Structured Cooperative Multi-Agent Reinforcement Learning: a Bayesian Network Perspective
作者: Shahbaz P Qadri Syed, He Bai
分类: cs.MA, cs.LG, eess.SY, math.OC, stat.ML
发布日期: 2025-10-11
💡 一句话要点
提出基于贝叶斯网络的结构化合作多智能体强化学习方法,提升大规模系统效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 贝叶斯网络 值依赖集 去中心化训练 策略梯度 actor-critic 资源分配
📋 核心要点
- 现有MARL算法未能充分利用智能体间的耦合信息,导致在大规模系统中效率和可扩展性受限。
- 论文提出基于贝叶斯网络建模智能体间依赖关系,确定值依赖集,并设计部分去中心化训练执行范式。
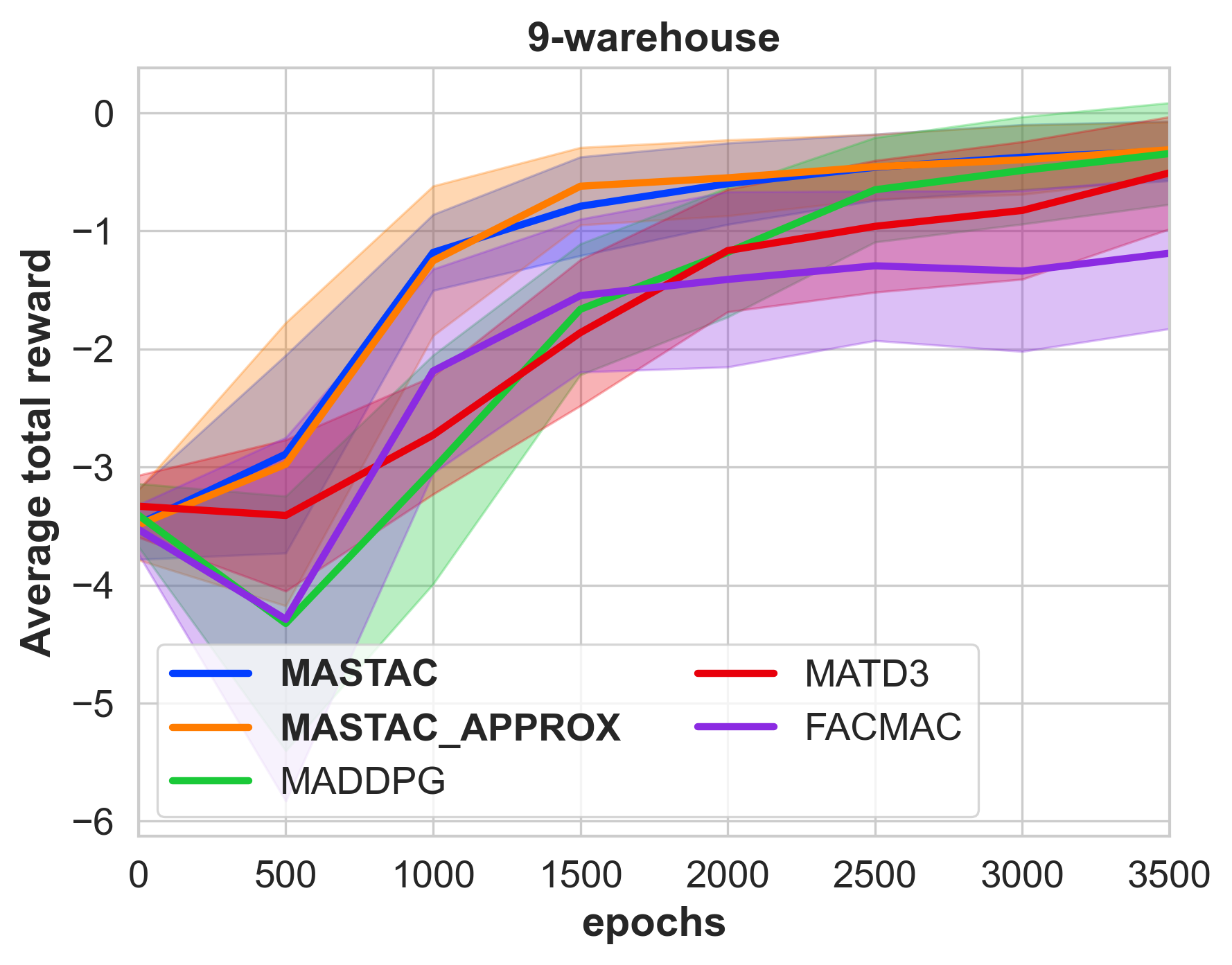
- 实验表明,该算法在多仓库资源分配和多区域温度控制等任务中,展现出更高的效率和可扩展性。
📝 摘要(中文)
多智能体强化学习(MARL)在实践中取得了成功,这推动了对大规模多智能体系统更高效和可扩展算法的研究。然而,现有的先进算法并没有充分利用智能体间的耦合信息来开发MARL算法。本文提出了一种系统的方法,利用智能体间耦合的结构进行有效的无模型强化学习。我们通过贝叶斯网络对合作MARL问题进行建模,并确定智能体的子集,称为值依赖集,每个智能体需要这些信息来准确估计其局部动作值函数。此外,我们提出了一种基于值依赖集的部分去中心化训练去中心化执行(P-DTDE)范式。我们从理论上证明了我们的P-DTDE策略梯度估计器的总方差小于中心化训练去中心化执行(CTDE)策略梯度估计器。我们推导了一个基于P-DTDE方案的多智能体策略梯度定理,并开发了一种可扩展的actor-critic算法。我们在多仓库资源分配和多区域温度控制的例子中证明了所提出算法的效率和可扩展性。对于密集的值依赖集,我们提出了一种基于贝叶斯网络截断的近似方案,并从经验上表明,对于具有大量智能体的应用,它比精确的值依赖集实现了更快的收敛。
🔬 方法详解
问题定义:论文旨在解决大规模合作多智能体强化学习中的效率和可扩展性问题。现有方法,如CTDE,虽然常用,但忽略了智能体之间的结构化依赖关系,导致训练效率低下,难以扩展到大量智能体的场景。
核心思路:论文的核心思路是利用贝叶斯网络对智能体之间的依赖关系进行建模,从而识别出每个智能体所需的最少信息集合(值依赖集)。通过只共享必要的信息,可以减少通信开销,提高学习效率。
技术框架:整体框架采用部分去中心化训练去中心化执行(P-DTDE)范式。训练阶段,每个智能体根据其值依赖集获取信息,更新策略;执行阶段,智能体仅根据本地观测和学习到的策略进行决策。该框架包含以下主要模块:1) 贝叶斯网络建模模块,用于表示智能体间的依赖关系;2) 值依赖集确定模块,用于识别每个智能体所需的信息;3) 基于P-DTDE的策略梯度更新模块,用于优化智能体策略。
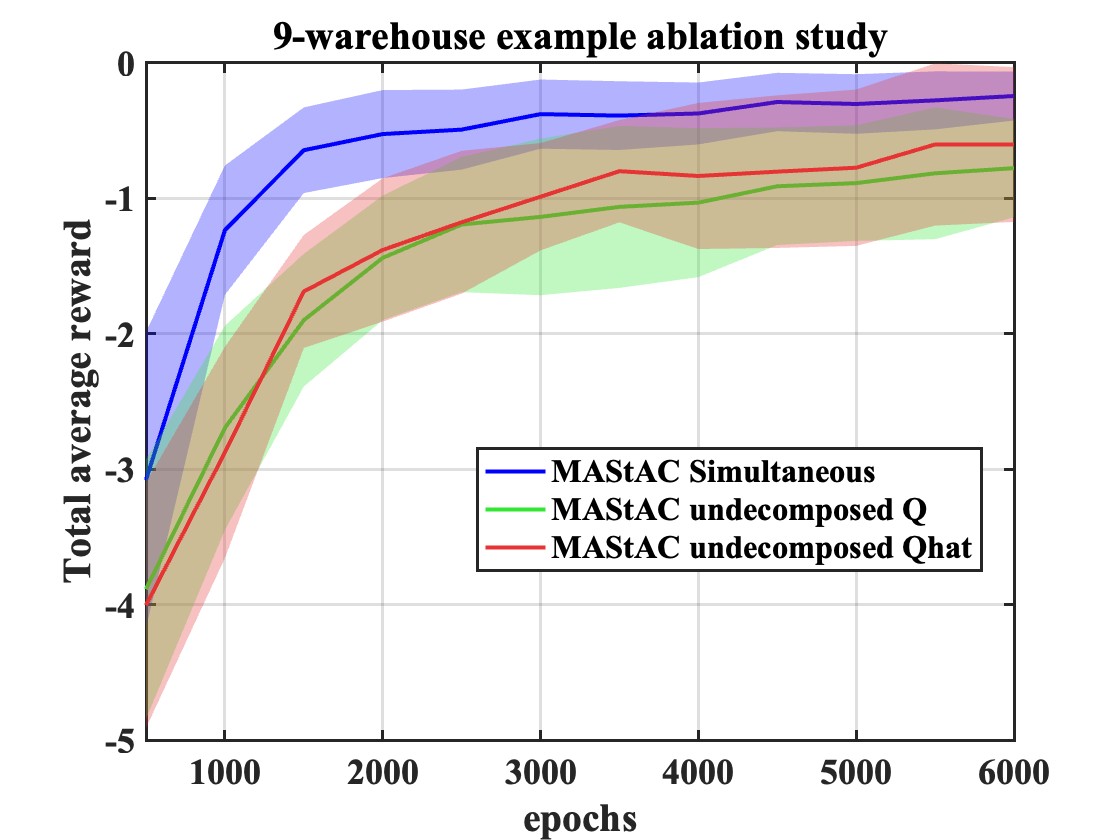
关键创新:最重要的技术创新在于利用贝叶斯网络对智能体间的依赖关系进行建模,并基于此提出了P-DTDE范式。与CTDE相比,P-DTDE减少了信息共享,降低了方差,提高了学习效率。此外,论文还提出了基于贝叶斯网络截断的近似方案,用于处理具有大量智能体的密集依赖场景。
关键设计:论文推导了基于P-DTDE的多智能体策略梯度定理,并设计了一种可扩展的actor-critic算法。具体而言,actor网络用于学习策略,critic网络用于评估值函数。损失函数的设计考虑了值依赖集的信息,使得策略更新更加高效。对于大规模场景,论文提出了贝叶斯网络截断方法,通过限制依赖关系的深度来降低计算复杂度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的算法在多仓库资源分配和多区域温度控制等任务中,相比于CTDE等基线方法,能够更快地收敛,并取得更好的性能。特别是在智能体数量较多的情况下,基于贝叶斯网络截断的近似方案能够显著提高学习效率,验证了算法的可扩展性。
🎯 应用场景
该研究成果可应用于各种大规模合作多智能体系统,如智能交通、机器人集群控制、分布式能源管理、以及多智能体博弈等领域。通过利用智能体间的结构化依赖关系,可以显著提高系统的效率和可扩展性,从而实现更优的资源分配和任务执行。
📄 摘要(原文)
The empirical success of multi-agent reinforcement learning (MARL) has motivated the search for more efficient and scalable algorithms for large scale multi-agent systems. However, existing state-of-the-art algorithms do not fully exploit inter-agent coupling information to develop MARL algorithms. In this paper, we propose a systematic approach to leverage structures in the inter-agent couplings for efficient model-free reinforcement learning. We model the cooperative MARL problem via a Bayesian network and characterize the subset of agents, termed as the value dependency set, whose information is required by each agent to estimate its local action value function exactly. Moreover, we propose a partially decentralized training decentralized execution (P-DTDE) paradigm based on the value dependency set. We theoretically establish that the total variance of our P-DTDE policy gradient estimator is less than the centralized training decentralized execution (CTDE) policy gradient estimator. We derive a multi-agent policy gradient theorem based on the P-DTDE scheme and develop a scalable actor-critic algorithm. We demonstrate the efficiency and scalability of the proposed algorithm on multi-warehouse resource allocation and multi-zone temperature control examples. For dense value dependency sets, we propose an approximation scheme based on truncation of the Bayesian network and empirically show that it achieves a faster convergence than the exact value dependence set for applications with a large number of agents.