DEAS: DEtached value learning with Action Sequence for Scalable Offline RL
作者: Changyeon Kim, Haeone Lee, Younggyo Seo, Kimin Lee, Yuke Zhu
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-09
备注: Project website: https://changyeon.site/deas
💡 一句话要点
DEAS:通过动作序列解耦价值学习,提升离线强化学习的可扩展性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离线强化学习 动作序列 解耦价值学习 长时序决策 机器人操作
📋 核心要点
- 现有离线强化学习方法在处理复杂、长时序决策任务时面临挑战,难以有效利用离线数据。
- DEAS通过引入动作序列进行价值学习,利用时序扩展动作的丰富信息,并结合解耦价值学习来抑制价值高估。
- 实验表明,DEAS在长时序任务上显著优于现有方法,并能提升视觉-语言-动作模型在机器人任务中的性能。
📝 摘要(中文)
离线强化学习为训练智能体提供了一种无需昂贵在线交互的有效范式。然而,现有方法在复杂、长时序决策任务中仍然面临挑战。本文提出了一种简单而有效的离线强化学习框架——基于动作序列的解耦价值学习(DEAS),该框架利用动作序列进行价值学习。相比于单步动作,时序扩展动作提供了更丰富的信息,并且可以通过半马尔可夫决策过程Q学习的选项框架进行解释,从而通过一次考虑更长的序列来减少有效的规划范围。然而,在Actor-Critic算法中直接采用这种序列会引入过度的价值高估,我们通过解耦价值学习来解决这个问题,该方法将价值估计导向离线数据集中实现高回报的分布内动作。实验表明,DEAS在OGBench的复杂、长时序任务上始终优于基线方法,并且可以应用于增强预测动作序列的大规模视觉-语言-动作模型的性能,从而显著提高RoboCasa厨房模拟任务和真实世界操作任务的性能。
🔬 方法详解
问题定义:离线强化学习旨在利用静态数据集训练智能体,避免在线探索。然而,在长时序任务中,现有方法容易产生价值高估,导致策略性能不佳。尤其是在复杂环境中,单步动作的价值评估难以捕捉长期依赖关系,限制了学习效率和泛化能力。
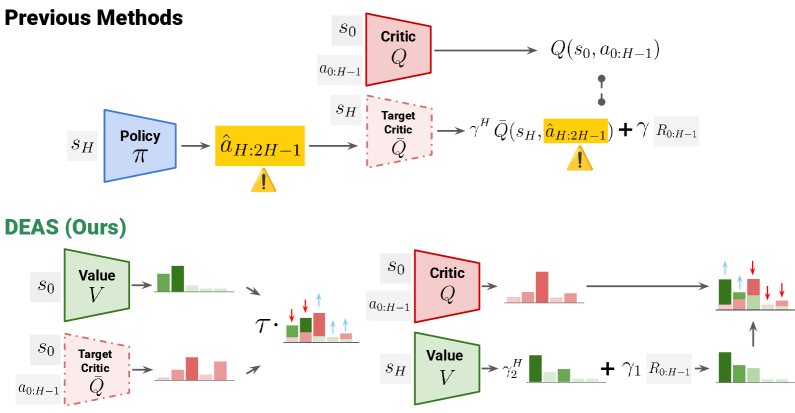
核心思路:DEAS的核心思想是利用动作序列作为基本操作单元,将单步决策扩展为序列决策。通过学习动作序列的价值,模型可以更好地理解长期行为的影响,从而减少规划范围,提高学习效率。同时,采用解耦价值学习来抑制由于动作序列引入的价值高估问题。
技术框架:DEAS采用Actor-Critic框架,主要包含以下模块:1) 动作序列生成器:用于从离线数据集中提取或生成动作序列。2) Critic网络:用于评估动作序列的价值,采用解耦价值学习策略,将价值估计导向数据集中高回报的动作。3) Actor网络:用于生成策略,选择最优的动作序列。整体流程为:从状态s出发,Actor网络生成动作序列,Critic网络评估该序列的价值,然后利用解耦价值学习更新Actor和Critic网络。
关键创新:DEAS的关键创新在于:1) 引入动作序列进行价值学习,有效利用了时序信息,减少了规划范围。2) 提出解耦价值学习,解决了动作序列带来的价值高估问题,提高了学习的稳定性。3) 将动作序列与选项框架联系起来,为理解和解释学习到的策略提供了理论基础。
关键设计:DEAS的关键设计包括:1) 动作序列的长度选择:需要根据任务的复杂度和数据集的特点进行调整。2) 解耦价值学习的实现方式:可以通过引入额外的约束或正则化项来实现,以限制价值的过度估计。3) Actor和Critic网络的结构设计:可以采用常见的神经网络结构,如Transformer或LSTM,以捕捉动作序列中的依赖关系。
🖼️ 关键图片


📊 实验亮点
DEAS在OGBench的复杂长时序任务上取得了显著的性能提升,超越了现有基线方法。在RoboCasa厨房模拟任务和真实世界操作任务中,DEAS显著提升了视觉-语言-动作模型的性能,验证了其在实际应用中的有效性。具体性能数据在论文中进行了详细展示。
🎯 应用场景
DEAS具有广泛的应用前景,例如机器人操作、游戏AI、自动驾驶等领域。它可以用于训练智能体完成复杂的任务,例如在厨房环境中进行物体操作,或者在游戏中制定长期战略。此外,DEAS还可以应用于视觉-语言-动作模型,提升其在真实世界中的表现,实现更智能的人机交互。
📄 摘要(原文)
Offline reinforcement learning (RL) presents an attractive paradigm for training intelligent agents without expensive online interactions. However, current approaches still struggle with complex, long-horizon sequential decision making. In this work, we introduce DEtached value learning with Action Sequence (DEAS), a simple yet effective offline RL framework that leverages action sequences for value learning. These temporally extended actions provide richer information than single-step actions and can be interpreted through the options framework via semi-Markov decision process Q-learning, enabling reduction of the effective planning horizon by considering longer sequences at once. However, directly adopting such sequences in actor-critic algorithms introduces excessive value overestimation, which we address through detached value learning that steers value estimates toward in-distribution actions that achieve high return in the offline dataset. We demonstrate that DEAS consistently outperforms baselines on complex, long-horizon tasks from OGBench and can be applied to enhance the performance of large-scale Vision-Language-Action models that predict action sequences, significantly boosting performance in both RoboCasa Kitchen simulation tasks and real-world manipulation tasks.