域包括机器人控制、自动驾驶、智能助手等多模态交互系统。通过提升视觉-语言-动作模型的在线学习能力,能够实现更为灵活和智能的交互体验,推动相关领域的技术进步和应用落地。
📄 摘要(原文)
Vision-Language-Action (VLA) models such as OpenVLA, Octo, and $π_0$ have shown strong generalization by leveraging large-scale demonstrations, yet their performance is still fundamentally constrained by the quality and coverage of supervised data. Reinforcement learning (RL) provides a promising path for improving and fine-tuning VLAs through online interaction. However, conventional policy gradient methods are computationally infeasible in the context of flow-matching based models due to the intractability of the importance sampling process, which requires explicit computation of policy ratios. To overcome this limitation, we propose Flow Policy Optimization (FPO) algorithm, which reformulates importance sampling by leveraging per-sample changes in the conditional flow-matching objective. Furthermore, FPO achieves stable and scalable online reinforcement fine-tuning of the $π_0$ model by integrating structure-aware credit assignment to enhance gradient efficiency, clipped surrogate objectives to stabilize optimization, multi-step latent exploration to encourage diverse policy updates, and a Q-ensemble mechanism to provide robust value estimation. We evaluate FPO on the LIBERO benchmark and the ALOHA simulation task against supervised, preference-aligned, diffusion-based, autoregressive online RL, and $π_0$-FAST baselines, observing consistent improvements over the imitation prior and strong alternatives with stable learning under sparse rewards. In addition, ablation studies and analyses of the latent space dynamics further highlight the contributions of individual components within FPO, validating the effectiveness of the proposed computational modules and the stable convergence of the conditional flow-matching objective during online RL.